Updated June 20, 2023

Introduction to Pandas Find Duplicates
Dealing with real-world data can be messy and overwhelming at times, as the data is never perfect. It consists of many problems, such as outliers, duplicates, missing values, etc. There is a very popular fact in the data science world that data scientists/data analysts spend 80% of their time in data cleaning and preparation for a machine learning algorithm. In this article, we will be covering a very popular problem, that is, how to find and remove duplicate values/records in a pandas dataframe. Pandas module in Python provides us with some in-built functions such as dataframe.duplicated() to find duplicate values and dataframe.drop_duplicates() to drop duplicate values. We will be discussing these functions along with others in detail in the subsequent sections.
Syntax and Parameters
The basic syntax for dataframe.duplicated() function is as follows :
dataframe.duplicated(subset = 'column_name', keep = {'last', 'first', 'false')The parameters used in the above-mentioned function are as follows :
- Dataframe: Name of the dataframe for which we must find duplicate values.
- Subset: Name of the specific column or label based on which duplicate values have to be found.
- Keep: While finding duplicate values, which occurrence of the value has to be marked as duplicate.
The subset argument is optional. Having understood the dataframe.duplicated() function to find duplicate records, let us discuss dataframe.drop_duplicates() to remove duplicate values in the dataframe.
The basic syntax for dataframe.drop_duplicates() function is similar to duplicated() function. It can be written as follows :
dataframe.drop_duplicates(subset = 'column_name', keep = {'last', 'first', 'false'}, inplace = {'True', 'False'})Inplace: Inplace ensures if the changes are to be made in the original data frame(True) or not(False).
Examples of Pandas Find Duplicates
Now we have discussed the syntax and arguments used for working with functions for dealing with duplicate records in pandas. But no learning is complete without some practical examples; ergo, let’s try a few examples based on these functions. In order to do that, we must first create a dataframe with duplicate records. You may use the following data frame for the purpose.
Code:
#importing pandas
import pandas as pd
#input data
data = {'Country': ['India','India','USA','USA','UK','Germany','India','Germany', 'USA', 'China', 'Japan'],
'Personality': ['Sachin Tendulkar','Sania Mirza','Serena Williams','Venus Willians',
'Morgan Freeman','Michael Schumacher','Priyanka Chopra','Michael Schumacher',
'Serena Williams','Jack Ma','Sakamoto Ryoma']
}
#create a dataframe from the data
df = pd.DataFrame(data, columns = ['Country','Personality'])
#print dataframe
dfThe output of the given code snippet would be a data frame called ‘df’ as shown below :
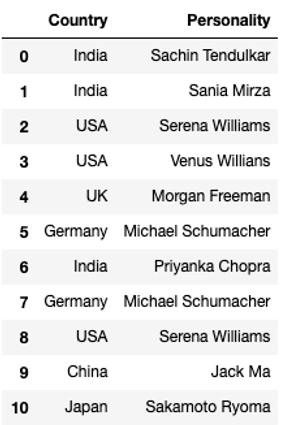
Duplicate Values of Data Frame
We can clearly see that there are a few duplicate values in the data frame.
1. Finding Duplicate Values in the Entire Dataset
In order to find duplicate values in pandas, we use df.duplicated() function. The function returns a series of boolean values depicting whether a record is duplicated.
df.duplicated()
By default, when considering the entire record as input, values in a list are marked as duplicates based on their subsequent occurrence.
2. Finding a Specific Column
In the previous example, we used the duplicated() function without any arguments. Here, we have used the function with a subset argument to find duplicate values in the countries column.
df.duplicated(subset = 'Country')
3. Finding in a Specific Column and Marking Last Occurrence as Not Duplicate
df.duplicated(subset = 'Country', keep = 'last')
4. Finding the Count of Duplicate Records in the Entire Dataset
In order to find the total number of values, we can perform a sum operation on the results obtained from the duplicated() function, as shown below.
df.duplicated().sum()![]()
5. Finding the Count of Duplicate Values in a Specific Column
df.duplicated(subset='Country').sum()![]()
6. Removing Duplicate Records in the Dataset.
df.drop_duplicates(keep = 'first')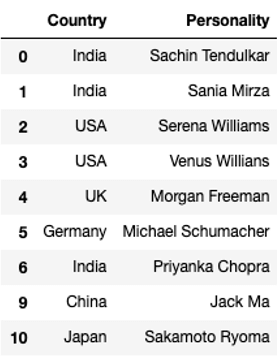
The function has successfully removed records no. 7 and 8 as they were duplicated. We should note that the drop_duplicates() function does not make inplace changes by default.
df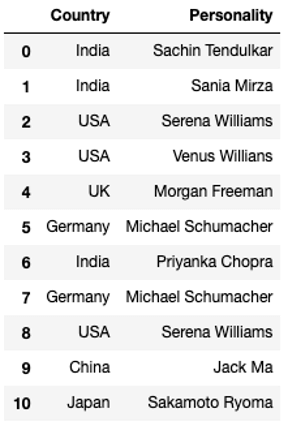
The original data frame is still the same with duplicate records. In order to save changes to the original dataframe, we have to use an inplace argument, as shown in the next example.
7. Removing Duplicate Records in the Dataset Inplace.
df.drop_duplicates(keep = 'first', inplace = True)
df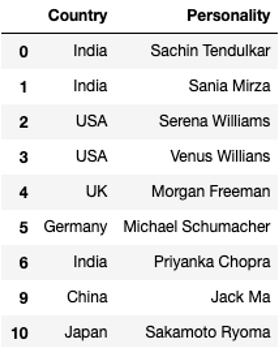
Conclusion
Finding and removing duplicate values can seem daunting for large datasets. But pandas have made it easy by providing us with some in-built functions such as dataframe.duplicated() to find duplicate values and dataframe.drop_duplicates() to remove duplicate values.
Recommended Articles
We hope that this EDUCBA information on “Pandas Find Duplicates” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

