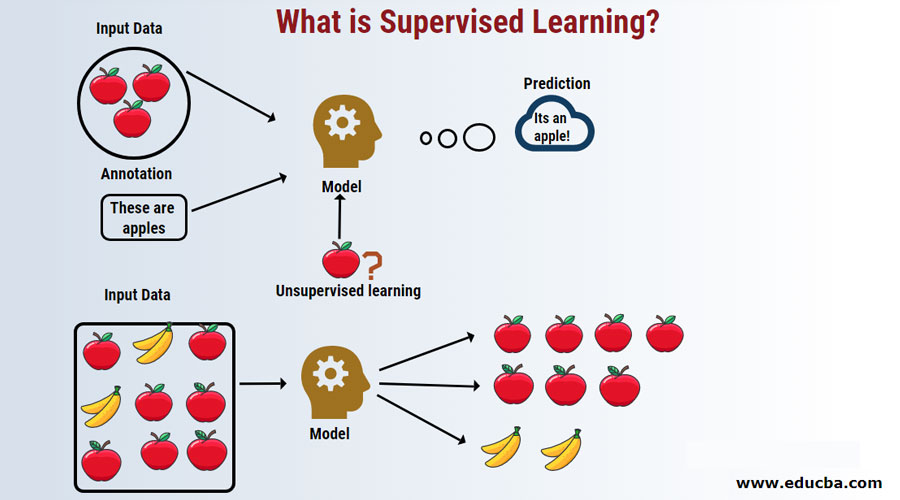
Introduction to Supervised Learning
Supervised Learning is a category of machine learning algorithms based on the labeled data set. This category of algorithms achieves predictive analytics, where the outcome, known as the dependent variable, depends on the value of independent data variables. These algorithms are based on the training dataset and improve through iterations. There are mainly two supervised learning categories, regression, and classification. Several real-world scenarios implement it, such as predicting sales reviews for the next quarter in the business for a particular product for a retail organization.
Working on Supervised Machine Learning
Let us understand supervised machine learning with the help of an example. Let’s say we have a fruit basket filled with different species of fruits. Our job is to categorize fruits based on their category.
In our case, we have considered four types of fruits: Apples, Bananas, Grapes, and Oranges.
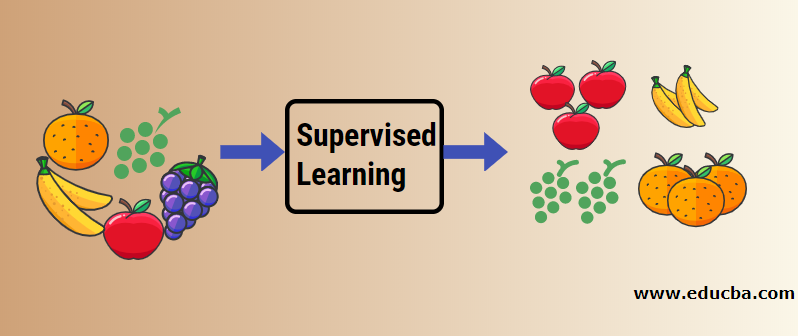
Now we will try to mention some of the unique characteristics of these fruits which make them unique.
|
Sr. No |
Size | Color | Shape |
First Name |
|
1 |
Small | Green | Round to oval, Bunch shape cylindrical |
Grape |
|
2 |
Big | Red | Rounded shape with a depression at the top |
Apple |
|
3 |
Big | Yellow | Long curving cylinder |
Banana |
| 4 | Big | Orange | Rounded shape |
Orange |
Now let us say that you have picked up a fruit from the fruit basket, you looked at its features, e.g., its shape, size, and color, for instance, and then you deduce that the color of this fruit is red, the size if big, the shape is rounded shape with a depression at the top; hence it is an apple.
- Likewise, you do the same for all other remaining fruits as well.
- The rightmost column (“Fruit Name”) is the response variable.
- This is how we formulate a supervised learning model; now, it will be quite easy for anybody new (Let’s say, a robot or an alien) with given properties to easily group the same type of fruits together.
