Introduction to Types of Joins in SQL
Understanding SQL joins is essential in the world of relational databases. Knowing the types of joins and when to use them can significantly improve your querying skills. This article will cover the types of joins in SQL, their syntax, and real-world applications. You’ll have the skills to create queries that reveal valuable insights by the end. Joining tables is like solving a puzzle; each piece contributes to the bigger picture.
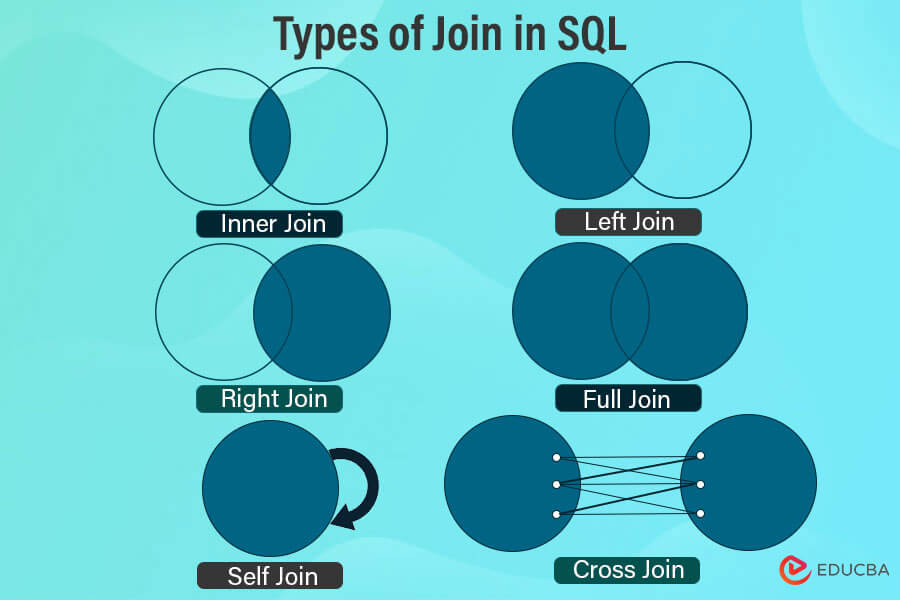
Suppose two data sets in our database are stored in Table One and Table Two. There is some relation between the two tables, which is specified as a primary key and a foreign key concept. Suppose you join two tables having some relationship. The amount of this overlap will determine the extent of similarity between the two tables. This means that the overlap section represents the number of records from table one that match the records from table two. We get six types of joins based on the subset of data we pick from the two tables.
Syntax of Join:
SELECT column-names FROM table-name1 JOIN table-name2 ON column-name1 = column-name2 WHERE conditionTable of Contents
Different Types of Joins in SQL
Below we explain the types of Joins in SQL.
1. Inner Join
In an inner join, we only select the common data in both tables. To make it more precise, all the records from both the tables matching up the condition mentioned with the join are picked in this join.
Syntax of Inner Join:
SELECT column-names FROM table-name1 INNER JOIN table-name2 ON column-name1 = column-name2 WHERE condition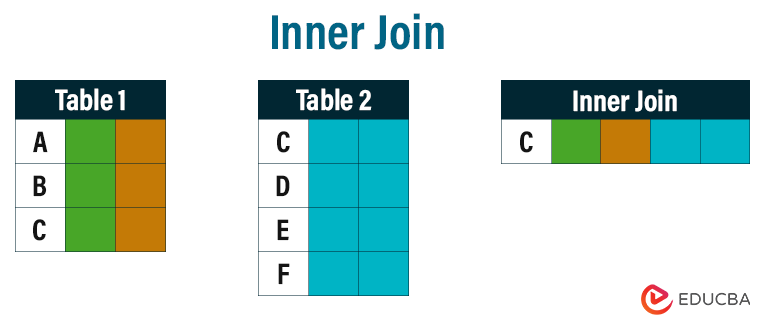
Inner Join includes data from both tables with the same values, as shown in the above figure. Only the C row is indicated in the inner join table because it is common to both tables.
2. Left Join
In the left join, we select all the data from the left table, and from the right table, we only select the data set that matches up with the condition mentioned with the join.
