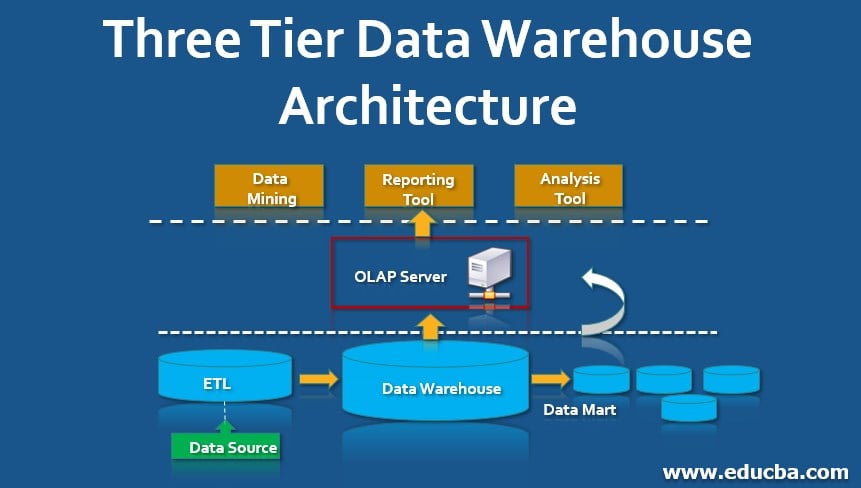
A data warehouse is a central repository built for analytics, reporting, and decision-making. In a classic three tier data warehouse architecture, data moves from source systems into a storage layer, passes through an analytical layer, and is finally presented through reporting or BI tools. This separation helps organizations manage data integration, performance, and user access more effectively. ETL commonly extracts data from multiple systems, cleans and standardizes it, and loads it into the warehouse, while OLAP tools support multidimensional analysis for reporting and business intelligence.
The three tiers are:
- Top Tier
- Middle Tier
- Bottom Tier
Each layer has a distinct role, and together they create a complete warehouse system. Modern cloud platforms may also separate storage and compute, and some architectures increasingly use ELT rather than traditional ETL when transformations occur within the target platform.
Three-Tier Data Warehouse Architecture
Here is a pictorial representation of the Three-Tier Data Warehouse Architecture
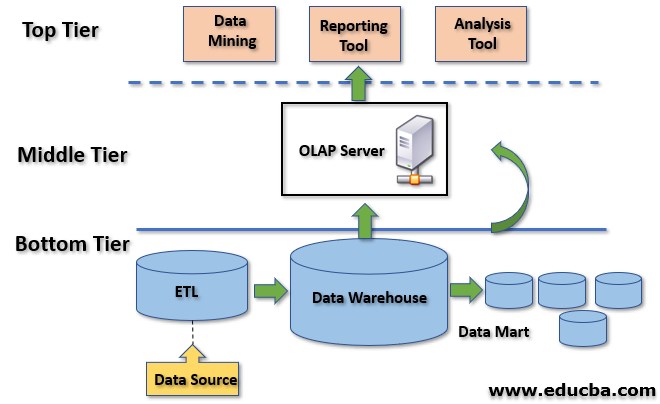
1. Bottom Tier
The Bottom Tier in the three-tier architecture of a data warehouse consists of the Data Repository. The Data Repository stores data extracted from various data sources, which undergo a series of activities as part of the ETL process. ETL stands for Extract, Transform, and Load. As a preliminary step, before the data is loaded into the repository, all relevant and required data are identified from several system sources. These data are then cleaned up to avoid repeating or junk data from their current storage units. The next step is to transform all this data into a single storage format. The final step of ETL is to load the data into the repository.
A few commonly used ETL tools are:
- Informatica
- Microsoft SSIS
- Snaplogic
- Confluent
- Apache Kafka
- Alooma
- Ab Initio
- IBM Infosphere
The repository can use either a relational or a multidimensional database system. Relational systems store simple structured data, while multidimensional systems handle data across multiple dimensions. They create a metadata unit to store metadata from each source, and it sends the metadata to the middle tier when both systems are used together. Users access bottom-tier data using SQL queries, with relational data requiring simpler queries and multidimensional data requiring more complex joins and conditions.
2. Middle Tier
The Middle tier here is the tier with the OLAP servers. The data warehouse may include more than one OLAP server and OLAP server model, which the organization selects based on the data volume and the type of data stored in the bottom tier. There are three types of OLAP server models, such as:
ROLAP
- Relational online analytical processing is a model of online analytical processing that performs an active multidimensional breakdown of data stored in a relational database, rather than redesigning the database to be multidimensional.
- They apply this when the repository consists of only a relational database system.
MOLAP
- Multidimensional online analytical processing is another model of online analytical processing that catalogs and stores data in directories directly within its multidimensional database system.
- They apply this when the repository contains only a multidimensional database system.
HOLAP
- Hybrid online analytical processing combines relational and multidimensional models.
- When a repository contains both relational and multidimensional database management systems, HOLAP is the best solution for ensuring a smooth, functional flow between them. HOLAP allows storing data in both the relational and the multidimensional formats.
The Middle Tier acts as an intermediary component between the top tier and the data repository, that is, the top tier and the bottom tier, respectively. From the user’s standpoint, the middle tier provides insight into the database’s conceptual structure.
3. Top Tier
The top tier is the front-end layer that connects users to the database through tools or APIs for reporting, analysis, and data mining. The tool type depends on the required output, such as reporting, querying, or analysis. It should be simple and user-friendly to ensure effective results. Even when the bottom and middle tiers are designed with utmost caution and clarity, if the Top tier is enabled with a bungling front-end tool, the whole Data Warehouse Architecture can become an utter failure. This makes the selection of the user interface/ front-end tool as the Top Tier, which will serve as the face of the Data Warehouse system, a very significant part of the Three-Tier Data Warehouse Architecture design process.
Below are a few commonly used Top Tier tools.
- IBM Cognos
- Microsoft BI Platform
- SAP Business Objects Web
- Pentaho
- Crystal Reports
- SAP BW
- SAS Business Intelligence
Infrastructure Considerations for Three-Tier Data Warehouse Architecture
The effectiveness of a Three-Tier Data Warehouse depends not only on its logical design but also on the reliability of the infrastructure that powers it. The storage layer, which forms the core of the Bottom Tier, performs best when hosted in a dedicated data center environment where power stability, advanced cooling systems, physical security, and network redundancy are tightly controlled. Organizations that deploy their warehouses in high-quality data center facilities like Datum gain a strong architectural foundation that supports continuous data growth. This ensures seamless scalability, faster query processing, and high system availability. With properly managed infrastructure, companies can maintain minimal downtime and achieve consistent performance, even when data demands expand rapidly across all three tiers.
Conclusion
To sum up, the processes involved in the three-tier architecture are ETL, querying, and OLAP, with the results produced in the top tier of this system. The front-end activities, such as reporting, analytical results, or data mining, are also a part of the process flow of the Data Warehouse system. The top tier produces the final result used for business decision-making. Hence, it delivers noticeable quality and efficiency. It is also dependent on the competence of the other two tiers. This three tier data warehouse architecture helps achieve the excellence and worthiness expected of a Data Warehouse system.
Recommended Articles
This is a guide to a three tier data warehouse architecture. Here we discuss the Introduction and the three tier data warehouse architecture, which includes the top, middle, and bottom tiers. You may also have a look at the following articles to learn more –
