Updated May 22, 2023

Introduction to Tableau Hyper
Tableau hyper is a new memory data engine technology that was designed for the analytical query processing, and data ingest, which is fast onto large data sets. With the tableau version of 10.5, hyper is dicing and slicing more amount of data in seconds. By using tableau hyper, we can set up a 5x query faster speed, and also, we can improve the extract query speed up to 3x. With query performance and enhanced extract and support into the larger data sets, we can choose to extract the data as per the needs of our business.
What is Tableau Hyper?
The tableau hyper will contain the set of functions we can use to automate our interactions with tableau extract files. We can use the API to create the new extract files or open an existing file. Using tableau hyper, we can open the existing files and then update, delete and insert data from the specified files. Using the tableau hyper, we can create and extract the files for the sources of data, and it is supported in the tableau. We can automate the custom extract and load by using tableau hyper i.e. incremental custom updates and rolling windows updates.
How to Create a Tableau Hyper File?
We can use the tableau hyper API to automate our interactions. First, we are creating the tableau hyper files and then delete, insert and update the data from the files. We can use the data sources in the tableau.
Below steps shows how we can create the tableau hyper file as follows:
1. Import the Library of Hyper API
The import library of hyper API will vary depending on the language of programming. The library also varies as per the client library which we are using. In the below example, we are importing the library as follows.
Code:
from tableauhyperapi import …., SqlType, \
TableDefinition, … , TableNameOutput:

2. Start the Process of Hyper
After importing the library in this step, we are starting the process of hyper. In this step, we are starting the local database server. We need to start only on instances of hyper at one time. By default, hyper is using the version of file format as zero. We can deviate the same from the version of the default file.
Code:
with HyperProcess (telemetry = …) as hyper:Output:

3. Open the Connection of .hyper File
In this step, we are opening the connection of a hyper file. We need to use the connection object to connect to the specified hyper file name. We can create the connection objects for connecting to the hyper files as we need to provide the connection to the hyper file. In the below example, we are creating the connection by using with the statement; when we have ended with a statement, our connection will close.
Code:
with Connection (hyper.endpoint, …) as connection:Output:

4. Define the Table
In this step, we are creating the table definitions by using the method of the table definition. We can create the named schema into the database for differentiating and organizing the table. We can use the create schema command to create the new schema. If we are not specifying any schema, it will automatically define the default schema as public. The below example shows a defined table.
Code:
connection.catalog.create_schema ('Hyper') ….
TableDefinition.Column ('ID', SqlType.amall_int ()),
… ])Output:

5. Create the Table
After defining the table in this step, we create the new table. We can create the table by using the connection name as a catalog. This connection is responsible for the metadata of the extracted file. We can use the catalog connection for querying the database. The below example shows create the table as follows.
Code:
connection.catalog.create_table (Hyper)Output:

6. Add Data into the Table
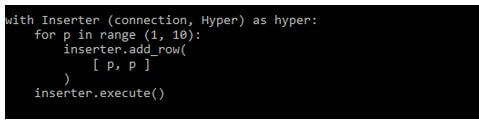
After creating the table in this step, we add the data to the table. We can use the inserter, or also we can use the SQL command to add or copy the data into the table. The below example shows adding the data to the table.
Code:
with Inserter (connection, Hyper) as hyper:
for p in range (1, 10):
inserter.add_row (
[ p, p ]
)
inserter.execute ()Output:
7. Shutdown the Process of Hyper and Close the Connection
After creating the hyper file, we can shut down the process of hyper and close the connection. Suppose we are using the python process to open the connection, then we need to shut down the server explicitly.
Tableau Hyper Formats
We need to keep only the process running and close the tableau hyper process. At the time of calling hyper process by using the statement, our hyper process is shut down safely without any errors. When running the hyper process, we can create and connect with many hyper files. At the time of starting and shutting down the server, it will take time to execute the command. The hyper process is instructed for sending the telemetry onto the usage of hyper API, We can also specify the agent of user, and it is an arbitrary string that was used to identify the application.
When saving tableau, we are saving it into the formats below.
Below file format is available in a tableau as follows:
- Hype and tde: These file types will save the data from a table. Suppose we are working on tableau data; we first need to save the initial data we are working on. Basically, hyper is new to the tableau.
- Tds and tdsx: The file of tds is a saving process that was changing behind the data source, which was initial. This includes the changes in default formatting and the formula used to calculate the fields. The tds file is used to apply the data source for recreating the data.
- Twb and twbx: The twb file format is similar to the tds, twb includes the views information as well as info about the field parameter. Twbx file is the advanced version of the twb file.
Conclusion
Using tableau hyper, we can open the existing files and then update, delete and insert data from the specified files. Tableau hyper is a new memory data engine technology that was designed for the analytical query processing, and data ingest, which is fast onto large data sets.
Recommended Articles
This is a guide to Tableau Hyper. Here we discuss the introduction, and how to create a tableau hyper file? and formats, respectively. You may also have a look at the following articles to learn more –
