Updated June 16, 2023
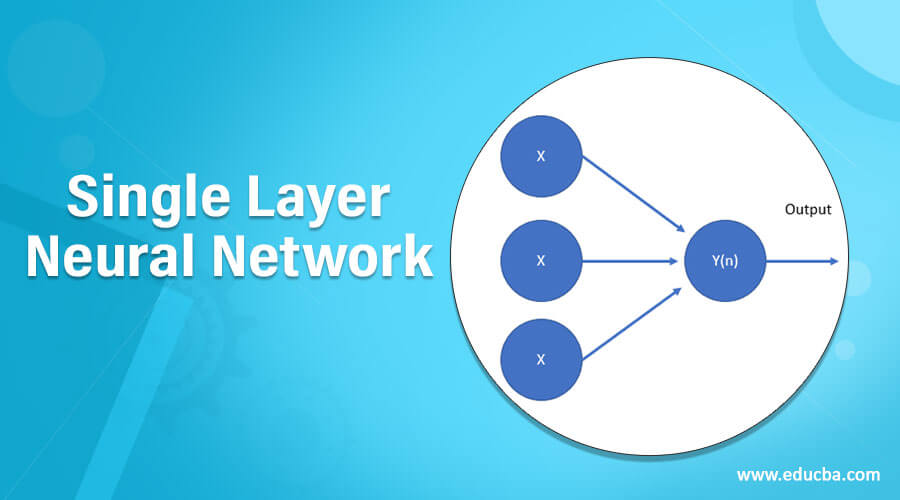
Introduction to Single Layer Neural Network
A single-layered neural network may be a network within which there’s just one layer of input nodes that send input to the next layers of the receiving nodes.
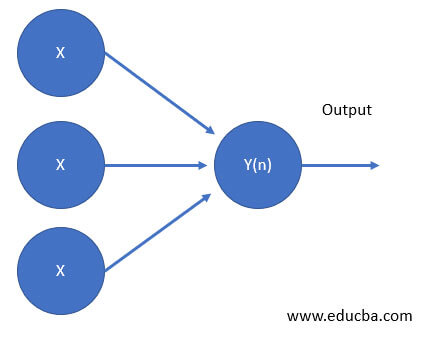
A single-layer neural network will figure a nonstop output rather than a step to operate. a standard alternative is that the supposed supply operates.
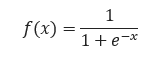
The single-layer network closely resembles the supply regression model, a widely used applied mathematics modeling technique. The supply operation, also known as the sigmoid operation, is an essential component of this network. It is a continuous derivative that enables its use in backpropagation.
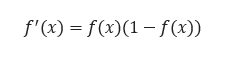
If single-layer neural network activation operates in Mod1 then this network will solve XOR downside with precisely ONE somatic cell.
![]()
The neural network that consists of a single-layer neural network is termed perceptron. The computation of a single-layer perceptron involves calculating the dot product of the input vector and the corresponding weights vector and then applying an activation function to the result. The output value represents the activation of the neural network.
We can illustrate the only layer perceptron by illustrating the supply regression.
The basic steps for supply regression are:
At the start of the training, the weights are initialized with random values for each component of the training set. The error is then calculated by comparing the desired output with the actual output. This calculated error is used to adjust the weights.
The algorithmic coaching rule for the perceptron network and maybe a straightforward theme for the repetitious determination of the load vector W.
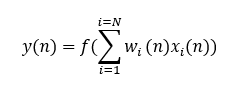
Where f(x) = +1 if x ≥ 0, f(x) = -1 if x ≤ 0
This is the arduous limiting non-linearity, and n is the iteration index.
Connection weights area unit updated in keeping with:
![]()
Where is a positive gain factor of less than 1.
And d(n) =+1 if input is class 1, d(n) = – if input is class 2.
The perceptron convergence procedure doesn’t adapt the weights if the output call is correct.
Suppose the output call disagrees with the binary desired response d(n). That is, they will solely learn linearly severable patterns. Linearly severable patterns area unit datasets or functions that a linear boundary may separate.
The XOR, or “exclusive or”, operate may be a straightforward operation on 2 binary inputs and is commonly found in bit-twiddling hacks.
These functions don’t seem to be linearly severable; thus, what’s required is AN extension to the perceptron. The plain extension is to feature a lot of layers of units, so there are nonlinear unit computations in between the input and output.
For a long time, many in the field assumed that adding more layers of units would not be able to solve the linearly separable problem.
One of the foremost essential tasks in supervised machine learning algorithms is attenuating value operations.
Gradient descent is one in every one of the numerous algorithms that enjoy feature scaling. We will use a feature scaling methodology called standardization, which provides our information on the property of a typical distribution. Feature standardization makes the values of every feature within the information have zero mean and unit variance.
Hard customary scores generally do this.
The general calculation methodology determines the distribution mean and variance for every feature. Next, we tend to work out the mean from every feature. Then we tend to divide the values of every feature by its variance.
Conclusion
- In this, we have discussed the single neural network.
- How neural network works Limitations of neural network
- Gradient descent
Recommended Articles
This is a guide to Single Layer Neural Networks. Here we discuss How neural network works with the Limitations of neural network and How it is represented. You may also have a look at the following articles to learn more –
