Updated March 24, 2023

Introduction to Machine Learning System
The following article provides an outline for Machine Learning System. Learning is the practice through which knowledge and behaviors can be acquired or modified. When this is imparted to computers (machines) so that they can assist us in performing complex tasks without being explicitly commanded, Machine Learning is born. Machine Learning systems as a subset of AI uses algorithms and computational statistics to make reliable predictions needed in real-world applications.
Machine Learning provides an application with the ability to selfheal and learns without being explicitly programmed all the time. Unlike traditional software training, where pre-defined rules are followed to attain a solution, Machine Learning systems approach the optimum solution by experimenting on various approaches.
What is Machine Learning System?
Machine Learning aims to provide insightful, accurate business values by learning from the trained algorithm. A Machine Learning system comprises a set of activities from data gathering to using the model created for its destined course of action.
Data Understanding and Analysis
A good understanding of the problem statement at hand can lead to understanding the data associated with it. In addition, it can set a layout for the series of stages that are to be planned to reach the optimum solution.
Data drive machine Learning. Though in recent times we have abundant access to data in general, obtaining clean data that can contribute towards a successful prediction is still a huge task. Close to 80% of the time involved in creating useable ML applications is spent on data wrangling and data pre-processing.
When dealing with ML, contrary to expectations, data is not handed spotless. It is usually dirty with a lot of unnecessary information or noise presented in the form of a csv or json file. Before being able to use the data for training an ML model, proper measures need to be taken to make the data, model ready. Many statistical and visualization techniques are used for data correction and to form an inkling on the feature sets.
Initial steps are to summarize the given data set by performing Exploratory Data Analysis to get the facts regarding.
- Information on the data: To help us understand the data types associated with each attribute.
- Description of the data: To help us view what kind of data is present under each attribute.
- Missing values: Missing values often restrict the ML model to attain its full potential, hence dealing with them becomes important. They can be replaced based on the requirement with 0 or values of mean, median (for numerical value) or mode (for categorical value) of the particular attribute with the missing values.
- Data visualization: Graphs and charts are used for visually representing the relationship between the attributes. For example, a visually appealing heatmap plotted can give us a better understanding of the correlation between the attributes rather than just looking at the numbers. Visualizing the data gives an idea to formulate what approach needs to be taken further.
Feature Engineering
Once the initial analysis is done and we have an idea with the data and problem in hand, we can work towards building the next layer by:
- Selecting only the relevant features: This can be achieved by dimensionality reduction methods such as PCA (Principal Component Analysis), Factor Analysis, LDA (Linear Discriminant Analysis) to name a few.
- Discarding the noise and outliers in the data: This can be achieved by implementing methods like regularization, k-fold validation, considering the values within the IQR region or even eliminating the redundant features.
Modeling the ML System
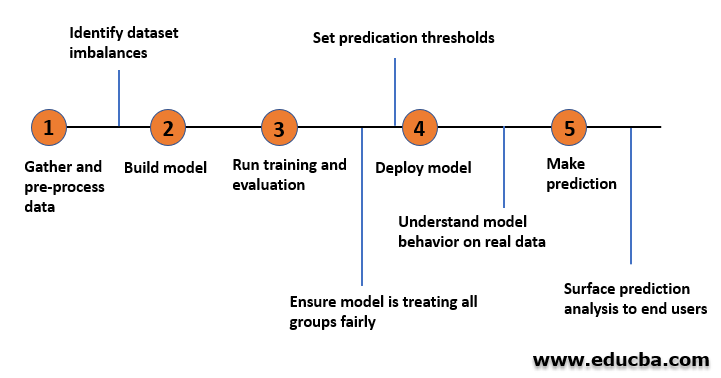
1. Model Selection
Model selection is the process of selecting an algorithm that best suits the requirements of a given problem statement. As a general rule, Regression algorithms are preferred for the prediction of continuous values whereas classification algorithms are used when the target has binary or multiple classes.
2. Model Training and Evaluation
Data obtained for model training can be divided into 3 sets i.e. Training Set, Validation Set, and Test Set. Generally, 70% of the data is used for training and the remaining 30% are used for validating the model training before being used on the unknown test data.
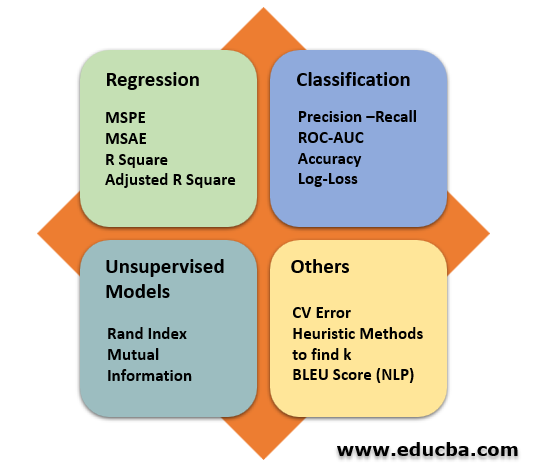
Once a model is selected, it must be trained on the pre-processed data by tuning the required hyperparameters to achieve good performance and to avoid over-fitting. A good ML model performs exceptionally not only on the training data but also on the unseen test data. Hence evaluating the trained model on key aspects comes as a vital step before predicting the target values. The results obtained to post the initial evaluation can be used for further analysis and fine-tuning of the model.
3. Model Deployment
Model deployment is the stage where a working ML model tested for various parameters will be made available for its service in the real-world. The production-ready models are created using a pipeline that encompasses all the stages from data gathering to data pre-processing to model training ensuring a decent CI/CD course. The ML system would be at an advantage if it can be containerized for consistency and reproducibility in the further testing stages.
4. Look for Updates
The work is not finished once the ML system is deployed successfully. Even after a model is chosen and deployed, there will be a constant need to update the system regularly. ML systems perish over time. With new data populating every other day the need to check the ML system and update it to suit the new requirements is mandatory.
Error Analysis in the ML System
A good and recommended approach in ML system design is to keep out complexities at further bay. It is not necessary that a good ML system should be backed up with a complex algorithm and approach. If a simple algorithm can fulfill the requirements of the problem statement in hand, then probably going along with it would be the best option at least, to begin with.
Dealing with the errors and optimizing the ML system could be carried out by:
- Implementing techniques such as Cross-Validation, to come up with improvements.
- Visualizing the data points and based on the analysis such as on bias and variance, the decision can be made whether to include more data, more features and so on.
- Avoiding premature optimization, it is very much necessary to let the evidence guide rather than going along with the gut feeling.
Conclusion – Machine Learning System
Contrary to popular belief building a successful ML system does not solely depend on choosing a model to train and validate. Quality data must be selected, analyzed, and pre-processed to lay a strong foundation for a long-term working ML system. Any route taken to achieve the destination in building an ML system must be thoroughly based on the facts obtained during the data analysis rather than intuition or gut feeling.
Recommended Articles
This is a guide to Machine Learning System. Here we discuss the introduction, data understanding and analysis and error analysis in the ML system. You may also look at the following articles to learn more-
