Updated March 18, 2023

Introduction to HDFS Architecture
HDFS Architecture is an Open source data store component of Apache Framework that the Apache Software Foundation manages. It is known as the Hadoop distributed file system that stores the data in distributed systems or machines using data nodes. Some of the important features of HDFS are availability, scalability, and replication. The Architecture of HDFS includes name node, secondary name node, data node, checkpoint node, backup node, and blocks. HDFS is fault-tolerant, and it is managed through the replication process. The Name node and data Node coordinates store huge files in a distributed structure across the cluster systems.
Features of HDFS
The features of the HDFS which are as follows:
1. Availability
In HDFS, data gets replicated regularly among data nodes by creating a replica of blocks on the other data node. So in case of any hardware failure or error, the user can get his data from another data node where the data has been replicated.
2. Scalability
In HDFS, data is stored on multiple data nodes in the form of blocks. HDFS enables users to increase the size of blocks whenever needed. There are two types of scalability mechanism used in HDFS – horizontal scalability and vertical scalability.
3. Replication
This is the unique features of HDFS that allow users to get easy access to their data in case of any hardware failure.
HDFS Architecture
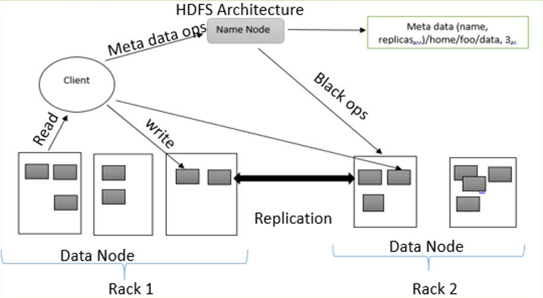
HDFS follows master-slave architecture, which has the following components:
1. NameNode
NameNode is also known as the master node because it handles all the blocks which are present on DataNodes.
NameNode performs the following tasks:
- Manage all the DataNode blocks
- Gives file access to user
- Keeps all the records of blocks present on DataNode
- NameNode records all information of files; for example if a file name is rename or content has been changed or deleted, NameNode immediately record that modification in EditLogs
- It takes all the blocks from the data nodes to ensure that all the block are alive on DataNode.
- In case of error, if any hardware failure happens, it immediately selects another DataNode to create replication and manage the communication to all the DataNodes
Types of files in NameNode
NameNode contains two types of files FsImage and EditLogs
i. FsImage: It is also called a file image because it contains all the information on a filesystem with namespaces. It also includes all the directories and the files of the filesystem in a serialized manner.
ii. EditLogs: Current modifications done in the files of the filesystem are stored in EditLogs.
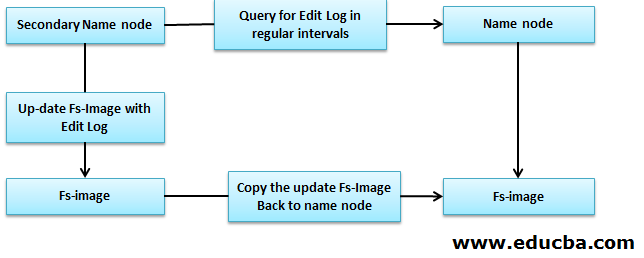
2. Secondary NameNode
Secondary NameNode is also called a checkpoint node because it performs regular checkpoints. It acts as a helper for primary NameNode.
Secondary NameNode performs the following tasks.
- Secondary NameNode combines FsImage and EditLogs from the NameNode.
- It reads all the filesystem information from the storage memory of NameNode and writes this information on a hard disk of the filesystem.
- It downloads the FsImage and EditLogs from NameNode at regular intervals, reads the modification information done by EditLogs files, and notes the modification to the FsImage. This process creates a new FsImage, which is then sent back to the NameNode. Whenever the NameNode starts, it will use these FsImage.
3. DataNode
DataNode is also known as a slave node because it handles every node that contains data on a slave machine. DataNode stores data in ext3 or ext4 file format.
Data node performs the following tasks:
- Every data is stored on DataNodes.
- It performs all the operations of files as per the users’ request, for example, reading file content, writing new data in files,
- It also follows all the instructions given, such ashe file, deleting some blocks on DataNode, creating partnerships, etc.
4. Checkpoint Node
A checkpoint node is a node that created a checkpoint of files at regular intervals. Checkpoint node in HDFS, download the FsImage and EditLogs from NameNode and merge them to create a new image and send it to NameNode. The latest checkpoint is stored in a directory with the same structure as the name node’s directory. Because of this, the checkpointed image is always available if it needs.
5. Backup Node
The function of a backup node is similar to a Checkpoint node to perform a checkpointing task. In Hadoop, the Backup node stores the latest and updated copy of the file system namespace. There is no need to download FsImage and editsLogs files from the active NameNode to create a checkpoint in the Backup node because it is synchronized with the active NameNode. The Backup node’s function is more precise because save namespace into the local FsImage file and reset editions.
6. Blocks
All the data of users are stored in files of HDFS, which are then divided into small segments. These segments are stored in the DataNodes. The features which are present on DataNodes are called a block. The default block size of these blocks is 128 MB. The size of the block can be changed as per users requirements by configuring HDFS.
If the data size is less than the block size, then block length is equal to the data size. For example, If the data is 135 MB, then it will create 2 Blocks. One will be of default size 128 MB, and another will be 7MB only, not 128 MB. Because of this, a lot of space and disk’s clock time is saved.
Replication Management in HDFS Architecture
HDFS is Fault-tolerant. Fault tolerance is the system’s power in case of failures and responding to the errors and challenging conditions. Fault tolerance works based on the process of replica creation. Copies of user’s data are saved on machines in the DHFS cluster. Hence, if there is any breakdown or failure in the system, a copy of that data can be accessed from the other machines of the HDFS cluster. Each block in HDFS architecture has 3 replicas that are stored in different DataNodes. NameNode maintains the copies available in DataNodes. NameNode adds or deletes copies based on the criteria of under replicated or over-replicated blocks.
Write Operation
To write files to HDFS, the client will communicate for metadata to the NameNode. The Nameode answers with several blocks, their location, copies, etc. The client divides files into multiple blocks based on named information. Then, it starts sending them to DataNode. First, the client sends block A to DataNode 1 with other information about DataNodes. When DataNode 1 receives the client’s block A, DataNode 1 copies the same block to the same rack to DataNode 2. Because both DataNodes are in the same frame, transferring the block is done via rack switch. DataNode 2 now copies the same block to DataNode 3. Because both the DataNodes are in different racks, moving the block is done through an out–of–rack switch. Once DataNode receives the client’s leagues, it will send the confirmation to NameMode. In each block of the file, the same process is repeated.
Read Operation
For Read operation, the First client communicates metadata to the NameNode. A client exits NameNode with the file name and location. The Nameode responds with a block number, site, copies and other information. After that, the Client communicates to DataNodes. Based on the information received from the NameNode, the client starts reading data parallel from the DataNodes. When the client or application receives all the block of the file, it combines them into an original file form.
Conclusion
With the help of NameNode and DataNode, it reliably stores huge files across machines in a large cluster. Because of fault tolerance, it is helpful to access data while software or hardware failure. This is how HDFS architecture works.
Recommended Articles
This has been a guide to HDFS Architecture. Here we discussed the essential concepts with different types of Architecture, features, and replication management of HDFS Architecture. You can also go through our other suggested articles to learn more –
