Updated March 14, 2023
Introduction to Kafka offset
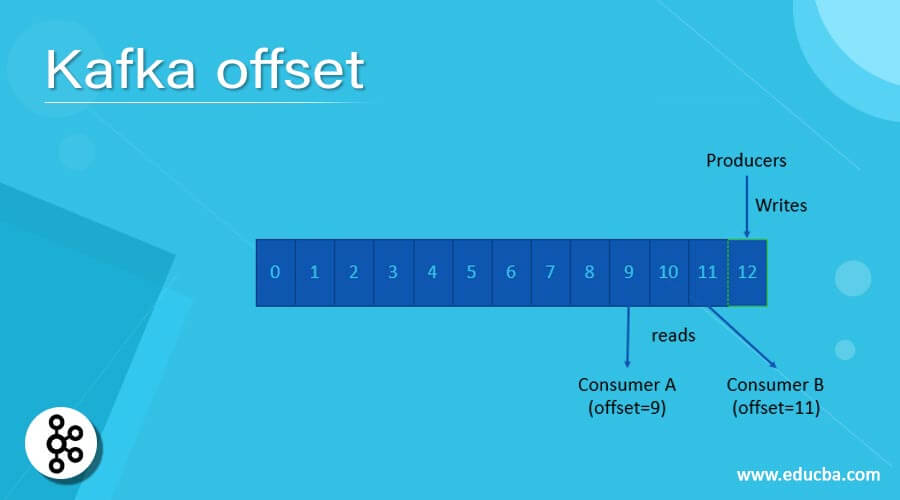
In Kafka, the offset is a simple integer value. The same integer value will use by Kafka to maintain the current position of the consumer. Therefore, the offset plays a very important role while consuming the Kafka data. There are two types of offset, i.e., the current offset and the committed offset. If we do not need the duplicate copy data on the consumer front, then Kafka offset plays an important role. On the other hand, the committed offset means that the consumer has confirmed the processing position. Here, the processing term may vary from the Kafka architecture or project requirement.
Syntax of the Kafka Offset
As such, there is no specific syntax available for the Kafka Offset. Generally, we are using the Kafka Offset value for the data consumption front on the consumer level.
Note: While working with the Kafka Offset. We are using the core Kafka commands and Kafka Offset terminology for the troubleshooting front.
How Kafka Offset Works?
The Kafka offset is majorly deal with in two different types, like the current offset and the committed offset. It will also be further divided into different parts also. Kafka is using the current offset to know the position of the Kafka consumer. While doing the partition rebalancing, the committed offset plays an important role.
Below is the property list and their value that we can use in the Kafka Offset.
- flush.offset.checkpoint.interval.ms: It will help set up the persistent record frequency. The last flush instance will act as a log recovery point in the Kafka offset.
Type: int
Default: 60000 (1 minute)
Valid Values: [0,…] Importance: high
Update Mode: read-only - flush.scheduler.interval.ms: It will help to set up the frequency ms. The log flusher will check if any log needs to be flushed to disk level or not.
Type: long
Default: 9223372036854775807
Valid Values:
Importance: high
Update Mode: read-only - flush.start.offset.checkpoint.interval.ms: It will help set up the frequency so that the persistent data or record of log start Kafka offset.
Type: int
Default: 60000 (1 minute)
Valid Values: [0,…] Importance: high
Update Mode: read-only - metadata.max.bytes: The value is associated with the Kafka offset commit. It will deal with the maximum size for metadata.
Type: int
Default: 4096
Valid Values:
Importance: high
Update Mode: read-only - commit.required.acks: Before doing any commit, it will require an acknowledgment. By default, the -1 value should not be overwriting.
Type: short
Default: -1
Valid Values:
Importance: high
Update Mode: read-only - commit.timeout.ms: The Kafka offset commit will be running slow or delayed until all the running replicas for the offsets topic receive the final commit. In the second part, we can say that the timeout is reached. It will also be similar to the producer request timeout.
Type: int
Default: 5000 (5 seconds)
Valid Values: [1,…] Importance: high
Update Mode: read-only - load.buffer.size: It will help to define the batch size for reading operation from the offsets segments. It will load the offset into the volatile storage. It will deal with the soft limit. It will be overridden if records are too large and continually coming at high frequency.
Type: int
Default: 5242880
Valid Values: [1,…] Importance: high
Update Mode: read-only - retention.check.interval.ms: The frequency at which to check for stale offsets
Type: long
Default: 600000 (10 minutes)
Valid Values: [1,…] Importance: high
Update Mode: read-only - retention.minutes: When the consumer group lost all the consumers. In other words, we can say that it will become empty. Before getting discarded, the offsets.retention.minutes value will help to keep the offsets. The retention period will be applicable for standalone consumers. With the help of the last commit and the retention period, the offset will expire.
Type: int
Default: 10080
Valid Values: [1,…] Importance: high
Update Mode: read-only - topic.compression.codec: It will help to achieve the achieve “atomic” commits. The value help of the compression codec for the Kafka offsets topic.
Type: int
Default: 0
Valid Values:
Importance: high
Update Mode: read-only - topic.num.partitions: It will help to define the number of partitions for the offset commit topic. Please make sure that it will not change after deployment.
Type: int
Default: 50
Valid Values: [1,…] Importance: high
Update Mode: read-only - topic.replication.factor: It will help to define the replication factor of the Kafka offsets topic. If we keep the higher value, then it will have a higher entirety of the data.
Type: short
Default: 3
Valid Values: [1,…] Importance: high
Update Mode: read-only - topic.segment.bytes: To do facilitate faster log compaction, we need to set less value. It will help for the faster log compaction and quick cache loads.
Type: int
Default: 104857600
Valid Values: [1,…] Importance: high
Update Mode: read-only - interval.bytes: We need to keep the index value larger. If we keep the more indexing value, it will jump closer to the exact position.
Type: int
Default: 4096 (4 kibibytes)
Valid Values: [0,…] Server Default Property: log.index.interval.bytes
Importance: medium - offset.reset: This configuration property help to define when there is no initial offset in Kafka.
earliest: It will automatically reset the earliest offset
latest: It will automatically reset the latest offset
none: if no previous offset was found, it would throw a consumer exception
anything else: throw the exception to the consumer.
Type: string
Default: latest
Valid Values: [latest, earliest, none] Importance: medium - auto.commit: If we will configure the enable.auto.commit value is true; then the consumer offset will be committed in the background (The operation will be periodic in nature).
Type: Boolean
Default: true
Valid Values:
Importance: medium - flush.interval.ms: This configuration helps to try committing offsets for the tasks.
Type: long
Default: 60000 (1 minute)
Valid Values:
Importance: low - storage.partitions: When creating the offset for the storage topic. It will help to hold the number of partitions used.
Type: int
Default: 25
Valid Values: Positive number or -1 to use the broker’s default
Importance: low - storage.replication.factor: It will hold the replication information when we are creating the offset storage topic
Type: short
Default: 3
Valid Values: Positive number not larger than the number of brokers in the Kafka cluster, or -1 to use the broker’s default
Importance: low
Conclusion
We have seen the uncut concept of “Kafka Offset.” The offset is very important in terms of the data consumption front. Therefore, it will be very important to keep the offset value correct. If it will miss the match, then the data state will be inconsistent.
Recommended Articles
This is a guide to Kafka offset. Here we discuss the list of property and their value that we can use in the Kafka Offset and How it works. You may also have a look at the following articles to learn more –
