
Introduction to Linux
RAID is an acronym of “Redundant Array of Inexpensive Disks” and now a day it is also known as “Redundant Array of Independent Drives”. It’s basically, a collection of disks in a pool to make a logical volume. It’s basically a way of saving or storing the same data in multiple hard disks to keep our data protected even in case of disk failure.
RAID is a method to combine multiple partitions in different disks into one large virtual storage or device which is also known as a RAID array.
Understanding RAID in Linux
RAID contains a group or a set of Arrays (set of disks). A combination of drives makes a group of disks to form a RAID array or a set of RAID which can be a minimum of 2 disks connected to a RAID controller and making a logical volume or more, it can be a combination of more drives in a group. However, only one RAID level can be applied to in a disk group. RAID is usually used when we need a better performance of the system in terms of data storage & accessibility. The performance of the RAID level may differ depending upon the configuration or setup which we call as RAID level in terms of data fault tolerance & high availability.
How does RAID in Linux make working so easy?
To make the RAID working easily in Linux, the tool called MDADM is used. MDADM is basically a command-line system that allows for easy and quick manipulation of the RAID devices. However, this software may not come with the most distributions by default. We may need to install it manually sometimes if we want to use the same. MDADM is used to manage and monitor the software RAID devices which are placed in modern GNU or Linux distributions instead of older RAID utilities for eg. raidtools or raidtools2.
What can you do with RAID in Linux?
Using RAID in Linux, we can store and manage our data in multiple ways. It helps us to keep our data safe, reliable, fast accessing, and also in a replicated way so that even some or one of the drives gets failed anyhow then also the system will still keep running without any impact in the process.
Working with RAID in Linux
RAID in Linux works in multiple ways (configurations) called as Levels such as Concatenated (Linear), Disk Striping (RAID Level 0), Disk Mirroring (RAID Level 1), Disk Parity (RAID Level 4), Disk Redundant (RAID Level 5), etc. RAID works by storing the data on multiple disks and allows input/output i.e., I/O operations in a balanced way considering the performance improvement. Since RAID uses multiple disks so it increases the mean time between failures (MTBF) and storing the data redundantly also at the same time it increases the fault tolerance.
In the Operating System (OS), the RAID arrays appear as a single logical hard disk. And RAID usually uses the techniques of disk mirroring or disk striping where mirroring copies the identical data onto more than single drive and striping partitions each drive’s storing space into multiple units ranging from a sector of 512 bytes upto several megabytes and the stripes of all the disks are usually interleaved and addressed in an ordered manner.
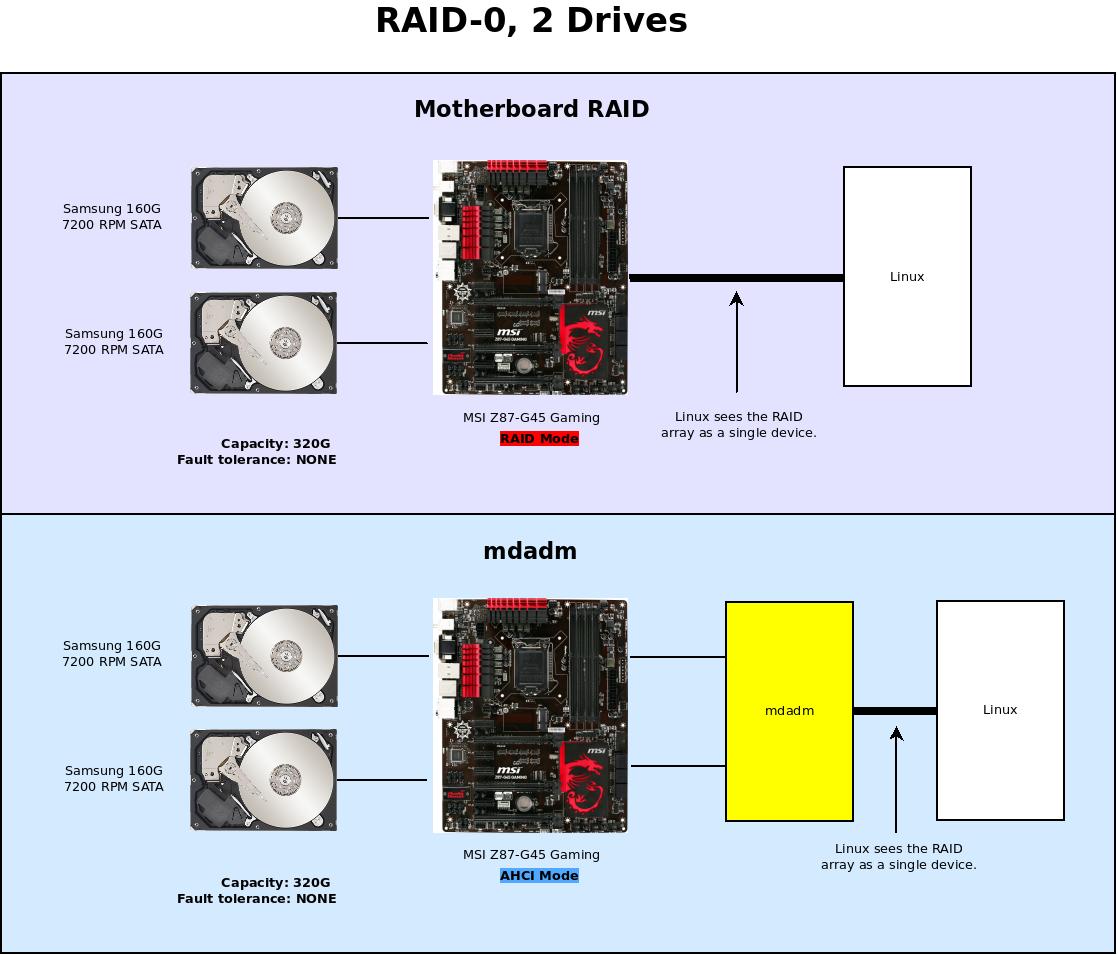
For instance, in a single user system where large records eg. Medical or any other scientific data like images are stored; the stripes are usually set up as smaller as possible (eg. 512 bytes) so that the single records can span all the disks and can be accessed as quickly as possible by reading all the disks at the same time. In a multiuser system, we can achieve improved performance by establishing a wide stripe that can hold the usual or max size data and this allows overlapped disk I/O across the drives. The good thing in RAID in Linux is that we can combine Disk Mirroring and Disk Striping together on an array that is used in RAID 01 and RAID 10.
