Updated March 21, 2023

Introduction to Spark Dataset
Spark Dataset is one of the basic data structures by SparkSQL. It helps in storing the intermediate data for spark data processing. Spark dataset with row type is very similar to Data frames that work as a tabular form on the Resilient distributed dataset(RDD). The Datasets in Spark are known for their specific features such as type-safety, immutability, schemas, performance optimization, lazy evaluation, Serialization, and Garbage Collection. The Datasets are supported through Scala and Java programming APIs. Spark’s dataset supports both compile-time safety and optimizations, making it a preferred choice for implementation in the spark framework.
Why do we need Spark Dataset?
To have a clear understanding of Dataset, we must begin with a bit of the history of spark and evolution.
RDD is the core of Spark. Inspired by SQL and to make things easier, Dataframe was created on top of RDD. Dataframe is equivalent to a table in a relational database or a DataFrame in Python.
RDD provides compile-time type safety, but there is an absence of automatic optimization in RDD.
Dataframe provides automatic optimization, but it lacks compile-time type safety.
Dataset is added as an extension of the Dataframe. Dataset combines both RDD features (i.e. compile-time type safety ) and Dataframe (i.e. Spark SQL automatic optimization ).
[RDD(Spark 1.0)] -> [Dataframe(Spark1.3)] -> [Dataset(Spark1.6)]
As Dataset has compile-time safety, it is only supported in a compiled language( Java & Scala ) but not in an interpreted language(R & Python). But Spark Dataframe API is available in all four languages( Java, Scala, Python & R ) supported by Spark.
| Language supported by Spark. | Dataframe API | Dataset API |
| Compiled Language (Java & Scala) | YES | YES |
| Interpreted Language (R & Python) | YES | NO |
How to Create a Spark Dataset?
There are multiple ways of creating a Dataset based on the use cases.
1. First Create SparkSession
SparkSession is a single entry point to a spark application that allows interacting with underlying Spark functionality and programming Spark with DataFrame and Dataset APIs.
val spark = SparkSession
.builder()
.appName("SparkDatasetExample")
.enableHiveSupport()
.getOrCreate()
- To create a dataset using basic data structure like Range, Sequence, List, etc.:
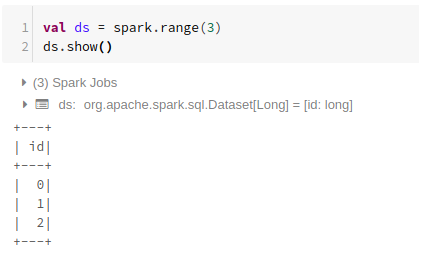
Using Range
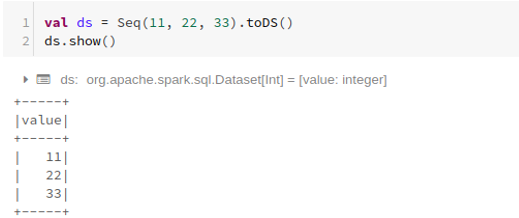
Using Sequence
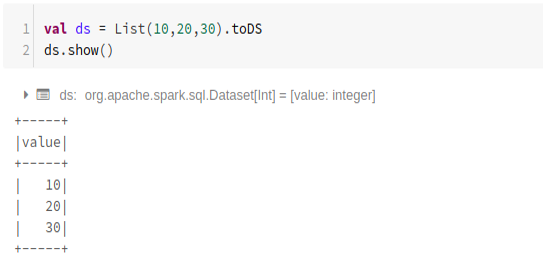
Using List
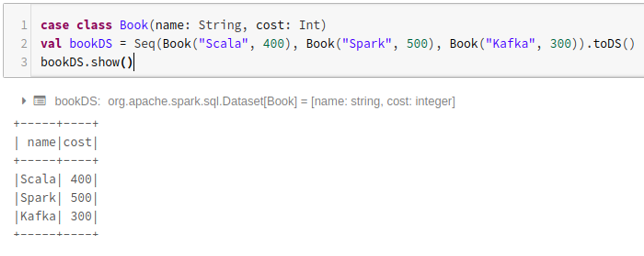
