
Introduction to Hive Installation
Hive provides a great interface to the user to access and perform an operation on the data in the form of a table. It provides great optimization techniques to make performance better. It’s very challenging to make the query faster with big data and believe me, and it matters in a production environment. In the backend, the compiler converts HQL query into map-reduce jobs and then submitted to Hadoop framework for executions. Hadoop components like Hive, Hbase, Pig, etc. all support the Linux environment. Therefore, it is recommended to have a Linux operating system on your device. Apache Hadoop is a collection of the framework that allows for processing big data distributed across the cluster.
As per Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data query and analysis. Apache hive provides SQL like interface to query and to process a large amount of data called HQL (Hive query language). Apache hive runs on top of the Hadoop ecosystem, and the data stored in the form of file means Hadoop distributed file system (HDFS). If it is not the case and you want to practice on hive while having windows on your system. What you can do is, Install the CDH machine on your system and use it as a platform to explore Hadoop. This will require a minimum of 4GB Ram on your system, or You can have a CDH machine in your pen drive and use it.
Anyhow you can always have a solution to your question that maybe sooner than later.
Difference Between Hive and SQL
Apache Hive is very much similar to SQL, but as we know hive runs on top of Hadoop ecosystem and internally convert jobs into MR (Map Reduce Jobs), it makes some difference between Hive and SQL.
The hive would not be the best approach for those applications where very fast response required, and it’s essential to understand that the Hive is better suited for batch processing over huge sets of immutable data. We should note this that Hive is a regular RDBMS and in last but not least apache hive is schema on reading means (while inserting data into hive table it will not bother about data type mismatch but while reading data it will show null value if the data type is not matched with specific column’s data type).
Prerequisites
There are some prerequisites to install hive on any machine:
- Java Installation
- Hadoop Installation
Step #1
- Verify Java is installed.
- Open the Terminal and Type the Command.
Java-Version
- If java is installed on the system, it will give you the version or else an error. In my case, Java is already installed and below is the output of the command.

- In case, Java is not installed in your system. You can visit the below link and download java and install it.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Java Installation
- Extract the downloaded.
- Move it to “/usr/local/”.
- Set up PATH and JAVA_HOME variables.
Step #2
- Verify Hadoop is installed.
- Open the Terminal and type the command.
Hadoop-Version
- If Hadoop is already installed, this command will give you the version or else an error.
- In my case, Hadoop has already installed hence the below output.
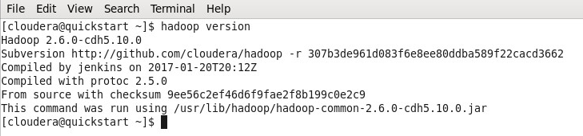
- You can now observe I am working with a CDH5 machine.
- If Hadoop is not installed, Download the Hadoop from Apache software foundation.
Hadoop Installation
1. Setup Hadoop
2. Configure Hadoop
Files required to be edited to configure Hadoop are:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Setup Namenode using the command:
Hdfs namenode -format
4. Start dfs using the following command:
start -dfs.sh
5. Start yarn using the command:
Start -yarn.sh
How to Install Hive?
Below the points in respect to Hive Installation
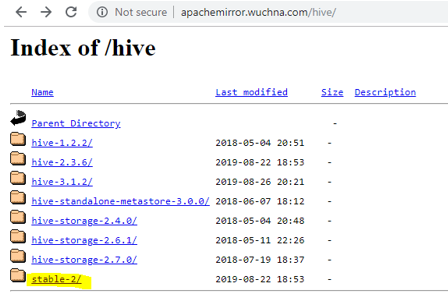
- The first thing we need to do is download the hive release which can be performed by clicking the link below: https://apachemirror.wuchna.com/hive/
- Above link will give the link from which you have to choose stable-2 highlighted below in yellow:
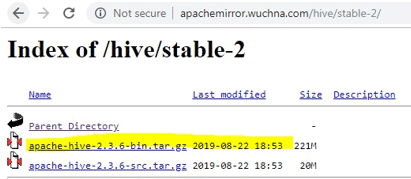
- After opening stable-2, choose the bin file (highlighted yellow in the screenshot) and right click and “copy link address”.
Steps to Install Hive
Below are the steps in Hive Installation:
Step 1: Download the tar file.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Step 2: Extract the file.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Step 3: Move apache files to /usr/local/hive directory.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Step 4: Set up the Hive environment by appending the following lines to ~/.bashrc file
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Step 5: Execute the bashrc file.
$ source ~/.bashrc
Step 6: Hive Configuration- Edit hive-env.sh file to append this:
export HADOOP_HOME=/usr/local/Hadoop
Step 7: Edit using the below commands:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Now to verify the hive is installed or not, use command hive-version.
- Here, hive-version enters the hive shell, which means the hive is installed. However, in my case, it is the older version hence giving the warning.

Conclusion
Hive opens up the big data to many people because of its easiness and similar nature to SQL like query language and interfaces. Hive is built on Hadoop core as it uses Mapreduce for execution. Much easy to retrieve the data and do the processing of Big Data.
Recommended Articles
This is a guide to Hive Installation. Here we learned how to install hive step by step along with some prerequisites for better understanding. You can also go through our other related articles to learn more –
