Updated March 6, 2023
Introduction to Kafka burrow
The basic of Kafka is originally developed by LinkedIn. Similarly, the Kafka burrow has come under the LinkedIn project only. The Kafka burrow is providing the monitoring solution for Apache Kafka. Majorly, it will provide the monitoring solution for the consumer lag checks. Here, the Kafka burrow is providing as a service. In the burrow, there is no need to specify any threshold value. It will monitor the committed offsets of the Kafka consumers. On-demand, It will also compute the status of the Kafka consumer also. To suffice the on-demand requirement, we need to use the HTTP API call and need to provide the other information of the Kafka cluster as well like the zookeeper information, cluster details, port information, etc. In the Kafka burrow, we are having other notifies also like the email communication, etc.
Syntax of Kafka burrow
As such, there is no specific syntax exist for Kafka burrows. To work with the Kafka burrows, we need to understand the complete architecture of it. Similarly, we also need to understand the working flow of it. In Kafka burrows, we are using the number of HTTP components also. As per the requirement or need, we will install the Kafka burrow environment and configure it accordingly. While installation the Kafka burrows environment, we need to get the necessary file for the GitHub repo. To configure it, we need to use the install and the go utility. But majorly we need to use the docker concept to run the Kafka the burrow environment. Once the installation will compete we need to configure the Kafka burrow environment and access the environment from the browser.
Note: Generally, we are using the 8000 port to access the Kafka burrow environment.
How Kafka burrow Works?
As we have discussed, the Kafka burrows are providing the monitoring functionality for the Kafka environment. It is majorly useful to check the lag in the Kafka consumer. We are using the Kafka ecosystem for streaming purposes. In streaming, we need a quick response from the producer as well as from the consumer (the application or the tool that is consuming the data). Here, if we will face any lag or delay then at the end level we are not getting the valuable data. Hence, we need to fix it and need to identify is there any lag while fetching the data or consuming the data. Here, the Kafka burrow comes into the picture. It will provide the UI. On the same UI, it will display the detailed information of the lag like is there any lag is present or not.
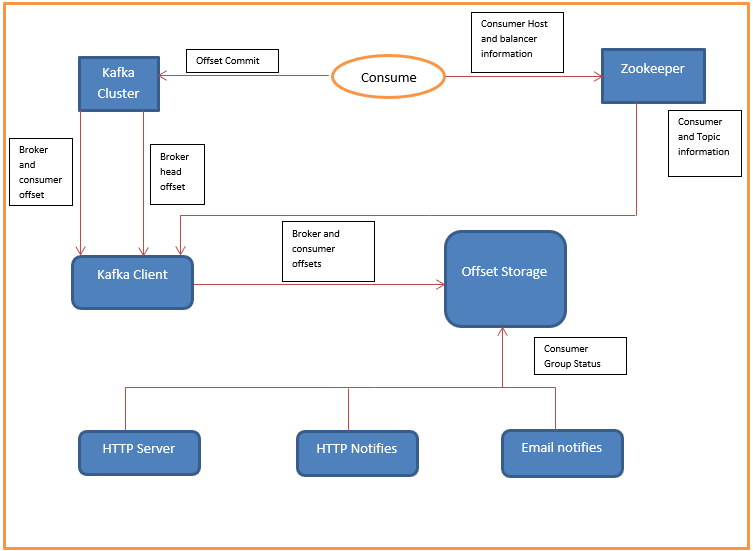
The Kafka burrow project has come under the Data Infrastructure Streaming SRE team. The team has come under LinkedIn. The above dataflow is representing how the Kafka burrows work. The burrow will atomically monitor all the Kafka consumers and the partition that they are consuming. Then the burrow will keep all the detailed information of the Kafka consumer at the centralized level. This information is distinct as compared to the single consumer information. Here, there is a sliding window concept that comes into the picture. As per the evaluation, the consumer status is determined by the Kafka consumer behavior. In each Kafka partition will check on the basics of the below information like it is consumer committed offset or not, the consumer offset value is increasing or not, lag is increasing or not, the lag is increasing frequently or constant. As per this check, they can state the consumer status like OK (if the status is OK then no action needed), if the status is WARNING (if the status is WARNING then it is falling but the consumer is working fine). If the status is ERROR (if the status is ERROR then the consumer is not working). All this is handling by the simple HTTP call. As per the API call, we will get the necessary alerts.
Below are the features of the Kafka burrow
1. In the Kafka burrow environment, there is no need to define the threshold value. The Groups will evaluate over the sliding window.
2. The Kafka burrow will support the multiple Kafka Cluster and different Kafka environments also.
3. In the Kafka environment, it will automatically monitor all Kafka consumers. For the monitoring, it will use the Kafka committed offset values.
4. Similarly to Kafka, we are able to configure the Zookeeper committed offset.
5. Similarly to the zookeeper, we are able to configure the Storm committed offset.
6. It will also support the HTTP endpoint for consumer group status. Similarly, it will also support the broker as well as the consumer information.
7. The Kafka burrow will provide the alert functionality also. We are able to configurable the email alert also. We can set the same email alert to the respective stakeholders also.
8. In Kafka burrow alert, we are able to configurable the HTTP client alert also. We can send the same alert to another application, tool, or system for all groups as well as respective stakeholders.
Examples to understand Kafka burrow
Kafka Burrow Concept
As such, there is a specific command available to work with the Kafka burrow. It is just a monitoring platform that it will help to monitor the Kafka consumer. It will help to check, is there any lag or not. The information is visible on the UI.
Conclusion
We have seen the uncut concept of the “Kafka burrow” with the proper explanation. The Kafka burrows are nothing but a monitoring tool for the Kafka consumer. It will atomically monitor the consumer lag without setuping the threshold value in it. If any issues happen then it will send the alert notification to the respective stakeholders.
Recommended Articles
This is a guide to Kafka burrow. Here we discuss definition, syntax, How Kafka burrow Works? example with code implementation. You may also have a look at the following articles to learn more –