Syntax of Left Join:
SELECT column-names FROM table-name1 LEFT JOIN table-name2 ON column-name1 = column-name2 WHERE condition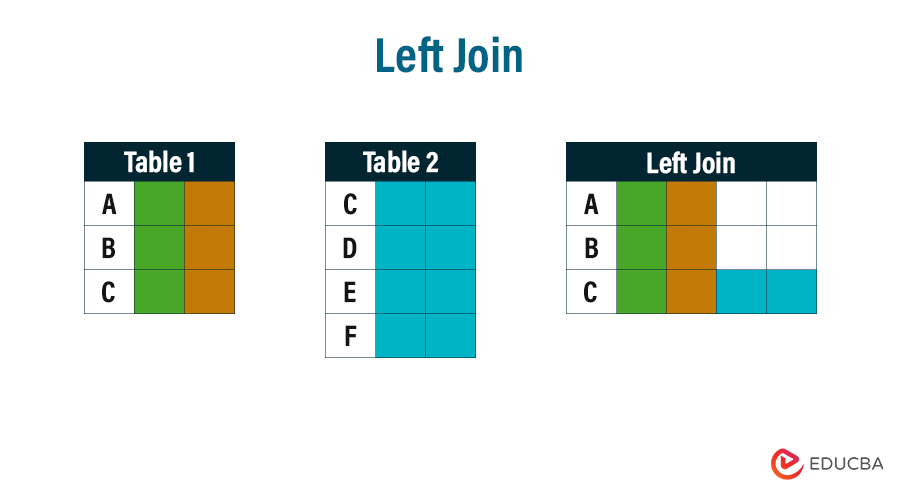
All of the data from Table 1 is shown in the above figure, and just the C row from Table 2 is shown because it is common to both tables.
3. Right Join
In the right join, we select all the data from the right table, and from the left table, we only select the data set that matches up with the condition mentioned with the join.
Syntax of Right Join:
SELECT column-names FROM table-name1 RIGHT JOIN table-name2 ON column-name1 = column-name2 WHERE condition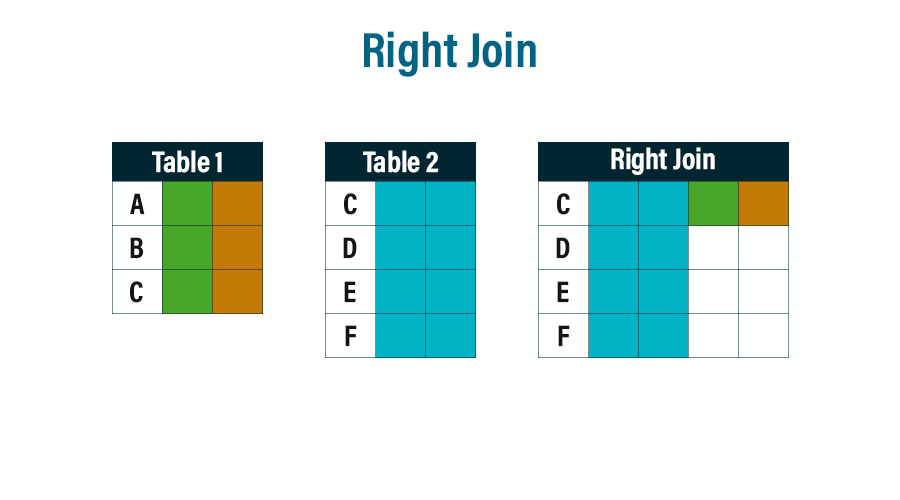
All of the data from Table 2 is shown in the above figure, and just the C row from Table 1 is taken because it is common to both tables.
4. Full Join
In full join, all the records from both tables are merged and selected irrespective of the condition mentioned with the join having met or not.