- To create a dataset using the sequence of case classes by calling the .toDS() method :
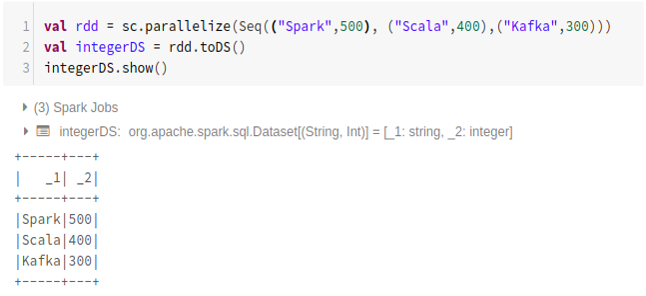
- To create dataset from RDD using .toDS():
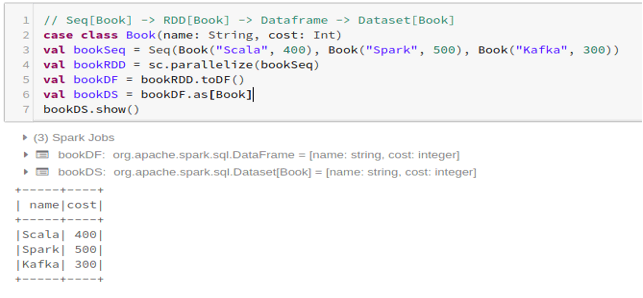
- To create the dataset from Dataframe using Case Class:
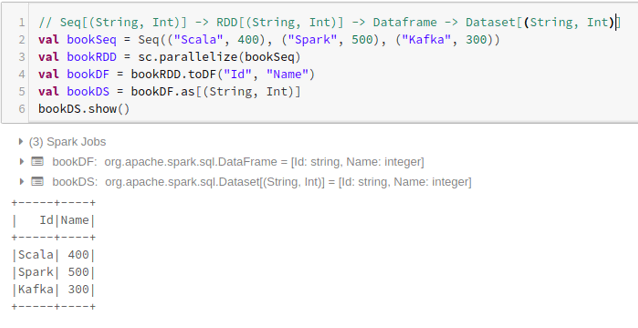
- To create the dataset from Dataframe using Tuples :
2. Operations on Spark Dataset
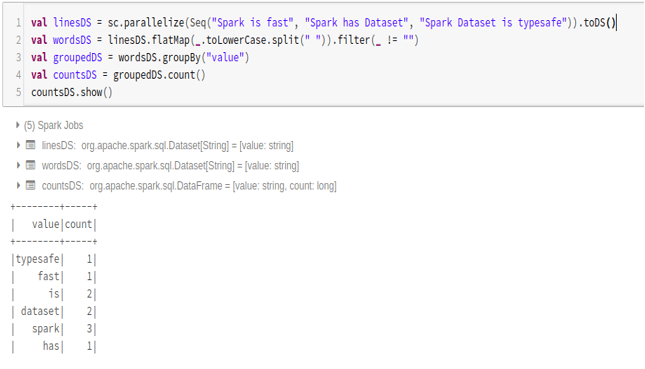
1. Word Count Example
2. Convert Spark Dataset to Dataframe
We can also convert Spark Dataset to Datafame and utilize Dataframe APIs as below :
Features of Spark Dataset
Below are the different features mentioned:
1. Type Safety: Dataset provides compile-time type safety. It means that the application’s syntax and analysis errors will be checked at compile time before it runs.
2. Immutability: Dataset is also immutable like RDD and Dataframe. It means we can not change the created Dataset. Every time a new dataset is created when any transformation is applied to the dataset.
3. Schema: Dataset is an in-memory tabular structure that has rows and named columns.
4. Performance and Optimization: Like Dataframe, the Dataset also uses Catalyst Optimization to generate an optimized logical and physical query plan.
5. Programming language: The dataset api is only present in Java and Scala, which are compiled languages but not in Python, which is an interpreted language.
6. Lazy Evaluation: Like RDD and Dataframe, the Dataset also performs the lazy evaluation. It means the computation happens only when action is performed. Spark makes only plans during the transformation phase.
7. Serialization and Garbage Collection: The spark dataset does not use standard serializers(Kryo or Java serialization). Instead, it uses Tungsten’s fast in-memory encoders, which understand the internal structure of the data and can efficiently transform objects into internal binary storage. It uses off-heap data serialization using a Tungsten encoder, and hence there is no need for garbage collection.
Conclusion
Dataset is the best of both RDD and Dataframe. RDD provides compile-time type safety, but there is an absence of automatic optimization. Dataframe provides automatic optimization, but it lacks compile-time type safety. Dataset provides both compile-time type safety as well as automatic optimization. Hence, the dataset is the best choice for Spark developers using Java or Scala.
Recommended Articles
This is a guide to Spark Dataset. Here we discuss How to Create a Spark Dataset in multiple ways with Examples and Features. You may also have a look at the following articles to learn more –
