Updated March 18, 2023
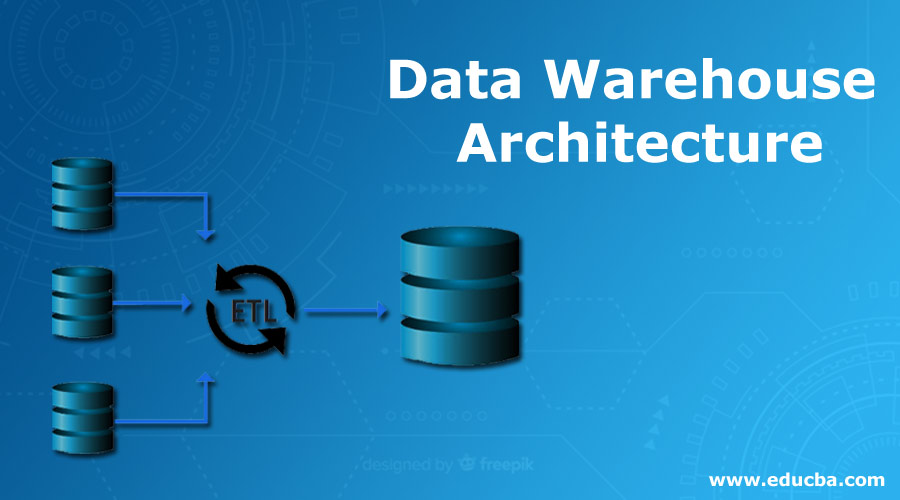
Introduction to Data Warehouse Architecture
The Data Warehouse Architecture can be defined as a structural representation of the concrete functional arrangement based on which a Data Warehouse is constructed that should include all its major pragmatic components, which is typically enclosed with four refined layers, such as the Source layer where all the data from different sources are situated, the Staging layer where the data undergoes ETL processing, the Storage layer where the processed data are stored for future exercises, and the presentation layer where the front-end tools are employed as per the users’ convenience.
Data Warehouse Architecture

The Data Warehouse Architecture generally comprises of three tiers.
- Top Tier
- Middle Tier
- Bottom Tier
Top Tier
- The Top Tier consists of the Client-side front end of the architecture.
- The Transformed and Logic applied information stored in the Data Warehouse will be used and acquired for Business purposes in this Tier.
- Several Tools for Report Generation and Analysis are present for the generation of desired information.
- Data mining which has become a great trend these days is done here.
- All Requirement Analysis documents, cost, and features that determine a profit-based Business deal are done based on these tools, which use the Data Warehouse information.
Middle Tier
- The Middle Tier consists of the OLAP Servers
- OLAP is Online Analytical Processing Server
- OLAP is used to provide information to business analysts and managers
- As it is located in the Middle Tier, it rightfully interacts with the information present in the Bottom Tier and passes on the insights to the Top Tier tools, which processes the available information.
- Mostly Relational or MultiDimensional OLAP is used in Data warehouse architecture.
Bottom Tier
The Bottom Tier mainly consists of the Data Sources, ETL Tool, and Data Warehouse.
1. Data Sources
The Data Sources consists of the Source Data that is acquired and provided to the Staging and ETL tools for further process.
2. ETL Tools
- ETL tools are very important because they help in combining Logic, Raw Data, and Schema into one and loads the information to the Data Warehouse Or Data Marts.
- Sometimes, ETL loads the data into the Data Marts, and then information is stored in Data Warehouse. This approach is known as the Bottom-Up approach.
- The approach where ETL loads information to the Data Warehouse directly is known as the Top-down Approach.
Difference Between Top-down Approach and Bottom-up Approach
| Top-Down Approach | Bottom-Up Approach |
| Provides a definite and consistent view of information as information from the data warehouse is used to create Data Marts | Reports can be generated easily as Data marts are created first, and it is relatively easy to interact with data marts. |
| Strong model and hence preferred by big companies | Not as strong, but the data warehouse can be extended, and the number of data marts can be created. |
| Time, Cost and Maintenance is high | Time, Cost and Maintenance are low. |
Data Marts
- Data Mart is also a storage component used to store data of a specific function or part related to a company by an individual authority.
- Datamart gathers the information from Data Warehouse, and hence we can say data mart stores the subset of information in Data Warehouse.
- Data Marts are flexible and small in size.
3. Data Warehouse
- Data Warehouse is the central component of the whole Data Warehouse Architecture.
