
Introduction to Machine Learning Architecture
Machine Learning architecture is defined as the subject that has evolved from the concept of fantasy to the proof of reality. As earlier machine learning approach for pattern recognitions has lead foundation for the upcoming major artificial intelligence program. Based upon the different algorithm that is used on the training data machine learning architecture is categorized into three types i.e. Supervised Learning, Unsupervised Learning, and Reinforcement Learning and the process involved in this architecture are Data Aquisition, Data Processing, Model Engineering, Excursion, and Deployment.
Types of Machine Learning Architecture
The Machine Learning Architecture can be categorized on the basis of the algorithm used in training.
1. Supervised Learning
In supervised learning, the training data used for is a mathematical model that consists of both inputs and desired outputs. Each corresponding input has an assigned output which is also known as a supervisory signal. Through the available training matrix, the system is able to determine the relationship between the input and output and employ the same in subsequent inputs post-training to determine the corresponding output. The supervised learning can further be broadened into classification and regression analysis based on the output criteria. Classification analysis is presented when the outputs are restricted in nature and limited to a set of values. However, regression analysis defines a numerical range of values for the output. Examples of supervised learning are seen in face detection, speaker verification systems.
2. Unsupervised Learning
Unlike supervised learning, unsupervised learning uses training data that does not contain output. The unsupervised learning identifies relation input based on trends, commonalities, and the output is determined on the basis of the presence/absence of such trends in the user input.
3. Reinforcement Training
This is used in training the system to decide on a particular relevance context using various algorithms to determine the correct approach in the context of the present state. These are widely used in training gaming portals to work on user inputs accordingly.
Architecting the Machine Learning Process
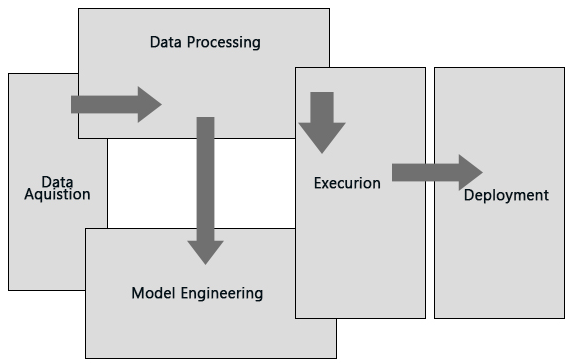
Fig:- Block diagram of decision flow architecture for Machine learning systems,
Let us now try to understand the layers represented in the image above.
1. Data Acquisition
As machine learning is based on available data for the system to make a decision hence the first step defined in the architecture is data acquisition. This involves data collection, preparing and segregating the case scenarios based on certain features involved with the decision making cycle and forwarding the data to the processing unit for carrying out further categorization. This stage is sometimes called the data preprocessing stage. The data model expects reliable, fast and elastic data which may be discrete or continuous in nature. The data is then passed into stream processing systems (for continuous data) and stored in batch data warehouses (for discrete data) before being passed on to data modeling or processing stages.
2. Data Processing
The received data in the data acquisition layer is then sent forward to the data processing layer where it is subjected to advanced integration and processing and involves normalization of the data, data cleaning, transformation, and encoding. The data processing is also dependent on the type of learning being used. For e.g., if supervised learning is being used the data shall be needed to be segregated into multiple steps of sample data required for training of the system and the data thus created is called training sample data or simply training data. Also, the data processing is dependent upon the kind of processing required and may involve choices ranging from action upon continuous data which will involve the use of specific function-based architecture, for example, lambda architecture, Also it might involve action upon discrete data which may require memory-bound processing. The data processing layer defines if the memory processing shall be done to data in transit or in rest.
3. Data Modeling
This layer of the architecture involves the selection of different algorithms that might adapt the system to address the problem for which the learning is being devised, These algorithms are being evolved or being inherited from a set of libraries. The algorithms are used to model the data accordingly, this makes the system ready for the execution step.
4. Execution
This stage in machine learning is where the experimentation is done, testing is involved and tunings are performed. The general goal behind being to optimize the algorithm in order to extract the required machine outcome and maximize the system performance, The output of the step is a refined solution capable of providing the required data for the machine to make decisions.
5. Deployment
Like any other software output, ML outputs need to be operationalized or be forwarded for further exploratory processing. The output can be considered as a non-deterministic query which needs to be further deployed into the decision-making system.
It is advised to seamlessly move the ML output directly to production where it will enable the machine to directly make decisions based on the output and reduce the dependency on the further exploratory steps.
Conclusions
Machine Learning Architecture occupies the major industry interest now as every process is looking out for optimizing the available resources and output based on the historical data available, additionally, machine learning involves major advantages about data forecasting and predictive analytics when coupled with data science technology. The machine learning architecture defines the various layers involved in the machine learning cycle and involves the major steps being carried out in the transformation of raw data into training data sets capable for enabling the decision making of a system.
Recommended Articles
This has been a guide to Machine Learning Architecture. Here we discussed the basic concept, architecting the machine learning process along with types of Machine Learning Architecture. You can also go through our other Suggested Articles to learn more –
