Updated March 18, 2023

What is Kafka?
The open-source software platform developed by LinkedIn to handle real-time data is called Kafka. It publishes and subscribes to a stream of records and also is used for fault-tolerant storage. The applications are designed to process the records of timing and usage. Log partitions of different servers are replicated in Kafka. It stores, reads and analyses the streaming data where developers and users contribute the coding updates. It is used for messaging, website activity tracking, log aggregation and commit logs. It can be used as a database, but it does not possess a data model or indexes.
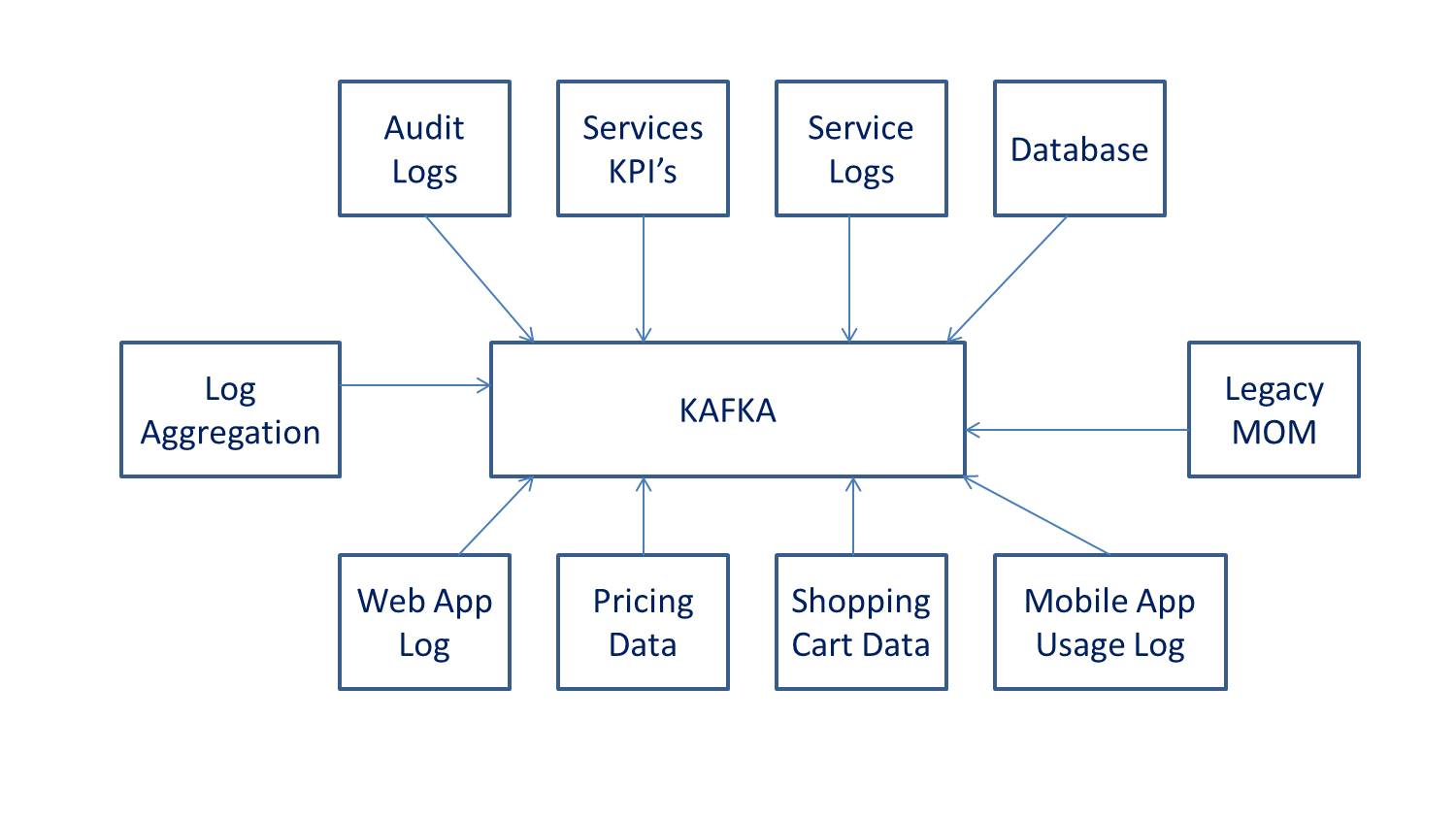
Understanding Kafka
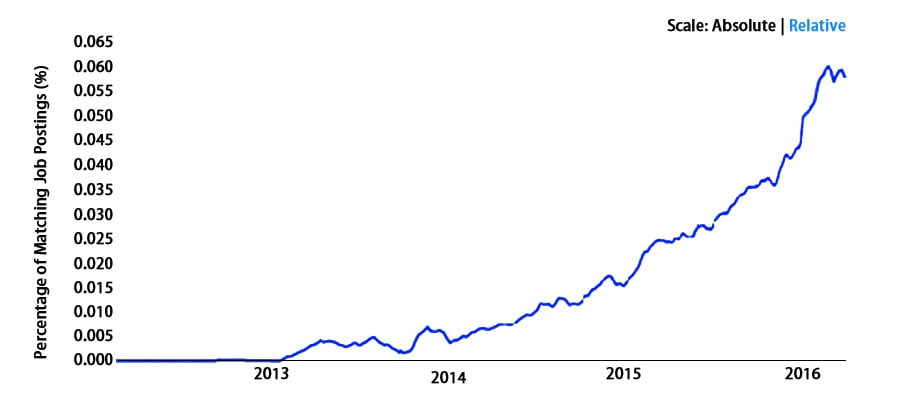
Its growth is exploding exponentially. Let’s see some facts and stats to underline our thought better. It enjoys the prime preference by more than one-third of the Fortune 500 across the globe. This distribution is shared by travel business companies, telecom giants, banks, and several others. LinkedIn, Microsoft, and Netflix process four-comma messages a day with Kafka (nearly equals to 1,000,000,000,000).
