Updated March 23, 2023
Introduction to Yarn in Hadoop
The technology used for job scheduling and resource management and one of the main components in Hadoop is called Yarn. Yarn stands for Yet Another Resource Negotiator though it is called as Yarn by the developers. Yarn was previously called MapReduce2 and Nextgen MapReduce. This enables Hadoop to support different processing types. It runs interactive queries, streaming data and real time applications. Also it supports broader range of different applications. Yarn combines central resource manager with different containers. It can combine the resources dynamically to different applications and the operations are monitored well.
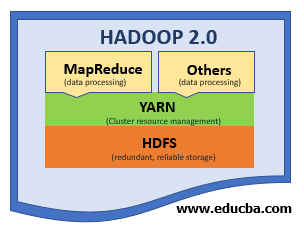
In the initial days of Hadoop, its 2 major components HDFS and MapReduce were driven by batch processing. The JobTracker had to maintain the task of scheduling and resource management. This often led to problems such as non-utilization of the resources or job failure. Since the processing was done in batches the wait time to obtain the results was often prolonged. The need to process real-time data with more speed and accuracy leads to the creation of Yarn.
What is Yarn in Hadoop?
Yarn is one of the major components of Hadoop that allocates and manages the resources and keep all things working as they should. Yarn was initially named MapReduce 2 since it powered up the MapReduce of Hadoop 1.0 by addressing its downsides and enabling the Hadoop ecosystem to perform well for the modern challenges. Yarn was introduced as a layer that separates the resource management layer and the processing layer.
Yarn is the parallel processing framework for implementing distributed computing clusters that processes huge amounts of data over multiple compute nodes. Hadoop Yarn allows for a compute job to be segmented into hundreds and thousands of tasks.
Architecture of Yarn
In addition to resource management, Yarn also offers job scheduling. The concept of Yarn is to have separate functions to manage parallel processing.
The major components responsible for all the YARN operations are as follows:
- Resource Manager
- Node Manager
- Application Master
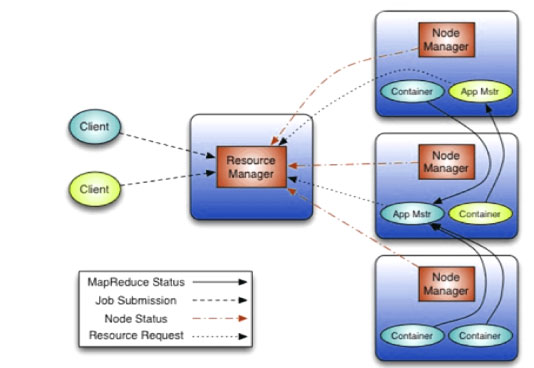
Img Src: Cloudera
Yarn uses master servers and data servers. There is only one master server per cluster. It runs the resource manager daemon. There are many data servers in the cluster, each one runs on its own Node Manager daemon and the application master manager as required.
1. Resource Manager
Resource Manager allocates the cluster resources. This is made possible by a scheduler for scheduling the required jobs and an ApplicationManager for accepting the job submissions and executing the necessary Application Master. The Resource Manager is a single daemon but has unique functionalities like:
- Resource Management: The Resource Manager interacts with the Node Manager to keep an inventory of cluster-wide resources such as RAM, CPU and Network usage. It manages the availability and allocation of the resources thus gaining the ultimate authority of managing the resources.
- Scheduling Management: This is responsible for only allocating resources as requested by various Application Masters. It does not monitor or track the status of the job.
- Application Management: This is the most important responsibility of the Resource Manager. It ensures the start-up and job completion. It accepts the job and assigns it to an Application Master on a data server. In addition to this, it also monitors the activity and status of the Application Master and provides a restart in case of failure of Application Master.
- Containers in Hadoop: Hadoop v2.0 has enhanced parallel processing with the addition of containers. Containers are the abstract notion that supports multi-tenancy on a data node. It is a way to define requirements for memory, CPU and network allocation by dividing the resources on the data server into a container. In doing so, the data server can host multiple compute jobs by hosting multiple containers.
- Resource Containers: The Resource Manager is responsible for scheduling resources by allocating containers. This is done in accordance with the input provided by the client, cluster capacity, queues and overall prioritization of resources on the cluster. Resource Manager uses an algorithm to allocate the contains, a general rule is to start a container on the same node as the data required by the compute job for easy data locality.
2. Node Manager
The primary goal of the Node Manager is memory management. Node Manager tracks the usage and status of the cluster inventories such as CPU, memory, and network on the local data server and reports the status regularly to the Resource Manager. A Node Manager daemon is assigned to every single data server. This holds the parallel programming in place.
3. Application Master
Application Master is responsible for execution in parallel computing jobs. Its daemon is accountable for executing the job, monitoring the job for error, and completing the computer jobs. These daemons are started by the resource manager at the start of a job. Each compute job has an Application Master running on one of the data servers. The Application Master requests the data locality from the namenode of the master server. It then negotiates with the scheduler function in the Resource Manager for the containers of resources throughout the cluster.
For the execution of the job requested by the client, the Application Master assigns a Mapper container to the negotiated data servers, monitors the containers and when all the mapper containers have fulfilled their tasks, the Application Master will start the container for the reducer. The application master reports the job status both to the Resource Manager and the client.
Key Features of Yarn
- Multi-tenancy: Yarn allows multiple engine access and fulfills the requirement for a real-time system for knowing where the data is located and for managing the movement of that data within the framework for dispatching compute jobs to run on the right data at the right location.
- Sharing Resources: Yarn ensures there is no dependency between the compute jobs. Each compute job is run on its own node and does not share its allocated resources. Each job is responsible for its own assigned work.
- Cluster Utilization: Yarn optimizes the cluster by utilizing and allocating its resources in a dynamic manner.
- Fault Tolerance: Yarn is highly fault-tolerant. It allows the rescheduling of the failed to compute jobs without any implications for the final output.
- Scalability: Yarn focuses mainly on scheduling the resources. This creates a pathway for expanding the data nodes and increasing the processing capacity.
- Compatibility: The jobs that were working in MapReduce v1 can be easily migrated to higher versions of Hadoop with ease ensuring high compatibility of Yarn.
Conclusion
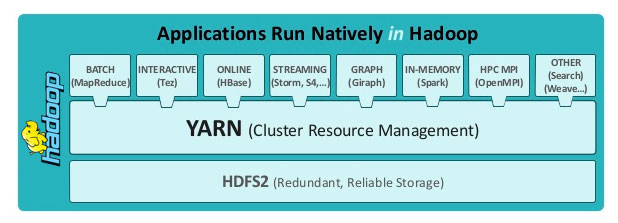
The idea behind the creation of Yarn was to detach the resource allocation and job scheduling from the MapReduce engine. Thus yarn forms a middle layer between HDFS(storage system) and MapReduce(processing engine) for the allocation and management of cluster resources. The advent of Yarn opened the Hadoop ecosystem to many possibilities. The yarn was successful in overcoming the limitations of MapReduce v1 and providing a better, flexible, optimized and efficient backbone for execution engines such as Spark, Storm, Solr, and Tez.
Recommended Articles
This has been a guide to What is Yarn in Hadoop? Here we discuss the introduction, architecture and key features of yarn. You may also have a look at the following articles to learn more –
