Updated March 8, 2023
Difference Between Presto vs Hive
Apache Hive is a Data Warehousing solution that runs on top of Apache Hadoop and allows you to query and analyze big datasets with ease. Hive queries data using a SQL-like approach, making it simple to explore and analyze large amounts of data.
Presto is a distributed SQL query engine that can query data from Hadoop, S3, MySQL, Teradata, and other relational and non-relational databases. Facebook created Presto to conduct queries against numerous data stores with response times varying from a fraction of a second to minutes.
Both Apache Hive and Presto allow enterprises to run queries on business data, but they have several distinguishing features that make them unique.
1. Memory Architecture processes between Hive and Presto
Presto is optimized for latency, while Hive is optimized for query throughput. Presto has a limit on just how much memory each task in a query may hold, thus if a query demands a large amount of memory, the query will fail. For interactive queries, such error handling logic (or a lack thereof) is fine; however, for daily/weekly reports that must execute reliably, it is not. Hive is a superior option for such activities.
Hive uses MapReduce. Each operation in MapReduce necessitates writing to disc, and each stage must wait for the preceding stage to finish before proceeding. Because MapReduce can process tasks across numerous servers, it works well in Hive. The speed of a project can be increased by distributing tasks. Even still, the data must be written to a disc, which may irritate some users.
While Presto translates SQL to stage, each stage is executed by numerous tasks, and each task is partitioned into several splits. All tasks are completed in parallel, and data is sent between phases via a pipeline. Memory –to- Memory across the network is also used to transmit data, eliminating the need for a disc input-output transaction.
Presto’s performance is 5-10 times faster than Hive’s because of this.
2. ANSI SQL and SQL-like language called HiveQL
Although Apache Hive utilizes a language that is close to SQL, there are enough differences that new users will have to retrain some queries. HiveQL, or Hive Query Language, contains a few quirks that may be confusing to newcomers. Anyone who is familiar with SQL, on the other hand, should be able to take up HiveQL very fast.
When many data engineers first try Presto, one of the first things they notice is that they can use their existing SQL skills. Presto executes queries, retrieves data, and modifies data in databases using ordinary SQL. You may start working with Presto right away if you know SQL. Many people consider this to be a benefit.
3. Expanding Arrays and Maps
The LATERAL VIEW (in Hive) statement flattens the map or array type of a column when used with user-defined table generating functions like explode(). With LATERAL VIEW, the explode function can be used on both ARRAY and MAP.
UNNEST can be used to expand a MAP or ARRAY. Arrays are collapsed into a single column, while maps are split into two (key, value). UNNEST is usually used in conjunction with a JOIN, and it can relate to columns from relations on the left side of the join.
Hive query:
SELECT student, mark
FROM tests
LATERAL VIEW explode(marks) t AS mark;
Presto query:
SELECT student, mark
FROM tests
Cross Join UNNEST explode(marks) t AS mark;
4. Custom code Plugins
Since Presto is based on SQL, you already have all of the commands you’ll need. Some engineers regard this as a benefit because it allows them to easily retrieve and modify data.
However, the inability to insert custom code can cause issues for expert large data users. Hive has an advantage over Presto in this scenario. You can put custom code into your queries if you know the language well. It’s not something you’ll need to do all the time, but it’ll come in handy when you do.
5. Hour Limit for Presto Queries
Presto queries that have been running for more than 48 hours will be immediately terminated. Presto queries that run for more than a day or two are usually unsuccessful queries.
You can rebuild the Presto query as a Hive query for long-running queries.
6. Colum name escaping
When the name of a column matches the name of a reserved keyword, the column name must be quoted. The quotation character in Hive, like most SQL-based query languages, is the backtick character `. Instead of `, the double-quote character “, is used to quote a column name in Presto. Consider the following example:
SELECT `join` FROM Demo # Hive
SELECT "join" FROM Demo # Presto
7. Data Limitations
Unfortunately, the quantity of data that Presto jobs can store is limited. Presto’s rationale crumbles once you meet that wall. You can almost likely rely on Presto to perform a good job generating hourly or daily reports. Keep in mind that Facebook makes use of Presto and creates massive volumes of data. However, there is a limit.
Hive does not appear to have any data limitations, at least none that are relevant to real-world scenarios. For businesses that produce weekly or monthly reports, Hive is the preferable data query solution. The project will take longer if there is a lot of data involved. Hive, on the other hand, will not fail. It will continue to work until it has completed all of your commands.
