Updated March 23, 2023

Introduction to Kafka Consumer Group
Kafka consumer group is basically several Kafka Consumers who can read data in parallel from a Kafka topic. A Kafka Consumer Group has the following properties:
- All the Consumers in a group have the same group.id.
- Only one Consumer reads each partition in the topic.
- The maximum number of Consumers is equal to the number of partitions in the topic. If there are more consumers than partitions, then some of the consumers will remain idle.
- A Consumer can read from more than one partition.
Importance of Kafka Consumer Group
There will be a large number of Producers generating data at a huge rate for a retail organization. Now, to read a large volume of data, we need multiple Consumers running in parallel. It is comparatively easier on the Producer side, where each Producer generates data independently of the others. But, on the Consumer side, if we have more than one consumer reading from the same topic, there is a high chance that each message will be read more than once. Kafka solves this problem using Consumer Group. In any instance, only one consumer is allowed to read data from a partition.
Partitions of Kafka Consumer Group
Let’s assume that we have a Kafka topic, and there are 4 partitions in it. Then we can have the following scenarios:
1. Number of consumers = Number of partitions
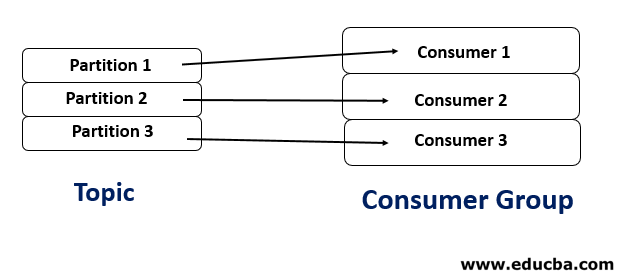
In this case, each Consumer will read data from each partition, which is the ideal case.
2. Number of consumers > Number of partitions
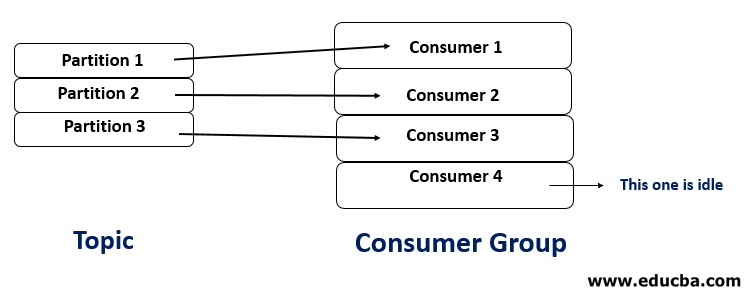
In this case, one consumer will remain idle and leads to poor utilization of the resource.
3. Number of consumers < Number of partitions
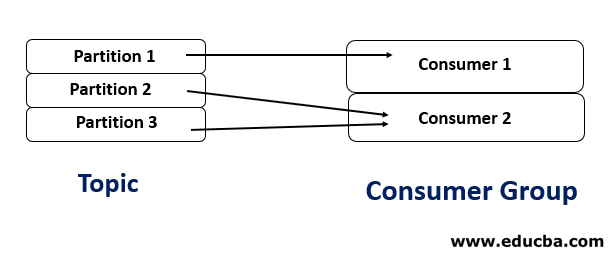
In this case, one of the consumers will read data from more than one partition.
4. Number of Consumer Group > 1
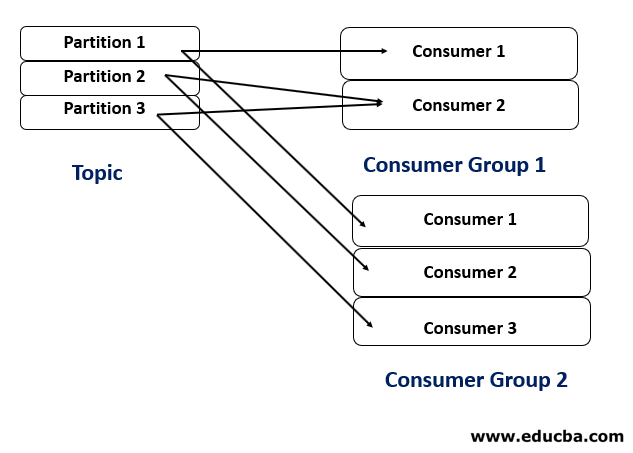
In this case, the topic is subscribed by more than one consumer group, which caters to two different applications. The two applications can run independently of one another.
Advantages of Kafka Consumer Group
Consumer Group adds the following advantages:
- Scalability: Several Consumers reading data in parallel definitely increases the data consumption rate and makes the system capable of reading a high volume of data.
- Fault Tolerance: Suppose we had only one Consumer (for reading not so high volume of data); what would happen if the Consumer fails for some reason? The whole pipeline will break.
- Load Balancing: Kafka shares the partitions fairly with each Consumer, thereby making the process of data consumption smooth and efficient.
- Rebalancing: If a new Consumer is added or an existing one stops, Kafka rebalances the available consumers’ load.
How Kafka Bridges the Two Models?
Let’s discuss the two messaging models first.
1. Message Queues
In this model, a stream of messages is sent from one producer to only one consumer. Thus, each message is read only once, and once a consumer pulls a message, the message is erased from the queue. A typical example may be issuing a paycheck where each paycheck must be issued only once. Also, this model doesn’t ensure that messages will be delivered in order. The scalability of processing messages is limited to a single domain.
2. Publish-Subscribe Messaging
In this model, the messages published by a Producer can be subscribed by more than one Consumer. The Producer and the Consumer are decoupled to a large extent. This model ensures that each Consumer will receive messages on a topic in the producer’s exact order. A typical example may be a dish TV which publishes different channels like music, movie, sports, etc., and the consumers can subscribe to more than one channel. As there are multiple subscribers to a topic, scaling the processing of streams is a challenge.
Although it is based on the publish-subscribe model, Kafka is so popular because it has the advantages of a messaging queue system. As discussed earlier, if we have a Consumer group, Kafka ensures that each message in a topic is read only once by a Consumer (Which is similar to a Message Queue system). The added advantages are that the brokers retain the messages (for some time, thereby making it fault-tolerant). If we have more than one Consumer group, they can read messages from the same topic but process them differently.
Use Case Implication
Let’s assume that we have a simple Cloud Platform where we allow the following operations to users:
- Store files to Cloud.
- View their files in the Cloud.
- Download their files from the Cloud.
In the beginning, we had a tiny user base. We wanted to derive various stats (on an hourly basis) like active users, number of upload requests, number of download requests, etc. To meet the requirements, we set up a Kafka Cluster that produces the logs (generated by our application) into a topic, and there is an application that consumes the topic (using a Consumer) and then processes it to generate the required stats and finally display those in a webpage.
As people started liking our services, more people started using them, thus generating many logs per hour. We found that the application which consumes the topic became extremely slow as we were using only one Consumer. To solve the problem, we added some Consumers to the group and found significant performance improvement.
We came across another requirement, where we had to write the logs into an HDFS cluster, and this process should run independently of the previous application (This is because, with further increase in data, we were planning to decommission the first application and do derive all the stats in the HDFS environment). To meet this requirement, we developed another application that subscribed to the topic using a different Consumer group and wrote the data into the HDFS cluster.
Recommended Articles
This is a guide to Kafka Consumer Group. Here we discuss the importance of the Kafka consumer group and how Kafka bridges two models, and its use case implication. You may also look at the following articles to learn more-