Advantages
There are many advantages of implementing RAID in Linux with different levels. However, the different levels of RAID will be decided and implemented by the system administrator based on the ITBM application requirement. Basic advantages are:
- Redundancy – If any disk fails then other disks have the same data to prevent data loss.
- Performance – Overall data transfer rate can be improved by writing data on more than one disk.
- Convenience – It is easier to set up RAID and the space from different physical disks can be addressed even though they were in a single device.
Required Skills
The skills or knowledge we acquire is good as we can. However, we are about to discuss the basic skills required for RAID implementation (especially in Linux). Since RAID is a server-level concept implementation hence the system administrator or the RAID implementer should have the basic knowledge of the server and the concept of it thoroughly. Mainly:
- Managing partitions of hard drives in different RAID levels or logical volume management (LVM).
- Networking configuration concept: ifconfig, IP, route, etc.
- Network debugging: netstat, traceroute, etc.
- Process management: ps, top, lsof, etc.
- Services: Apache / MySQL / DNS / DHCP / LDAP / IMAP / SMTP /FTP etc.
- Basic loggings: syslogd, logrotate, etc.
- Visualization techniques: OpenVZ, KVM etc.
- Hardware knowledge etc.
Why should we use RAID in Linux?
There might be several good reasons for using RAID, however, a few reasons among them are:
- Data redundancy.
- Performance improvement.
- Ability to combine several physical disks into one larger virtual device.
- Meant to keep the systems up & running in case of common hardware problems (disk failure).
Scope
As we know, performance, cost, and resiliency are some of the major benefits of RAID among others; by adding multiple drives together RAID can improve the work of a single drive, increase computer speed and reliability after a failure, depending on the configuration.
Although nested RAID levels are higher expensive to implement than traditional levels (because of more number of the disks and cost per GB is higher) in spite of its cost, nested RAID is getting more popular as it helps to overcome some of the reliability issues associated with standard RAID levels.
Why do we need RAID in Linux?
RAID is a technology that is basically used to increase performance and also for the reliability of data by additional storage. So, we can say that RAID is used when we need some excellent performance of the server system.
How this technology will help you in career growth?
The RAID technology is used at the server level and the usage of the same is getting more day by day. The future having bigger disks, bigger systems, and the same way the more emphasis on failure recovery. RAID can evolve with much more advanced technology to cope with all these. Similar way, the future of RAID lies in more development or coding carefully which can be targeted at specific failure recovery and parallelism that can balance the load in the reconstruction of lost data.
Conclusion
In this article, we discussed basically the RAID technology and its implementation in the Linux platform. The idea of why RAID is used and the feasibility of the same. RAID, still remains the ingrained part of data storage technology and the major technology vendors such as IBM, Intel, Dell, etc. still release RAID products. For eg., IBM Distributed RAID with spectrum Virtualize V7.6, NetApp ONTAP.
Recommended Articles
This has been a guide to What is a Raid in Linux. Here we discuss the scope, skills, career growth, and advantages of a Raid in Linux You can also go through our other suggested articles to learn more –

