Updated March 23, 2023

What is Hadoop Versions?
Hadoop is a Software which on an open-source framework storing data using a distributed network rather than a centralized one thereby processing the data in a parallel transition. This enables Hadoop to act as one of the most reliable batch processing engine and layered storage and resource management system. As the data beings stored and processed increases in its complexity so do Hadoop where the developers bring out various versions to address the issues (bug fixes) and simplify the complex data processes. The updates are automatically implemented as Hadoop development follows the trunk (base code) – branch (fix)model. Hadoop has two versions: a) Hadoop 1.x (Version 1) and b) Hadoop 2 (Version 2)
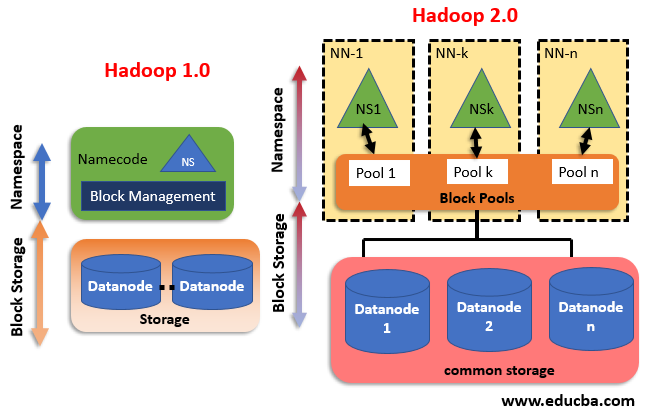
Implementing Two Hadoop Versions
Below are the two Hadoop Versions:
- Hadoop 1.x (Version 1)
- Hadoop 2 (Version 2)
1. Hadoop 1.x
Below are the Components of Hadoop 1.x
1. The Hadoop Common Module is a jar file which acts as the base API on top of which all the other components work.
2. Version one being the first one to come in existence is rock solid and has got no new updates
3. It has a limitation on the scaling nodes with just a maximum of 4000 nodes for each cluster
4. The functionality is limited utilizing the slot concept, i.e., the slots are capable of running a map task or a reduce task.
5. The next component if the Hadoop Distributed File System commonly known as HDFS, which plays the role of a distributed storage system that is designed to cater to large data, with a block size of 64 MegaBytes (64MB) for supporting the architecture. It is further divided into two components:

- Name Node which is used to store metadata about the Data node, placed with the Master Node. They contain details like the details about the slave note, indexing and their respective locations along with timestamps for timelining.
- Data Nodes used for storage of data related to the applications in use placed in the Slave Nodes.
6. Hadoop 1 uses Map Reduce (MR) data processing model It is not capable of supporting other non-MR tools.
MR has two components:
- Job Tracker is used to assigning or reassigning task-related (in case scenario fails or shutdown) to MapReduce to an application called task tracker is located in the node clusters. It additionally maintains a log about the status of the task tracker.
- The Task Tracker is responsible for executing the functions which have been allocated by the job tracker and sensor cross the status report of those task to the job tracker.
7. The network of the cluster is formed by organizing the master node and slave nodes. Which of this cluster is further divided into tracks which contain a set of commodity computers or nodes.
8. Whenever a large storage operation for big data set is is received by the Hadoop system, the data is divided into decipherable and organized blocks that are distributed into different nodes.
2. Hadoop Version 2
Version 2 for Hadoop was released to provide improvements over the lags which the users faced with version 1. Let’s throw some light over the improvements that the new version provides:
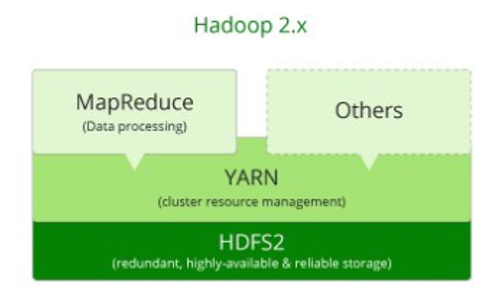
- HDFS Federation which has improved to provide for horizontal scalability for the name node. Moreover, the namenode was available for a single point of failure only, it is available on varied points. This is going to the Hadoop stat has been increased to include the stacks such as Hive, Pig, which make this tap well equipped enabling me to handle failures pertaining to NameNode.
- YARN stands for Yey Another Resource Network has been improved with the new ability to process data in the larger term that is petabyte and terabyte to make it available for the HDFS while using the applications which are not MapReduce based. These include applications like MPI and GIRAPH.
- Version – 2.7.x Released on 31st May 2018: The update focused to provide for two major functionalities that are providing for your application and providing for a global resource manager, thereby improving its overall utility and versatility, increasing scalability up to 10000 nodes for each cluster.
- Version 2.8.x – Released in September 2018: The updated provided improvements include the capacity scheduler which is designed to provide multi-tenancy support for processing data over Hadoop and it has been made to be accessible for window uses so that there is an increase in the rate of adoption for the software across the industry for dealing with problems related to big data.
Version 3
Below is the latest running Hadoop Updated Version
Version 3.1.x – released on 21 October 2019: This update enables Hadoop to be utilized as a platform to serve a big chunk of Data Analytics Functions and utilities to be performed over event processing alongside using real-time operations give a better result.
- It has now improved feature work on the container concept which enables had to perform generic which were earlier not possible with version 1.
- The latest version 3.2.1 released on 22nd September 2019 addresses issues of non-functionality (in terms of support) of data nodes for multi-Tenancy, limitation to you only MapReduce processing and the biggest problem than needed for an alternate data storage which is needed for the real-time processing and graphical analysis.
- The ever-increasing Avalanche of data and Big Data Analytics pertaining to just business standing at an estimated 169 billion dollars (USD), the predicted growth to 274 billion dollars by 2022, the market seems to be growing ecstatically.
- This all the more calls for a system that is integrable in its functioning for the abandoned Utah which is growing day by day. Hadoop app great to store, process and access the great solution which works to store process and access this heterogeneous set of data which can be unstructured/ structure in an organized manner.
- With the feature of constant updates which act as tools to rectify the bugs that developers say while using Hadoop, and the improved versions increase the scope of application and improve the dimension and flexibility of using Hadoop, increases the chances of it is the next biggest to for all functions related to big data processing and Analytics.
Recommended Articles
This is a guide to Hadoop Versions. Here we discuss the Hadoop 2 version in detail also knowing the longest and current running version. You can also go through our other related articles to learn more –
