Updated February 28, 2023
Introduction to Kafka Zookeeper
Zookeeper is an important part of Apache Kafka. Zookeeper is a cornerstone for so many distributed applications, as it provides fantastic features. Apache Kafka uses a zookeeper to store information regarding the Kafka cluster and user info; in short, we can say that Zookeeper stores metadata about the Kafka cluster. It’s important to us to understand what Zookeeper is and how Kafka fits with it. We’ll see what Zookeeper does in-depth, and we’ll learn why we need to use it.
What is Kafka Zookeeper?
Zookeeper is a centralized, open-source software that manages distributed applications. It provides a basic collection of primitives to implement higher-level synchronization, framework management, groups, and naming services. It is planned to be programmable and simple to use. The well-known companies that use Zookeeper are Yahoo, Twitter, Netflix, and Facebook. These are just a few names.
It keeps track of information that need to be synchronized across your cluster. Information such as:
- Which node is the master?
- Which workers will perform which tasks?
- Which workers are currently available?
It’s a tool that applications can use to recover from partial failures in your cluster. It also plays an integral part in HBase, High-Availability (HA) MapReduce, Drill, Storm, Solr, and much more. Zookeeper is itself a distributed application providing automated code-writing facilities.
The specific services that Zookeeper offers are as follows:
- Naming service: Identifying the nodes by name in a This is DNS-like except with nodes.
- Configuration monitoring: The system’s current and up-to-date configuration details for a node that joins.
- Cluster control: Real-time connection / leaving of a node in a cluster and node
- Leader Election: Selecting a node as lead
Why we need Kafka Zookeeper?
Before understanding why we need to use the zookeeper, let us first understand the coordination service. The process of integrating communication services into a distributed environment is referred to as a coordination service. These services are tough to get right. They are especially vulnerable to errors like race conditions and deadlocks.
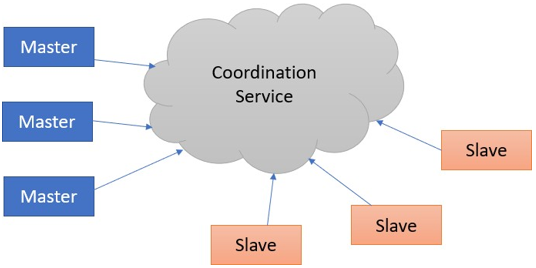
- Race Conditions: Two or more systems are trying to perform the same task, which needs to be done by a single system in a given time
- Deadlocks: Two or more operations waiting on each other for an infinite
So to make the distribution of coordination service easy, Zookeeper was implemented. So that we can be relieved from the responsibility of implementing coordination service from scratch
Yes, Zookeeper is very important as Kafka cannot work without Zookeeper. It is used to establish co-ordination within a cluster of various nodes. One of Kafka’s most important things is that it uses a zookeeper to commit offsets regularly so that it can restart from the previously committed offset in case of node failure (imagine taking care of all this by yourself).
Zookeeper also plays a crucial role in fulfilling many other functions, for example, leader detection, control of configurations, synchronization, detection when a new node enters or leaves the cluster, etc.
How Kafka uses Zookeeper?
Below are the points to use zookeeper in Kafka:
- Electing Leader: Maintaining the relationship between leader and follower for all partitions is handled by the controller, one of the brokers. If one node goes down, the controller who asks other followers to become leaders for a partition to replace the lost Zookeeper selects only a new leader to make sure that there is only one leader.
- Membership of Cluster: What brokers and a member of the cluster are alive? Zookeeper handles it.
- Configuration of Topic: How many partitions does each topic has, do the topics exists or not, and if exists, then where are the followers who are the leader selected.
- Quotas: what will be the amount of data for each client to read and write
- ACL: Who has access to read and write and to which topic, how many user groups exist and its members also information about the latest offset from each
How does Zookeeper work in Kafka?
Zookeeper runs in two modes
1. Standalone
- There is a single server
- For testing
- No High Availability
2. Replicated
- Run-on a cluster of machines called an ensemble
- Uses Paxos Algorithm
- High Availability
- Tolerates as long as the majority
Zookeeper Model
The zookeeper’s data model follows a namespace of the Hierarchy, where each node is called a ZNode. A node is a machine that operates on the cluster. Every ZNode has information. It may have children or not.
There are three forms of Znodes.
- Persistence: Such Znodes remain in Zookeeper until, Even after the client-generated the particular znode is disconnected, this form of znode is alive. By default, all nodes are persistent in zookeeper unless specified.
- Ephemeral: This node would be removed if the session in which the node was generated is terminated, implying that the znode would remain alive until the client is
- Sequential: It creates a node with a sequence number in the name; the number is automatic. These sequential nodes can be either persistence or ephemeral.
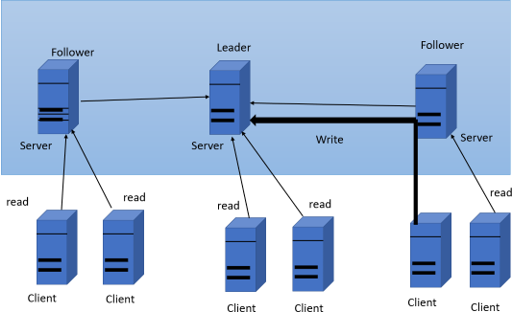
Each Zookeeper is informed about all the other zookeepers in the ensemble; if the zookeeper server on all the machines in the ensemble is switched on, Phase 1 starts, which is leader selection.
Phase1: Leader Selection (Paxos Algorithm)
- The machine elects a member as a leader, and others are termed as
- This phase is finished when the majority sync their state with the
- If the leader fails, the remaining machines hold an election within
- If the majority is not available at any point in time, the leader steps.
Conclusion
So we may conclude that we have seen what a zookeeper is, how it works means its architecture, and how necessary it is for Kafka to communicate with it.
Recommended Articles
This is a guide to Kafka Zookeeper. Here we discuss introducing Kafka zookeeper, why we need it, how to use it, and Zookeeper architecture, respectively. You can also go through our other related articles to learn more –