Syntax of Full Join:
SELECT column-names FROM table-name1 FULL JOIN table-name2 ON column-name1 = column-name2 WHERE condition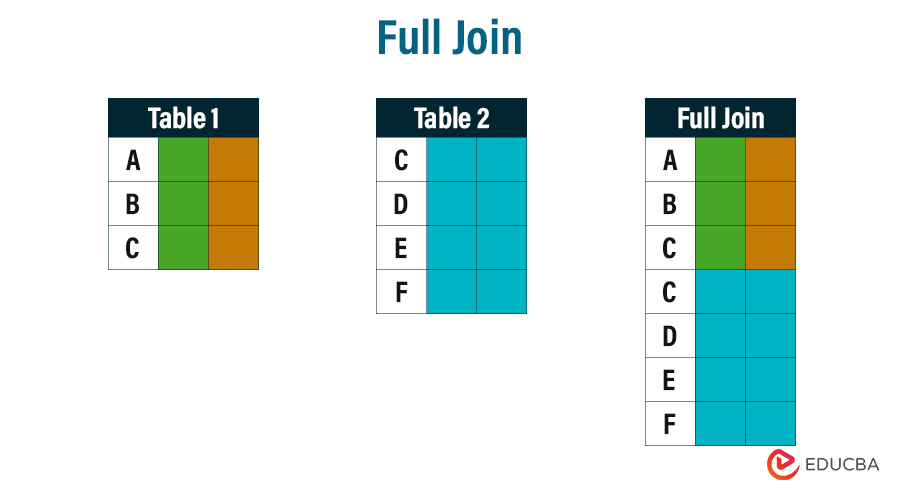
The following figure demonstrates the combined data from Tables 1 and 2.
5. Self Join
A Self Join is a unique join in which a single table is attached. This may appear illogical initially, but it is a powerful strategy for retrieving information about related records within the same database.
Syntax of Self Join:
SELECT Column_list FROM table1 AS alias1 JOIN table1 AS alias2 ON alias1.column_name = alias2.column_name;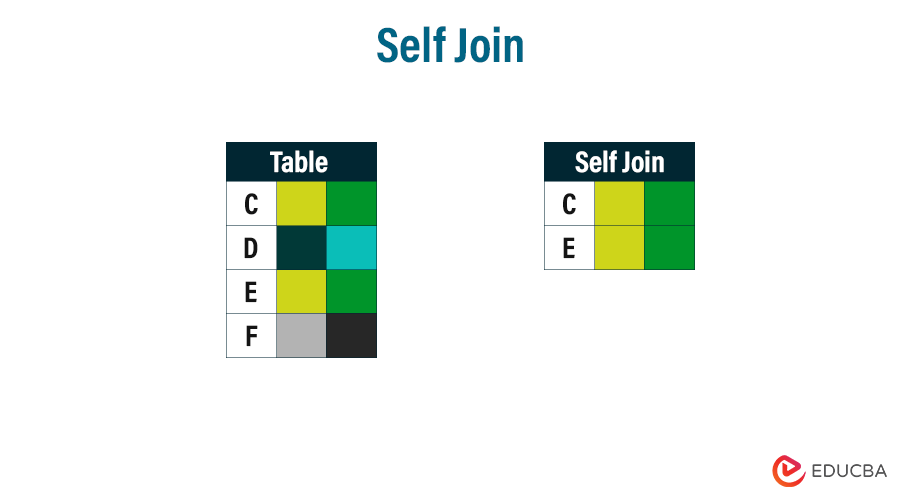
In this table, rows C and E have the same color, indicating that they have common values. Hence, the C and E columns are shown in the self-join diagram.
6. Cross Join
The Cross Join, also called a Cartesian Join, combines all rows from the first table with all rows from the second table, producing a Cartesian product of the two tables. It has the potential to be effective in certain situations. However, it should be utilized with caution as it may create massive result sets.
