Updated February 27, 2023

Introduction to Spark Repartition
The repartition() method is used to increase or decrease the number of partitions of an RDD or dataframe in spark. This method performs a full shuffle of data across all the nodes. It creates partitions of more or less equal in size. This is a costly operation given that it involves data movement all over the network. Partitions play an important in the degree of parallelism. The number of parallel tasks running in each stage is equal to the number of partitions. Thus, we can control parallelism using the repartition()method. It also plays a role in deciding the no of files generated in the output.
Syntax:
obj.repartition(numPartitions)
Here, obj is an RDD or data frame and numPartitions is a number signifying the number of partitions we want to create.
How to Use Spark Repartition?
In order to use the method following steps have to be followed:
- We need to create an RDD or dataframe on which we can call the method.
We can create an RDD/dataframe by a) loading data from external sources like hdfs or databases like Cassandra b) calling parallelize()method on a spark context object and pass a collection as the parameter (and then invoking toDf() if we need to a dataframe) - Next is to decide an appropriate value of numPartitions. We cannot choose a very large or very small value of numPartitions. This is because if we choose a very large value then a large no of files will be generated and it will be difficult for the hdfs system to maintain the metadata. On the other hand, if we choose a very small value then data in each partition will be huge and will take a lot of time to process.
Examples of Spark Repartition