It is used for real-time data streams, collecting big data, or doing real-time analysis (or both). It is used with in-memory microservices to provide durability, and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems.
How does Kafka Work so Easily?
Driven by simplicity would be the right way to define the performance. It is easy to figure out how Kafka works with such ease from its set-up and use. This increased performance in behavior is dedicated to its stability, its provision to reliable durability, with its flexible inbuilt capability to publish or subscribe or queue maintenance. This is crucial to have if you need to deal with N – numbers of clients group, if you have to show a robust replication in the market, to provide your customers with a consistent approach (i.e. Kafka topic partition). Kafka’s crucial behavior that set it apart from its competitors is its compatibility with systems with data streams – its process enables these systems to be aggregate, transform, and load other stores for convenience working. “All the above-mentioned facts would not be possible if Kafka was slow”. Its exceptional performance makes this possible.
With further addition to ease of Kafka working, we have to go to “OS Level”.
Let’s find how things work for Kafka at the OS level:
- It relies on OS kernels for moving the data more quickly and works on the principle of zero-copy.
- It allows data records to batch into chunks which can be seen from the file system (a.k.a Kafka topic log) to consumers.
- The facility to batch data gives an efficient data compression with I/O latency reduction.
- It has the ability to scale horizontally via sharding. It can shard a title log into hundreds of partitions to thousands. This allows it to handle the massive workload easily.
What can you do with Kafka?
If your company plays with huge sets of data regularly, you need Kafka. There is a long list of companies using it.
- LinkedIn uses it to track data and operational metrics.
- Twitter to provide stream processing infrastructures.
There is a long list of companies from Uber to Spotify and Goldman Sachs to Cisco.
Advantages
Given below are the advantages mentioned:
- High Throughput: It can easily handle a large volume of data when generating at high velocity is an exceptional advantage in Kafka’s favour. This application lacks huge hardware to support message throughput at a frequency of thousands of messages per second.
- Low Latency: Low latency handling this high volume message generation.
- Fault Tolerance: This feature is handy; it has an inherent capability to be restricted by a node built into a cluster.
- Durable: It is very durable in its operation and is so why many MNC’s are preferring to use Kafka. Talking of durability in operations, the messages cannot get lost in the long term.
Required Skills
There is no special requirement for being a Kafka professional.
But we have underlined some streams and professionals:
- Developers who willingly want to make a career in Big Datastream and want to accelerate their career.
- Testing professionals have a good scope in Kafka in terms of Queuing and Messaging systems.
- Architects – since everything needs some framework and this framework can be updated from time to time. Big Data architects would find Kafka a good career investment.
- A project Manager is needed if the above professional is there for better management of the resources. So, higher positions are also available for the management professionals in the field of Kafka.
Why Use Kafka?
For the purpose of data tracking and manipulating them as per the business need, it is preferred worldwide. It gives the possibility to stream data in real-time with real-time analytics. It is fast, scalable, and durable, and designed as fault tolerance. There are multiple use cases present over the web where you can see why JMS, RabbitMQ, and AMQP are not even considered to work with as the need is to operate huge volumes and responsiveness.
It has high throughput, reliable setup with replication characteristics, making it a preferable choice to work on IoT sensors.
Compatibility is another reason to use it and made it acceptable worldwide. It can be easily configured to work with the below-listed application. This combination is vital for many companies to grow business and survive (as it saves time and money).
- Flume
- Spark Streaming
- HBase
- Spark for real-time ingestion, processing, and analysis of data.
- It is used to feeding Hadoop BigData.
Scope
It is doing great all across the globe. Well, we are not saying this rather stats.
Salary Stats for Kafka Professionals – PayScale
- Software Engineer – $109,825
- Data Engineer – $109,580
- Developers – $81,182
- Senior Data Engineer – $ 127, 836
Conclusion
At present, Kafka has become the de-facto standard for real-time data analytics with the highest precision in microseconds. We have presented our insights in terms of data and details in support of Kafka technologies. Several big companies are harnessing data daily; in doing this, they need professionals to harness these huge data sets. With Kafka, one can be assured to lead their career in BigData analytics.
Recommended Articles
This has been a guide to What is Kafka? Here we discussed the working, scope, career growth, and advantages of Kafka. You can also go through our other suggested articles to learn more –