Types of Supervised Machine Learning Algorithm
Let us see different types of machine learning algorithms:
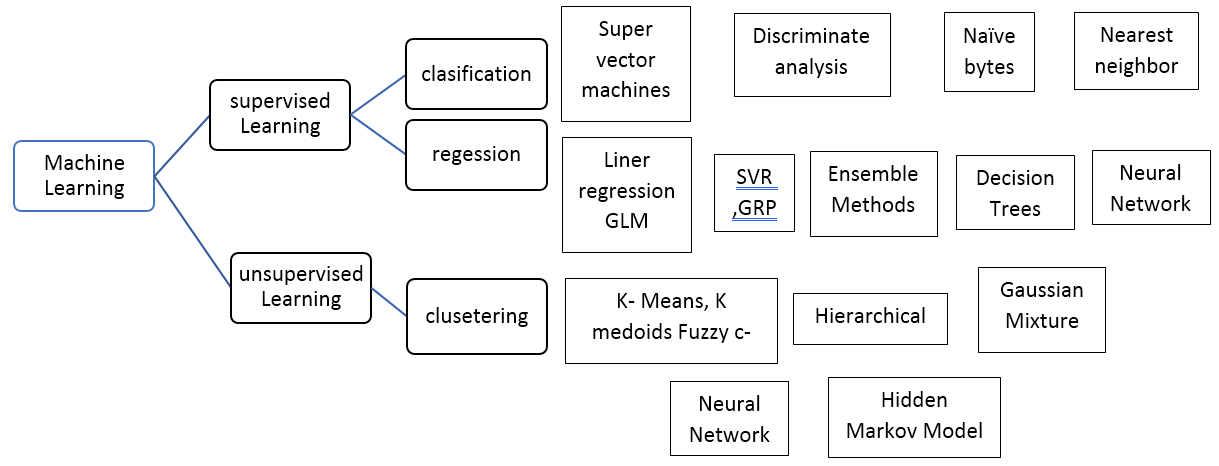
Regression
People use regression to predict a single-value output using the training data set. They refer to the output value as the dependent variable, while the inputs are the independent variables.
We have different types of regression in Supervised Learning.
For example:
- Linear Regression: Here, we have only one independent variable to predict the output, i.e., the dependent variable.
- Multiple Regression: Here, we have more than one independent variable to predict the output, i.e., the dependent variable.
- Polynomial Regression: The graph between the dependent and independent variables follows a polynomial function. E.g., at first, memory increases with age, then it reaches a threshold at a certain age, and then it starts decreasing as we turn old.
Classification
The classification of supervised learning algorithms is used to group similar objects into unique classes.
- Binary classification: If the algorithm tries to group 2 distinct groups of classes, then it is called binary classification.
- Multiclass classification: If the algorithm tries to group objects into more than 2 groups, it is called multiclass classification.
- Strength: Classification algorithms usually perform very well.
- Drawbacks: Prone to overfitting and might be unconstrained. For Example – Email Spam classifier.
- Logistic regression/classification: When the Y variable is a binary categorical (i.e., 0 or 1), we use Logistic regression for the prediction. For Example – Predict whether a given credit card transaction is fraud.
- Naive bayes classifiers: The Naïve Bayes classifier is based on the Bayesian theorem. This algorithm typically performs best when the dimensionality of the inputs is high. It consists of acyclic graphs with one parent and many children nodes. The child nodes are independent of each other.
- Decision trees: A decision tree is a tree chart-like structure that consists of an internal node (attribute test), a branch that denotes the outcome of the test, and the leaf nodes, representing the distribution of classes. The root node is the topmost node. Many practitioners widely use this technique for classification purposes.
- Support vector machine: A support vector machine or an SVM that does the classification job by finding the hyperplane, which should maximize the margin between 2 classes. These SVM machines are connected to the kernel functions. Fields, where SVMs are extensively used are biometrics, pattern recognition, etc.
Advantages
Below are some of the advantages of supervised machine learning models:
- User experiences can optimize the performance of models.
- It produces outputs using previous experience and also allows you to collect data.
- Supervised machine learning algorithms can be used for implementing several real-world problems.
Disadvantages
The following are the disadvantages given:
- Training supervised machine learning models may take longer if the dataset is bigger.
- The classification of big data sometimes poses a bigger challenge.
- One may have to deal with the problem of overfitting.
- We need many good examples if we want the model to perform well while training the classifier.
Good Practices while Building Learning Models
The following are the good practices while building machine Models:
- Before making any good machine learning model, the process of preprocessing data must be performed.
- We must decide the algorithm that would be best suited for a given problem.
- We must decide what data type will be used for the training set.
- Needs to decide on the structure of the algorithm and function.
Recommended Articles
This is a guide to What is Supervised Learning? Here we discussed the concepts, how it works, types, advantages, and disadvantages of supervised Learning. You can also go through our other suggested articles to learn more –