Following are the examples of spark repartition:
Example #1 – On RDDs
The dataset us-counties.csv represents the no of Corona Cases at County and state level in the USA in a cumulative manner. This dataset is obtained from https://www.kaggle.com/ and the latest data available is for 10th April. Let’s find the no of Corona cases till the 10th of April at various states of the USA.
Code:
sc.setLogLevel("ERROR")
valmyRDD = sc.textFile("https://cdn.educba.com/home/hadoop/work/arindam/us-counties.csv")
myRDD.take(5).foreach(println) //Printing to show how the data looks like
println("Number of partitions in myRDD: "+myRDD.getNumPartitions) //Printing no of partitions
val head = myRDD.first()
val myRDD1 = myRDD.filter(x=>x!=head &&x.split(",")(0)=="2020-04-10") //Filtering out header and taking latest data available
val myRDD2 = myRDD1.repartition(10) // repartitioning to 10 partitions
println("Number of partitions in myRDD: "+myRDD2.getNumPartitions) //Printing partitions after repartition
val myRDD3 = myRDD2.map(x=>(x.split(",")(2),x.split(",")(4).toLong)) //Creating pairWise RDD with State and no of cases
valrslt = myRDD3.reduceByKey((x,y)=>x+y).collect().sortBy(x=>x._2)(Ordering[Long].reverse) //Summing up all the values of cases
rslt.foreach(println)
Output:
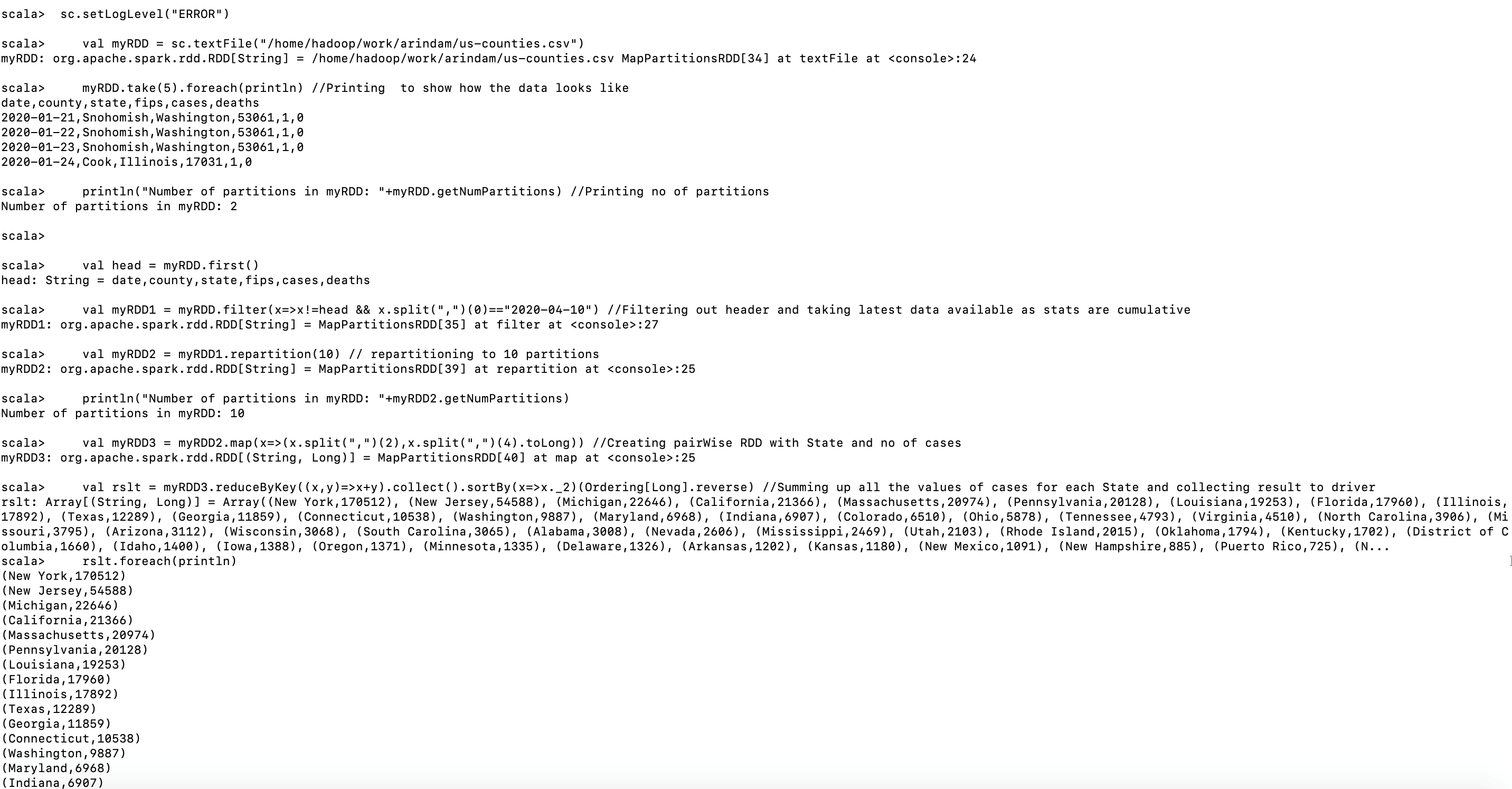
We are sorting the output based on the no of cases in a descending manner so as to fit some top-most affected states in the output.
Spark UI:
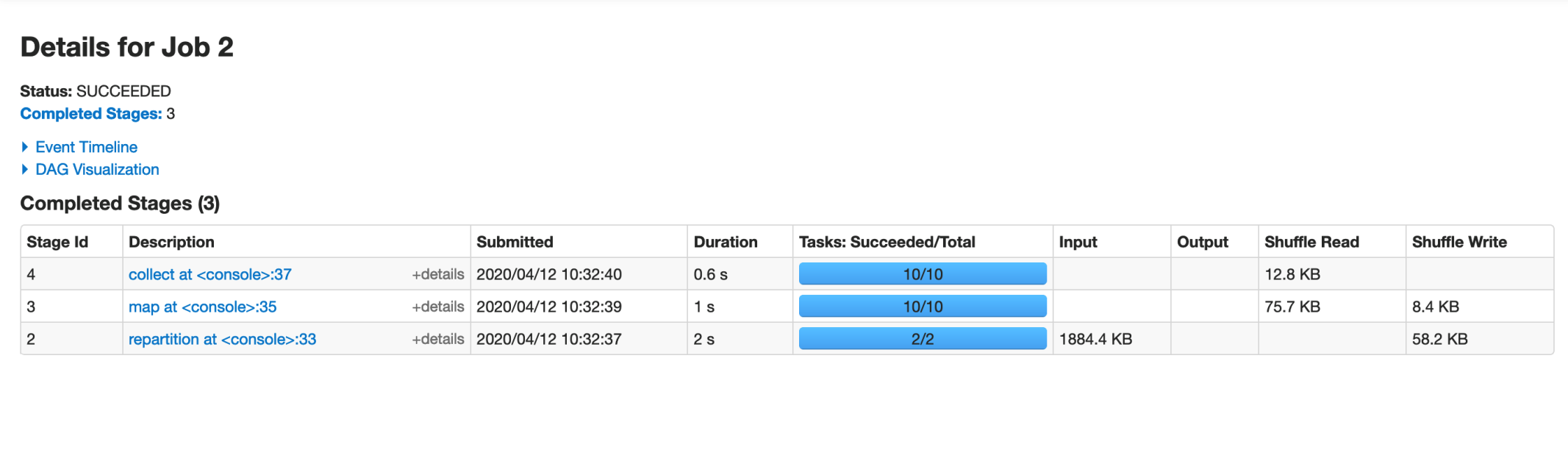
As we created 10 partitions, the last two stages are spawning 10 tasks.
Example #2 – On Dataframes
Let’s consider the same problem as example 1, but this time we are going to solve using dataframes and spark-sql.
