
Introduction to Spark Parquet
Parquet is supported by a lot of data processing systems. It is a combat format. A deep integral part of analytics of a Spark – driven is defined as a parquet. The advantages are strong in relating to parquet. Those of which include Storage efficiency, fast, query efficient data, and a few tools accompanying them. Costing in communication (Input and output bound) and Decoding the data (CPU bound) are major bottlenecks of distribution analytics that have been overcome using Spark SQL Parquet. Reading and writing the files of Parquet is provided by Spark SQL support. And they automatically capture the original data scheme.
Syntax:
spark.write.parquet()
This is the syntax for the Spark Parquet Data frame.
How Apache Spark Parquet Works?
Binary is the format used in Parquet. Parquet format is basically encoded and compressed. The files used are columnar. This SQL of Spark is machine friendly. JVM, Hadoop, and C++ are the APIs used. Let us consider an example while understanding Apache Spark Parquet. Before heading towards it, first, we need to create a Data frame for Spark from the Seq object. Only when one imports implicits using the toDF() data frame function on sequence comes into availability which is – spark.sqlContext.implicits._
val entry = Seq(("John ","Hen","Kennedy","36636","M",8000),
("Michael ","","Rose","40288","F",10000),
("Robert ","Patrick","Williams","42114","M",5000),
(" ","Anne","Frank","39192","F",9000),
("Robert","Downey","Junior","","M",12554678966351))
val cols = Seq("first_name","mid_name","last_name","date of birth","gender","income")
import spark.sqlContext.implicits._
val dataframe_ = entry.toDF(cols:_*)
1. A data frame wiring for a parquet file:
df.write.parquet(“C:temp/file_output/persoal.parquet”)
2. All the columns are converted to be nullable automatically for compatibility reasons. Data entry in Parquet preserves the data types and names of the columns. Also, finalized by writing all the data to a specified folder. A data frame creation for a parquet file:
val parquet.data.frame = spark.read.parquet(“C:temp/file_output/personal.parquet”)
3. Query of a SQL usage for a parquet file: Temporary views of a Parquet can also be created and are used in statements of SQL.
parquet.data.frame.createOrReplaceViewTemp(“Table.Of.Parquet”)
val parquet.SQL = spar.sql(“select from table.of.parquet where income >=4000 ”)
4. File scan with a bottleneck performance is done by the above predicate on Parquet files, as of traditional database table scan. Using partitions to improve performance is a necessity.
5. Improving performance through Partitioning: Spark jobs working at scalable areas is caused by Partitioning as it is a feature of many databases and frameworks of data processing.
data.fram.write.partitionBy(“gender”, “income”)spark.read.parquet(“C:temp/file_output/personal2.parquet”)
Hierarchy of a partition folder is created as shown in the below picture:
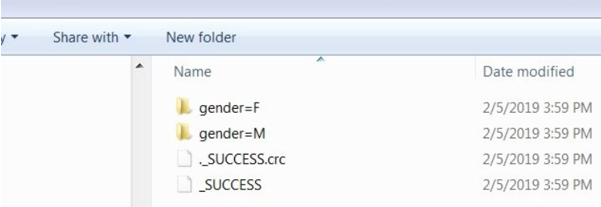
The above can be considered as an example for knowing how to write a data frame for Spark SQL into files of Parquet which preserves the partitions in columns of gender and income.
val parquet.data.frame = spark.read.parquet(“C:temp/file_output/personal.parquet”)
parquet.data.frame.createOrReplaceViewTemp(“Table2.Of.Parquet”)val parquet.SQL = spar.sql(“select from table.of.parquet where gender = ‘MALE’ and income >=4000 ”)
Execution without partition of the query is much easier and faster than the no partition query. Reading of specific partition from SQL parquet:
val parquet.data.frame = spark.read.parquet(“C:temp/file_output/personal2.parquet / gender = ‘Male’”)
This helps in retrieving the data from the partition of gender males.
Output:

Advantages
Advantages and uses to be noted about Apache Parquet in Spark:
- Input-output operation storage limits by columnar.
- Fetching of specific columns that one needs to access by column storage.
- Less storage space is consumed by columnar storage.
- Better summarization of data is done by columnar storage along with type-specific encoding.
Conclusion
We have seen the concept of Shuffle in Spark Architecture. Shuffle operation is pretty swift and sorting is not at all required. Sometimes no hash table is to be maintained. When included with a map, a small amount of data or files are created on the map side. Random Input-output operations, small amounts are required, most of it is sequential read and writes.
Recommended Articles
This is a guide to Spark Parquet. Here we discuss an introduction to Spark Parquet, syntax, how does it works with examples to implement. You can also go through our other related articles to learn more –