Syntax of Cross Join:
SELECT column_list FROM table1 CROSS JOIN table2;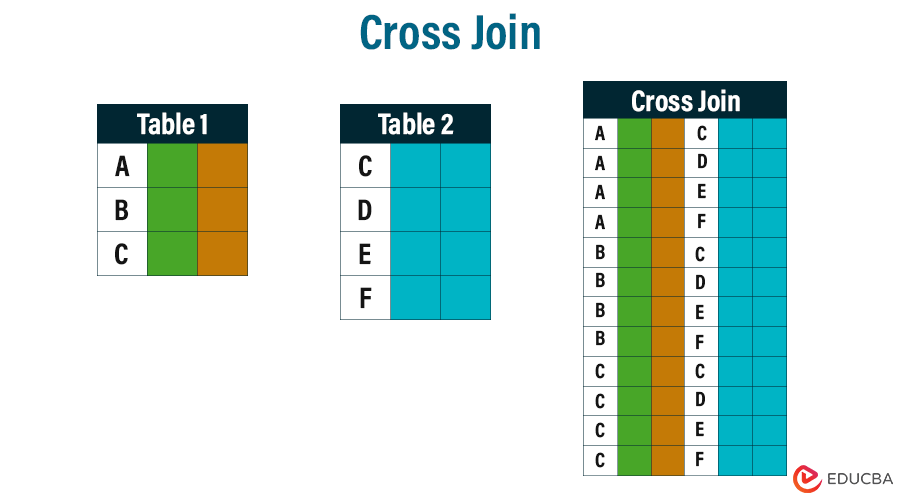
In this diagram, all of the rows from Table 1 are joined with those from Table 2 (such as row A from Table 1 joins with rows C, D, E, and F of Table 2, and the same goes for B and C)
Examples of Joins in SQL
Below are the examples of each SQL join:
First, we have to create tables as a base for our examples. Consider the two tables given below:
- Company
- Employees
Create table Company
Query:
CREATE TABLE Company (
CompanyID INT PRIMARY KEY,
CompanyName VARCHAR(50)
);
INSERT INTO Company (CompanyID, CompanyName)
VALUES (101, 'Amazon'),
(201, 'Google'),
(301, 'Nike');
Select * from Company;Output:
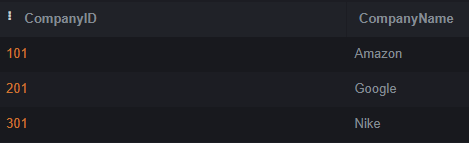
Create Table Employees
Query:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
CompanyID INT,
EmployeeName VARCHAR(50),
Designation VARCHAR(50)
);
INSERT INTO Employees (EmployeeID, CompanyID, EmployeeName, Designation)
VALUES (12, 101, 'Alice', 'Manager'),
(27, 201, 'John', 'Designer'),
(25, 101, 'Clara', 'Manager'),
(32, 301, 'Leon', 'Developer'),
(44, 201, 'Julia', 'Designer');
Select * from Employees;Output:
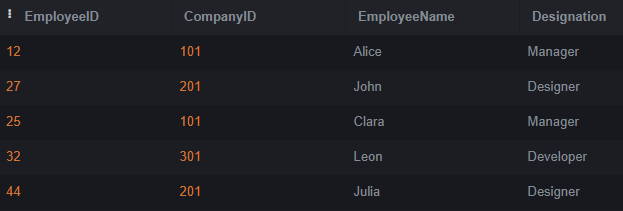
1. Inner Join Example
Query:
SELECT Company.CompanyName, Employees.EmployeeName, Employees.Designation
FROM Company
INNER JOIN Employees ON Company.CompanyID = Employees.CompanyID;Output:
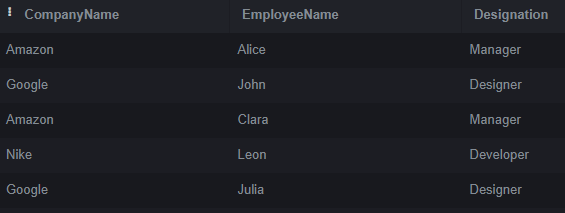
The INNER JOIN in this example joins the Company and Employees databases using the common CompanyID column. Only rows with a match in both tables are included in the output. The output provides each matching row’s company name, employee name, and Designation.
2. Left Join Example
Query:
SELECT Company.CompanyName, Employees.EmployeeName, Employees.Designation
FROM Company
LEFT JOIN Employees ON Company.CompanyID = Employees.CompanyID;Output:
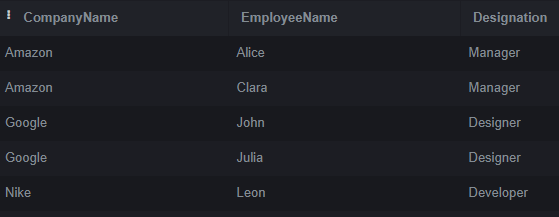
Using a LEFT JOIN, the Company and Employees tables are combined based on their Common CompanyID column. This results in all rows from the Company table being included in the output and any corresponding rows from the Employees table. The resulting columns will contain NULL values if no matches are found in the Employees table. The work displays each row’s company name, employee name, and Designation.
