Updated March 27, 2023

Introduction to Regularization Machine Learning
The following article provides an outline for Regularization Machine Learning. Regularization is that the method of adding data so as to resolve an ill-posed drawback or to forestall overfitting. It applies to objective functions in ill-posed improvement issues. Often, a regression model overfits the information it’s coaching upon. During the method of regularization, we tend to try and cut back the complexness of the regression operate while not really reducing the degree of the underlying polynomial operate. Regularization are often intended as a method to enhance the generalizability of a learned model.
Some more about Regularization Machine Learning:
- Regularization is even for classification. As classifiers is usually an undetermined drawback because it tries to infer to operate of any x given.
- The term regularization is additionally supplementary to a loss operate.
- Regularization will serve multiple functions, together with learning easier models to be distributed and introducing cluster structure into the educational drawback.
- The goal of this learning drawback is to seek out to operate that matches or predicts the result that minimizes the expected error overall potential inputs and labels.
Tikhonov Regularization
Tikhonov regularization is often employed in a subsequent manner.
Forward an un-regularized loss-function l_0 (for instance total of square errors) and model parameters w, the regular loss operate becomes:
![]()
In the case of L2-regularization, L takes the shape of scalar times the unit matrix or the total of squares of the weights.
Some usually used Regularization techniques includes:

- L1 Regularization
- L2 Regularization
- Early Stopping
- Dropout Regularization
- Training knowledge Augmentation
- Batch Standardization
1. Lasso Regularization (L1 Regularization)
Regularization or Lasso Regularization adds a penalty to the error operate. The penalty is that the total of absolutely the values of weights.
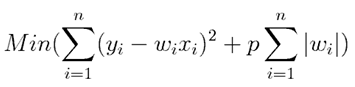
p is that the standardization parameter that decides what proportion we wish to penalize the model.
This lasso regularization is additionally referred to as L1 regularization.
2. Ridge Regularization (L2 Regularization)
L2 Regularization or Ridge Regularization conjointly add a penalty to the error operate. However, the penalty here is that the total of the squared values of weights.
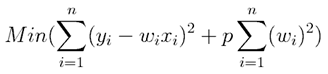
p is that the standardization parameter that decides what proportion we wish to penalize the model.
This ridge regularization is additionally referred to as L2 regularization.
The distinction between these each technique is that lasso shrinks the slighter options constant to zero so, removing some feature altogether. So, this works well for feature choice just in case we’ve got a vast range of options.
3. Early Stopping Regularization
Early stopping is that the thought accustomed forestall overfitting. In this, the information set is employed to reckon the loss operate at the top of every coaching epoch, and once the loss stops decreasing, stop the coaching and use the check knowledge to reckon the ultimate classification accuracy. Early stopping are often employed by itself or during a combination with the regularization techniques.
The best ending are often thought of because the hyper parameter, thus effectively we tend to test out multiple values of the hyper parameter throughout the course of one coaching run. This makes early stopping a lot of economical than different hoopla parameter improvement techniques which usually need a whole run of the model to check out one hype parameter worth. Early stopping could be a fairly un-obtrusive variety of regularization, since it doesn’t need any amendments to the model or objective to operate which may change the educational dynamics of the system.
4. Dropout Regularization
Dropout is one in every of the foremost effective regularization techniques to possess emerged within a previous couple of years. The fundamental plan behind the dropout is to run every iteration of the scenery formula on haphazardly changed versions of the first DLN.
- Dropout forces a neural network to be told a lot of sturdy options that are helpful in conjunction with many alternative random subsets of the opposite neurons.
- Dropout roughly doubles the number of iterations needed to converge. However, coaching time for every epoch is a smaller amount.
- With H hidden units, every of which may be born, we have
2^H potential models. In the testing part, the complete network is taken into account and every activation is reduced by an element p.
5. Training Knowledge Augmentation
If the information set used for coaching isn’t giant enough, that is commonly the case for several real-world check sets, then it will result in overfitting. A straightforward technique to induce around this drawback is by artificial means increasing the coaching set.
We would be able to subject a picture to the subsequent transformation while not dynamical its classification:
- Translation
- Rotation
- Reflection
- Skewing
- Scaling
- Changing Distinction or Brightness
All these transformations are of the kind that the human eye is employed to experience. but there are different augmentation techniques that don’t constitute this category, like adding random noise to the coaching knowledge set that is additionally terribly effective as long because it is finished rigorously.
6. Batch Normalization
Data standardization at the input layer could be a manner of reworking the information so as to hurry up the improvement method. Since standardization is therefore useful, why not extend it to the inside of the network and normalize all activations. This can be exactly what’s wiped out of the formula referred to as Batch standardization.
It was a simple exercise to use the standardization operations to the computer file since the complete coaching knowledge set is accessible at the beginning of the coaching method. This can be not cased with the hidden layer activations, since these values amendment over the course of the coaching because of the formula-driven updates of system parameters. Ioffe and Szegady resolved this drawback by doing the standardization in batches (hence the name), such throughout every batch the parameters stay fastened.
Conclusion – Regularization Machine Learning
Regularization introduces a penalty for exploring bound regions of the operate area accustomed build the model, which may improve generalization. Overfitting could be a development that happens once a model learns the detail and noise within the coaching knowledge to an extent that it negatively impacts the performance of the model on the new knowledge.
Recommended Articles
This is a guide to Regularization Machine Learning. Here we discuss the introduction to regularization machine learning along with the different types of regularization techniques. You may also have a look at the following articles to learn more –