- It acts as a repository to store information.
- Big Amounts of data are stored in the Data Warehouse.
- This information is used by several technologies like Big Data which require analyzing large subsets of information.
- Data Mart is also a model of Data Warehouse.
Different Layers of Data Warehouse Architecture
Below are the different layers:
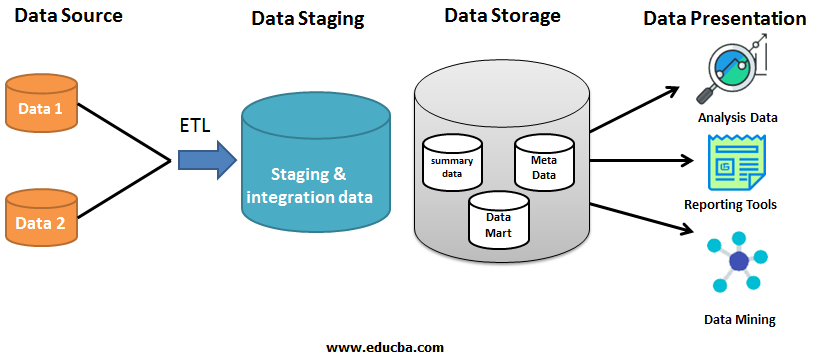
There are four different types of layers which will always be present in Data Warehouse Architecture.
1. Data Source Layer
- The Data Source Layer is the layer where the data from the source is encountered and subsequently sent to the other layers for desired operations.
- The data can be of any type.
- The Source Data can be a database, a Spreadsheet or any other kind of text file.
- The Source Data can be of any format. However, we cannot expect to get data with the same format considering the sources are vastly different.
- In Real Life, Some examples of Source Data can be
- Log Files of each specific application or job or entry of employers in a company.
- Survey Data, Stock Exchange Data, etc.
- Web Browser Data and many more.
2. Data Staging Layer
The following steps take place in Data Staging Layer.
Step #1: Data Extraction
The Data received by the Source Layer is feed into the Staging Layer, where the first process that takes place with the acquired data is extraction.
Step #2: Landing Database
- The extracted data is temporarily stored in a landing database.
- It retrieves the data once the data is extracted.
Step #3: Staging Area
- The Data in Landing Database is taken, and several quality checks and staging operations are performed in the staging area.
- The Structure and Schema are also identified, and adjustments are made to data that are unordered, thus trying to bring about a commonality among the data that has been acquired.
- Having a place or set up for the data just before transformation and changes is an added advantage that makes the Staging process very important.
- It makes data processing easier.
Step #4: ETL
- It is an Extraction, Transformation, and Load.
- ETL Tools are used for the integration and processing of data where logic is applied to rather raw but somewhat ordered data.
- This data is extracted as per the analytical nature that is required and transformed to data that is deemed fit to be stored in the Data Warehouse.
- After Transformation, the data or rather information is finally loaded into the data warehouse.
- Some examples of ETL tools are Informatica, SSIS, etc.
3. Data Storage Layer
- The processed data is stored in the Data Warehouse.
- This Data is cleansed, transformed, and prepared with a definite structure and thus provides opportunities for employers to use data as required by the Business.
- Depending upon the approach of the Architecture, the data will be stored in Data Warehouse as well as Data Marts. Data Marts will be discussed in the later stages.
- Some also include an Operational Data Store.
4. Data Presentation Layer
- This Layer where the users get to interact with the data stored in the data warehouse.
- Queries and several tools will be employed to get different types of information based on the data.
- The information reaches the user through the graphical representation of data.
- Reporting Tools are used to get Business Data, and Business logic is also applied to gather several kinds of information.
- Meta Data Information and System operations and performance are also maintained and viewed in this layer.
Conclusion
An important point about Data Warehouse is its efficiency. To create an efficient Data Warehouse, we construct a framework known as the Business Analysis Framework.
There are four types of views in regard to the design of a Data warehouse.
1. Top-Down View: This View allows only specific information needed for a data warehouse to be selected.
2. Data Source View: This view shows all the information from the source of data to how it is transformed and stored.
3. Data Warehouse View: This view shows the information present in the Data warehouse through fact tables and dimension tables.
4. Business Query View: This is a view that shows the data from the user’s point of view.
Recommended Articles
This has been a guide to Data Warehouse Architecture. Here we discussed the different types of Views, Layers, and Tiers of Data Warehouse Architecture. You can also go through our other suggested articles to learn more –