3. RIGHT JOIN Example
Query:
SELECT Company.CompanyName, Employees.EmployeeName, Employees.Designation
FROM Company
RIGHT JOIN Employees ON Company.CompanyID = Employees.CompanyID;Output:
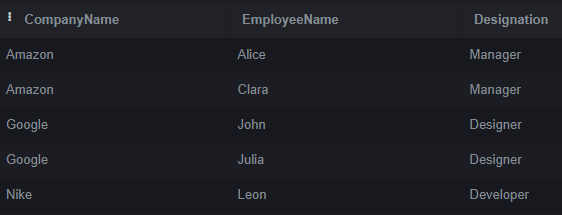
The RIGHT JOIN combines the Company and Employees tables based on the common CompanyID column in this example. The result includes all rows from the Employees table and any matching rows from the Company table. In cases where there is no match in the Company table, the columns from that table will have NULL values. Each row in the output displays the company name, employee name, and Designation.
4. Full Join Example
Query:
SELECT Company.CompanyName, Employees.EmployeeName, Employees.Designation
FROM Company
FULL JOIN Employees ON Company.CompanyID = Employees.CompanyID;Output:
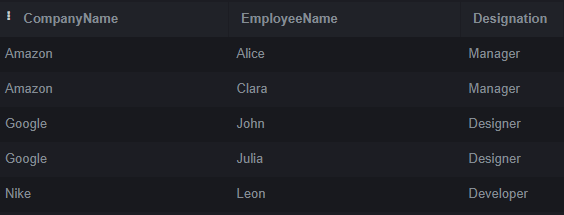
In this example, a FULL JOIN is executed between the tables Company and Employees, retrieving all rows from both tables, including those that match and those that don’t. The corresponding columns will display NULL values if no related data is in the Company or Employees table.
5. Self Join Example
Query:
SELECT e1.EmployeeName AS Employee1, e2.EmployeeName AS Employee2, c.CompanyName
FROM Employees e1
INNER JOIN Employees e2 ON e1.CompanyID = e2.CompanyID AND e1.EmployeeID <> e2.EmployeeID
INNER JOIN Company c ON e1.CompanyID = c.CompanyID;Output:
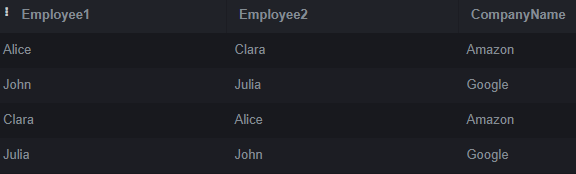
For this demonstration, we performed a self-join on the Employees table using two aliases, e1 and e2. Our goal was to identify employees who work in the same company (determined by CompanyID). To avoid pairing an employee with themselves, we included condition e1.EmployeeID <> e2.EmployeeID. We merged the outcome with the Company table to include the company name in the final output to complete the process.
6. Cross Join Example
Query:
SELECT Company.CompanyName, Employees.EmployeeName, Employees.Designation
FROM Company
CROSS JOIN Employees;Output:
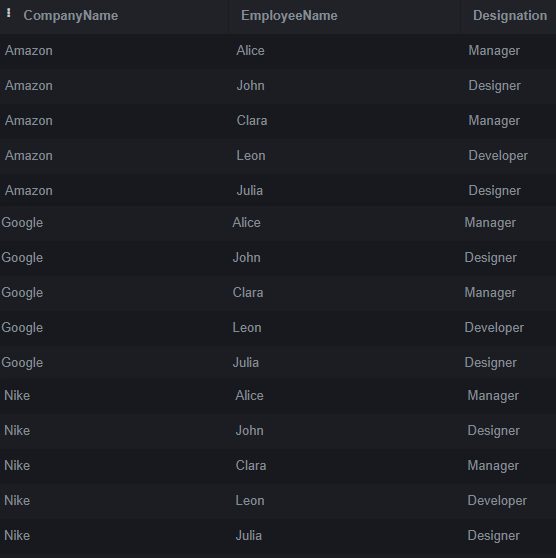
Combining each row from the Company table with every row from the Employees table creates a cross-join that generates all possible combinations. However, this can result in rows, so using cross joins cautiously is important, especially if the tables have many rows.
