Updated March 6, 2023

Introduction to Kafka Partition Key
In Kafka, the data is store in the key-value combination or pair. On the partition level, the storage happens. The key value is nothing but a messaging system. On the same basis, Kafka is working. It is useful to define the destination partition of the message. As per the requirement or configuration, we can customize or modify the Kafka partition also. In Kafka, the hash base partition is used to identify the partition id (as per the provided key). If we haven’t set it or keep it as null in the environment, then the Kafka producer will pick any random partition and keep the messages or data into it.
Syntax:
As such, there is no specific syntax available for it. Generally, we are using the configuration command for the Kafka partition key.
How does the Kafka Partition key work?
- As we have seen, It is useful to define the destination partition of the message. As per the defined key, the Kafka producer will elect the specific partition and pushing the Kafka messages or data into the partition. If we haven’t provided it, Kafka will use the default hash key partition and push the messages into it. Majorly the Kafka partition is deal with parallelism. If we are increasing the number of partition, it will also increase the parallel process also. On the producer and the broker end, the write operation will perform on the different partition topic. The operation will deal with the parallelism method.
- Kafka will allow consuming the data on the single partition only for a single consumer thread on the Kafka consumer end. Hence the grade of parallelism in the consumer will be restricted with the number of the partition (will be consumed). If you want to increase or high throughput, we need to increase the number of Kafka broker.
Kafka Partition / Partition Key Calculation
While calculating the Kafka throughput, we need to consider the partition formula in the Kafka. To calculate it, we need to consider some formulate values. Let consider calculating the throughput as per the single Kafka partition for the producer (let’s say it as “p”). For the consumer front, let’s say it is “c”. For the target throughput, let’s say it is “t”. As per the max partition, it will be “t/p and t/c”. The individual throughput can be archive depends on the producer as per the compression codec, replication factor, batching size, type of acknowledgement, etc. On the single partition, one producer can produce the message at 10 sec of MB/sec.
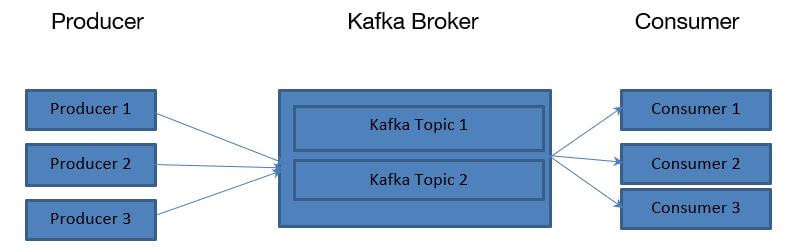
As per the above diagram, the Kafka broker will manage the number of topics present in the Kafka environment. The Kafka topics are divided into a number of partitions. The records in the topic are in an unalterable sequence. Each message or record in a partition was allocated and identified by its inimitable offset value in the Kafka environment. The number of Kafka partition value will increase the parallelism process in the Kafka environment.
While the producer will publish the number of records or messages on the topic, it will help to publish with the help of the leader only. The partition leader will attach the record to its commit logs. It will rise or increment the record offset. After the consumer committed, Kafka exposes the records or messages to the consumer. The data comes in a stacked of cluster.
Before the producer sends the data, it will request for the metadata information of the Kafka cluster broker. The metadata having the leader broker information of the individual portions. As per the metadata information, the producer will know who is the partition leader and writes the data with the help of the partition leader only.
The Kafka producer will use the partition key to get on which partition the data need to write. The default operation is to use the hash key to calculate the partition.
Example
Given below is the example to implement or check the Kafka partition key:
In the Kafka environment, the producer will produce the data. The producer will know on which partition the data needs to write. It will take the decision on the bases of the producer leader. Here, no broker comes into the picture. The producer will attach the key to the records and allow storing the data on the specific Kafka topic or partition. All the records with the same key will arrive in the same Kafka Partition.
- The cluster Kafka broker port is “6667”.
- The single Kafka broker port is “9092”.
- On TLS or SSL Kafka environment, the port will be “9093”.
Code:
./kafka-topics.sh --create --zookeeper 10.10.132.70:2181 --replication-factor 1 --partitions 3 --topic elearning_kafka_tpc
Explanation:
- As per the above command, we have created the “elearning_kafka_tpc” Kafka topic. It will come up with the default partition key.
Output:

Conclusion
We have seen the uncut concept of “Kafka partition key” with the proper example, explanation and methods with different outputs. As per the requirement, we can create multiple partitions in the topic. With the help of a key, we can forcefully say that the data or messages need to move on to the specific partition.
Recommended Articles
This is a guide to Kafka Partition Key. Here we discuss the introduction, working, Kafka partition/partition key calculation and example. You may also have a look at the following articles to learn more –