Head to Head Comparison between Presto vs Hive (Infographics)
Below are the top differences between Presto vs Hive:
Key Differences
- Presto does not allow users to plug in custom code, but Hive allows.
- Presto uses ANSI SQL, while Hive uses HiveQL
- Presto can only handle a limited amount of data, thus for larger data, it’s advisable to use Hive.
Comparison Table of Hive vs Presto
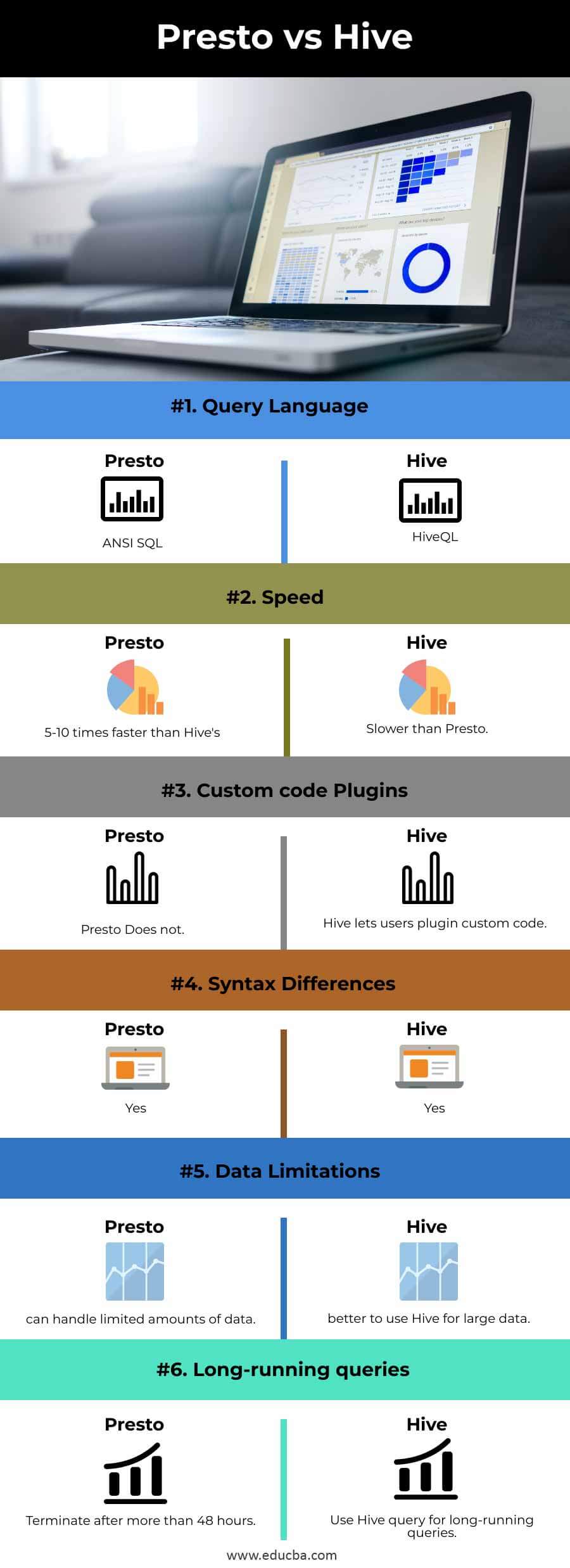
| Basis | Hive | Presto |
| Query Language | ANSI SQL | HiveQL |
| Speed | 5-10 times faster than Hive’s | Slower than Presto |
| Custom code Plugins | Presto Does not | Hive lets users plugin custom code |
| Syntax differences | Yes | Yes |
| Data Limitations | can handle limited amounts of data | better to use Hive for large data |
| long-running queries | Terminate after more than 48 hours | Use Hive query for long-running queries |
Conclusion – Presto vs Hive
Just because some individuals prefer Hive, it doesn’t mean you should overlook Presto. When utilized correctly, it performs admirably. Presto is a task-processing system that works swiftly. Just don’t put too much pressure on it at once. You face the chance of failing if you do so. Also, Apache Hive and Presto are both open-source tools, so the source code for each one is available for free.
Recommended Articles
This is a guide to Presto vs Hive. Here we discuss the Presto vs Hive key differences with infographics and comparison table. You may also have a look at the following articles to learn more –
