Updated April 12, 2023

Introduction to Pandas Aggregate()
Pandas Aggregate() function is utilized to calculate the aggregate of multiple operations around a particular axis.
The syntax for aggregate() function in Pandas is,
Dataframe.aggregate(self, function, axis=0, **arguments, **keywordarguments)Where,
- A function is used for conglomerating the information. On the off chance that a capacity, should either work when passed a DataFrame or when gone to DataFrame.apply. The function can be of any type, be it string name or list of functions such as mean, sum, etc, or dictionary of axis labels.
- Axis function is by default set to 0 because we have to apply this function to all the indices in the specific row. If the axis is assigned to 1, it means that we have to apply this function to the columns.
- Arguments and keyword arguments are positional arguments to pass a function.
These aggregate functions are also termed as agg(). The agg() work is utilized to total utilizing at least one task over the predetermined hub. It returns Scalar, Series, or Dataframe functions. When the return is scalar, series.agg is called by a single capacity. When the return is for series, dataframe.agg is called with a single capacity and when the return is for dataframes, dataframe.agg is called with several functions.
How Pandas aggregate() Functions Work?
Now we see how the aggregate() functions work in Pandas for different rows and columns. The aggregation tasks are constantly performed over a pivot, either the file (default) or the section hub. This conduct is not the same as numpy total capacities (mean, middle, nudge, total, sexually transmitted disease, var), where the default is to figure the accumulation of the leveled exhibit, e.g., numpy.mean(arr_2d) instead of numpy.mean(arr_2d, axis=0).
Example #1 – Use aggregate() function on the rows
Code:
import numpy as np
import pandas as pd
df = pd.DataFrame([[1, 2, 3],
[5, 4, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['S', 'P', 'A'])
df.agg(['sum', 'min'])
print(df.agg(['sum', 'min']))Output:

In the above program, we initially import numpy as np and we import pandas as pd and create a dataframe. The program here is to calculate the sum and minimum of these particular rows by utilizing the aggregate() function. This only performs the aggregate() operations for the rows. We first create the columns as S,P,A and finally provide the command to implement the sum and minimum of these rows and the output is produced.
Example #2 – Use Multiple aggregations for Every Column
Code:
import numpy as np
import pandas as pd
df = pd.DataFrame([[1, 2, 3],
[5, 4, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['S', 'P', 'A'])
df.agg({'S' : ['sum', 'min'], 'P' : ['min', 'max']})
print(df.agg({'S' : ['sum', 'min'], 'P' : ['min', 'max']}))Output:
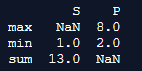
In the above code, we calculate the minimum and maximum values for multiple columns using the aggregate() functions in Pandas. We first import numpy as np and we import pandas as pd. We then create a dataframe and assign all the indices in that particular data frame as rows and columns. Then we add the command df.agg and assign which rows and columns we want to check the minimum, maximum, and sum values and print the function and the output is produced.
Example #3 – To utilize aggregate() function and calculate the mean of only columns
Code:
import numpy as np
import pandas as pd
df = pd.DataFrame([[1, 2, 3],
[5, 4, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['S', 'P', 'A'])
df.agg("mean", axis="columns")
print(df.agg("mean", axis="columns"))Output:
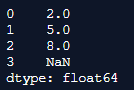
Here, similarly, we import the numpy and pandas functions as np and pd. Then we create the dataframe and assign all the indices to the respective rows and columns. Then here we want to calculate the mean of all the columns. Hence, we initialize axis as columns which means to say that by default the axis value is 1. Hence, we print the dataframe aggregate() function and the output is produced.
Conclusion
Python is an extraordinary language for doing information examination, principally in view of the phenomenal biological system of information-driven Python bundles. Pandas is one of those bundles and makes bringing in and investigating information a lot simpler. Dataframe.aggregate() work is utilized to apply some conglomeration across at least one section. Total utilizing callable, string, dictionary, or rundown of string/callable. Hence I would like to conclude by saying that, the word reference keys are utilized to determine the segments whereupon you would prefer to perform activities, and the word reference esteems to indicate the capacity to run. The aggregate() usefulness in Pandas is all around recorded in the official documents and performs at speeds on a standard (except if you have monstrous information and are fastidious with your milliseconds) with R’s data.table and dplyr libraries. Collecting capacities are the ones that lessen the element of the brought protests back. It implies yield Series/DataFrame has less or the same lines as unique.
Recommended Articles
We hope that this EDUCBA information on “Pandas Aggregate()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