Code:
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
valinputSchema = StructType(Array(
StructField("date",StringType,true),
StructField("county",StringType,true),
StructField("state",StringType,true),
StructField("fips",LongType,true),
StructField("cases",LongType,true),
StructField("deaths",LongType,true)
))
valinpPath="https://cdn.educba.com/home/hadoop/work/arindam/us-counties.csv"
valdf = spark.read.option("header",true).schema(inputSchema).csv(inpPath)
df.show(5,false) //printing 5 rows
println("No of partitions in df: "+ df.rdd.getNumPartitions)
valnewDf = df.repartition(10)
println("No of partitions in newDf: "+ newDf.rdd.getNumPartitions)
newDf.createOrReplaceTempView("tempTable")
spark.sql("select state,SUM(cases) as cases from tempTable where date='2020-04-10' group by state order by cases desc").show(10,false)
Here we created a schema first. Then while reading the csv file we imposed the defined schema in order to create a dataframe. Then, we called the repartition method and changed the partitions to 10. After this, we registered the dataframenewDf as a temp table. Finally, we wrote a spark sql query to get the required result. Please note that we don’t have any method to get the number of partitions from a dataframe directly. We have to convert a dataframe to RDD and then call the getNumPartitions method to get the number of partitions available.
Output:
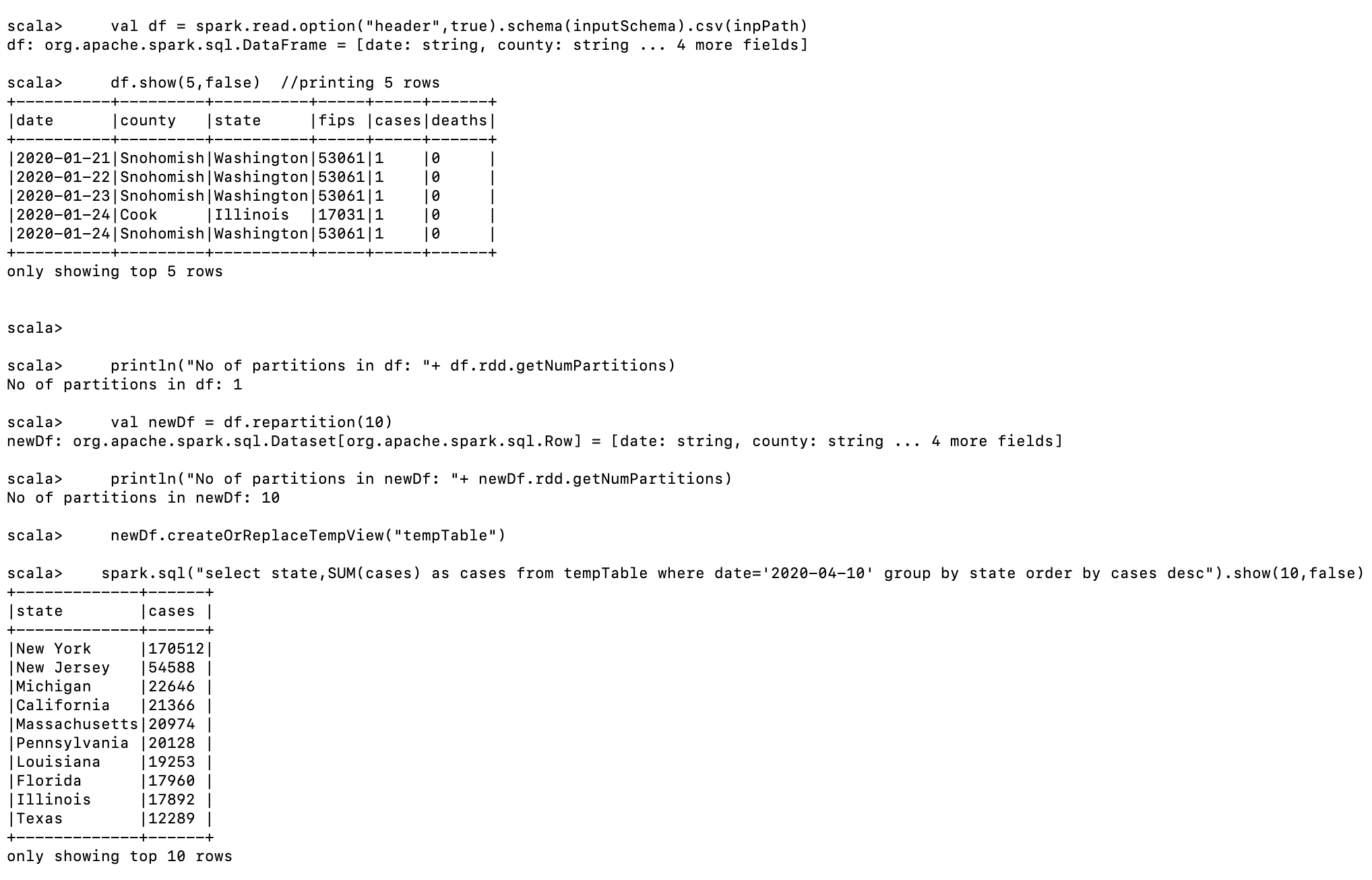
We are printing only top-ten states here and the results are matching with that calculated in the previous example.
Recommended Articles
This is a guide to Spark Repartition. Here we also discuss the introduction and how to use spark repartition along with different examples and its code implementation. you may also have a look at the following articles to learn more –