Advantages
Here are some key advantages of using joins in SQL:
- Data Integration and Consolidation: Combining related data from different tables is possible through joins, which offer a comprehensive perspective of your data. This integration is especially valuable when handling intricate database structures with multiple related tables.
- Efficient Data Retrieval: Instead of querying individual tables and manually matching data, using joins allows you to retrieve all necessary information in one query. This results in fewer database requests and improves query performance.
- Storing Data Efficiently: Designing relational databases aims to decrease data redundancy and enhance data integrity by utilizing normalized data storage. You can retrieve normalized data and transform it into meaningful information using joins.
- Performing Complex Analysis: Joins are essential for complex analytical tasks that involve comparing and combining data from multiple tables. This is crucial for making data-driven decisions, generating insights, and conducting business intelligence. Platforms such as DataDriven.io help professionals further enhance their analytical capabilities by applying advanced data analysis and reporting techniques to real-world datasets.
- Dealing with Hierarchical and Self-Referential Data: Joins are crucial for handling hierarchical data structures or self-referential relationships within a single table. They enable you to navigate parent-child relationships and derive valuable insights.
- Avoiding Data Duplication: Instead of duplicating data across multiple tables, it is better to store data in separate related tables and use joins to retrieve information as needed. This ensures data consistency and reduces storage requirements.
- Flexible Query Design: Joins provide the flexibility to create versatile queries that accommodate changing business requirements. You can adjust the joint conditions and columns to cater to different reporting or analysis needs.
- Generating Aggregated Reports: Joins are integral for creating comprehensive reports that involve data from different parts of your database. To generate meaningful insights, you can perform aggregations, calculations, and summaries on joined data.
- Maintaining Code: By utilizing joins, you can write more concise and maintainable SQL code. It reduces the need for complex procedural logic or multiple round trips to the database.
- Normalized Updates: Using joins to update data ensures changes occur normalized, eliminating the need to update the same information in multiple places. This reduction in risk leads to more consistent data.
- Cross-Functional Analysis: Joins enable cross-functional analysis by allowing you to combine data from various departments or modules within an organization’s database.
Performance Considerations: Impact of Join Selection on Query Execution
Optimizing join selection can improve query response times and overall database efficiency. Here are some crucial points to remember:
- Choose the Appropriate Join Type: Choose the join that best fits your data relationships. Inner joins are frequently more efficient for retrieving related data, whereas outer joins include unmatched records and necessitate additional processing.
- Use Indexes Wisely: Indexing columns involved in join conditions can considerably improve query performance. Indexes help the database to find matching records more quickly, which is very useful when working with massive datasets.
- Consider Join Order: The sequence in which tables are joined can affect performance in queries containing multiple joins. Starting with the table that reduces the size of the result set can improve performance.
- Avoid Cartesian Products: Cross joins should be used with caution because they can produce Cartesian products with enormous result sets. Limit your use of them and make sure you have adequate filtering conditions.
- Review Query Plans: Analyse query execution plans created by the database optimizer. This offers information about how the database intends to perform the query and helps in the identification of potential bottlenecks.
- Balance Denormalization and Normalization: While normalization decreases duplication, denormalization can increase performance by removing the need for unnecessary joins. Evaluate the trade-offs based on query patterns.
- Use Query Optimizers: Modern database systems use query optimizers to choose the most efficient execution plan. Trust the optimizer, but make sure your schema design supports its decisions.
- Test with Realistic Data: It’s a good practice to test benchmark queries with realistic data volumes to imitate real-world usage. This method assists in recognizing any performance problems before launching into production.
- Monitor and Tune: It is essential to keep a close eye on query performance and the overall health of your database. Achieving this involves regularly monitoring and adjusting indexing, implementing caching strategies, and making necessary adjustments to queries to ensure optimal performance.
Conclusion
SQL joins a crucial tool for unlocking the complete potential of relational databases. They allow for the smooth integration of related data from multiple tables, enabling in-depth analysis, speedy data retrieval, and informed decision-making. SQL joins consolidate information, streamline queries, and untangle intricate connections, making them a vital aspect of efficient data management. They pave the way for more insightful revelations and robust business strategies.
Recommended Articles
We hope that this EDUCBA information on “Types of Joins in SQL” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
