Updated April 3, 2023

Introduction to Pandas DataFrame.mean()
According to mathematical perceptions there are several ways to denote the word mean. The most common method to represent the term means is it is the sum of all the terms divided by the total number of terms. applying this formula gives the mean value for a given set of values. In pandas of python programming the value of the mean can be determined by using the Pandas DataFrame.mean() function. This function can be applied over a series or a data frame and the mean value for a given entity can be determined across specific access.
Syntax and Parameters
here is the syntax of Pandas DataFrame.mean():
Syntax:
DataFrame.mean(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)Parameters to Pandas DataFrame.mean()
Below are the parameters with explanation:
|
Parameter |
Description |
| axis | This argument represents the column or the axis upon which the mean function needs to be applied. The value specified in this argument represents either a column, position or location in a data frame. to achieve this capability to flexibly travel over a data frame the axis value is framed on below means, {index (0), columns (1)}. here mentioning the value of the 0 to axis argument gives the mean value for every row in the data frame, whereas mentioning the value of 1 in the data frame gives the mean value for all the columns in the data frame. |
| skip | The skip is another major argument in the mean() determination function. the skip as the argument name mentions it helps to determine whether a specific column in the data frame is comprising of null values and if these values need to be skipped in the mean calculation process then this column needs to be set. The process of setting this column or turning this column can be achieved by making the column value as ‘False’. So when this column is assigned with a value of ‘None’ then all none value columns or rows in the data frame will not be considered for mean value calculation. The default value of skip an argument is True. |
| level | if the axis is a MultiIndex (hierarchical), count along with a particular level, collapsing into a Series. |
| numeric_only | In most instances the values of a pandas series or data frame objects may not necessarily of a numeric format. This means there could be instances where the panda’s object like a series or data frame could be a combination of alphanumeric instances, so there could be string values in a pandas object. In those instances the numeric-only option comes into role. so this is another boolean option along with skip a where the default value will be none and setting this to true will skip all the string values in a series or a data frame from the consideration of mean calculation. options like this make the panda’s set up a very optimistic one for the data analysis process. numeric_only does not apply to series objects. |
Examples to Implement Pandas DataFrame.mean()
Here are some examples mentioned:
Example #1
Code:
import pandas as pd
Core_Series = pd.Series([ 10, 20, 30, 40, 50, 60])
print(" THE CORE SERIES ")
print(Core_Series)
Mean_value_series = Core_Series.mean()
print("")
print(" THE MEAN VALUE: ",Mean_value_series)Output:
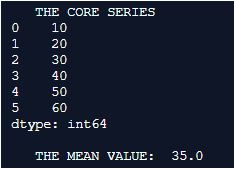
Explanation: Here the panda’s library is initially imported and the imported library is used for creating a series. The values in the series are formulated in such a way that they are a series of 10 to 60. the mean() method is used for determining the mean value of the series and print it on to the console. So on the current given series we can notice the mean value is been generated and printed precisely.
Example #2
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'A' : [ 1, 6, 11, 15, 21, 26],
'B' : [2, 7, 12, 17, 22, 27],
'C' : [3, 8, 13, 18, 23, 28],
'D' : [4, 9, 14, 19, 24, 29],
'E' : [5, 10, 15, 20, 25, 30]})
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
print(type(Core_Dataframe.A[0]))
Core_Dataframe_mean_row_level = Core_Dataframe.mean(axis= 0)
Core_Dataframe_mean_column_level = Core_Dataframe.mean(axis= 1)
print("")
print(" THE CORE DATAFRAME MEAN ROW LEVEL:",Core_Dataframe_mean_row_level)
print("")
print(" THE CORE DATAFRAME MEAN COLUMN LEVEL:",Core_Dataframe_mean_column_level)Output:
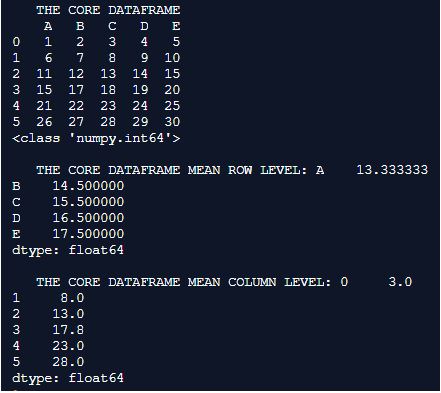
Explanation: Here the panda’s library is initially imported and the imported library is used for creating the data frame which is a shape(6,6). all of the columns in the data frame are assigned with headers that are alphabetic. the values in the data frame are formulated in such a way that they are a series of 1 to n. Here the data frame created is notified as a core data frame. The mean value of the core data frame is determined here in two different ways. this differentiation in mean value determination is attained using the axis param in the mean() method. So in the first instance the row-level mean value is generated by setting the axis value to 0. whereas in the second instance the column level mean value is determined by setting the axis value to 1. the mean at both these instances is precisely printed on to the console.
Example #3
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'A' : [10, 20, 'String_Value'],
'B' : [10, 20, 40],
'C' : [10, 20, 50],
'D' : [10, 'string_value', 50],
'E' : [10, 20, None]})
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
Normal_Mean = Core_Dataframe.mean()
Mean_when_numeric_turned_on = Core_Dataframe.mean(numeric_only = True)
Mean_when_None_skipped = Core_Dataframe.mean(skipna = False)
print("")
print(" MEAN VALUE OF DATAFRAME A ")
print(Normal_Mean)
print("")
print(" MEAN VALUE WHEN NON NUMERIC SKIPPED ")
print(Mean_when_numeric_turned_on)
print("")
print(" MEAN VALUE WHEN NONE ROWS ARE SKIPPED ")
print(Mean_when_None_skipped)Output:
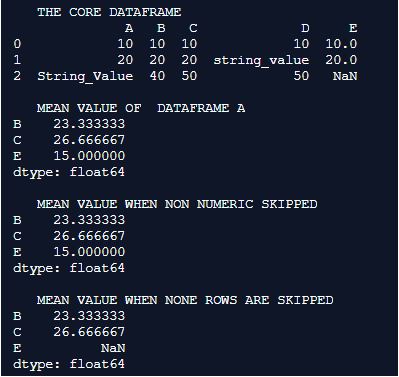
Explanation: The whole initial set of operations from the above example is repeated here again, Once the core data frame is been declared the datatype of each of the columns in the data frame are printed into the console, the mean values of the core data frame are calculated in three different ways here. in the first instance the mean value for the entire data frame is calculated without any arguments. in the second instance the mean value is calculated with the numeric-only set to ‘true’ and in the third instance the mean value is calculated with the skip a set to false. the outcome of the below process is printed on to the console.
Conclusion
The mean() method in pandas shows the flexibility of applying a mean operation over every value in the data frame in a most optimized way. It also depicts the classified set of arguments which can be associated with to mean() method of python pandas programming.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.mean()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

