Updated May 10, 2023

Introduction to Hive Commands
Hive command is a data warehouse infrastructure tool that sits on top of Hadoop to summarize Big data. It processes structured data. It makes data querying and analyzing easier. The hive command is also called “schema on reading;” It doesn’t verify data when loaded; verification happens only when a query is issued. This property of Hive makes it fast for initial loading. It’s like copying or simply moving a file without putting any constraints or checks. Facebook first developed it. Apache Software Foundation took it up later and developed it further.
Components of Hive Commands
The components 0f the hive command are as shown below:
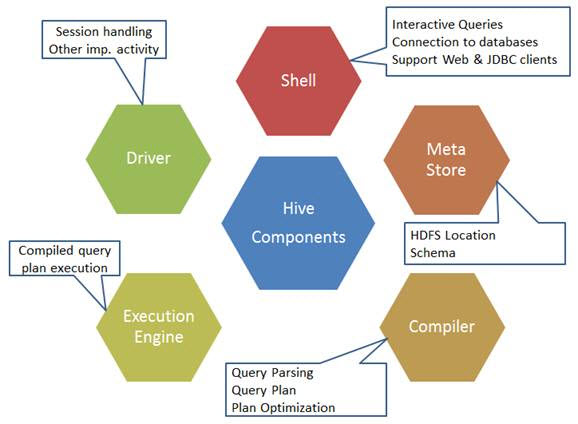
Sources image: https://www.developer.com/
Features of Hive Commands
Here are a few of the features discussed below:
- Hive stores are raw and processed datasets in Hadoop.
- It is designed for Online Transaction Processing (OLTP). OLTP is a system that facilitates high-volume data in significantly less time without relying on a single server.
- It is fast, scalable, and reliable.
- The SQL-type querying language provided here is HiveQL or HQL. This makes ETL tasks and other analyses easier.
Sources images:- Google
There are a few limitations of the Hive command as well, which are listed below:
- It doesn’t support subqueries.
- Hive indeed supports overwriting, but unfortunately, it doesn’t support deletion and updates.
- Hive is not designed for OLTP, but it is used for it.
To enter the Hive’s interactive shell:
$HIVE_HOME/bin/hive
Basic Hive Commands
The basic commands are explained below.
1. Create: This will create the new database in the Hive.
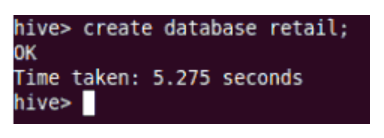
2. Drop: The drop will remove a table from Hive
3. Alter: Alter command will help you rename the table or table columns.
For example:
ALTER TABLE employee RENAME TO employee1;
4. Show: show command will show all the databases residing in the Hive.
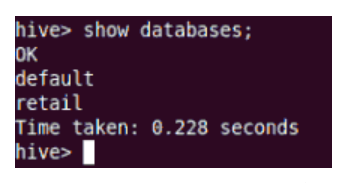
5. Describe: Describe command will help you with the information about the table schema.
Intermediate Hive Commands
Hive divides a table into variously related partitions based on columns. Using these partitions, it gets easier to query data. These partitions get divided into buckets to run queries efficiently onto data.
In other words, buckets distribute data into a set of clusters by calculating the hash code of the key mentioned in the query.
1. Adding Partition
Adding Partitions can be accomplished by altering the table. Say you have table “EMP” with fields such as Id, Name, Salary, Dept, Designation, and yoj.
ALTER TABLE employee
ADD PARTITION (year=’2012’)
location '/2012/part2012';
2. Renaming Partition
ALTER TABLE employee PARTITION (year=’1203’)
RENAME TO PARTITION (Yoj=’1203’);
3. Drop Partition
ALTER TABLE employee DROP [IF EXISTS]
PARTITION (year=’1203’);
4. Relational Operators
Relational operators consist of a particular set of operators that helps to fetch relevant information.
For example: Say your “EMP” table looks like this:
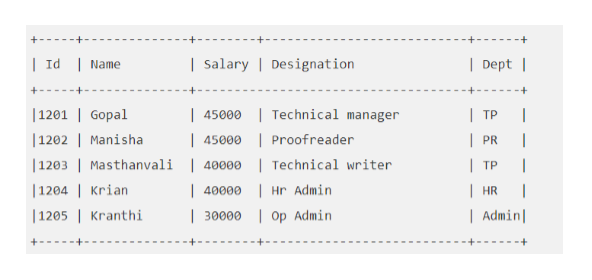
Let’s execute a Hive query to fetch the employee whose salary is more significant than 30000.
SELECT * FROM EMP WHERE Salary>=40000;
5. Arithmetic Operators
These are operators which help in help in executing arithmetic operations on the operands and, in turn, always return number types.
For example: To add two numbers, such as 22 & 33
SELECT 22+33 ADD FROM temp;
6. Logical Operator
These operators are to execute logical operations, which always return True/False.
SELECT * FROM EMP WHERE Salary>40000 && Dept=TP;
Advanced Hive Commands
The advanced commands are explained below.
1. View
The view concept in Hive is similar to SQL. You can create a view when executing a SELECT statement.
Example:
CREATE VIEW EMP_30000 AS
SELECT * FROM EMP
WHERE salary>30000;
2. Loading Data into Table
Load data local inpath 'https://cdn.educba.com/home/hduser/Desktop/AllStates.csv' into table States;
Here “States” is the already created table in Hive. Hive has some built-in functions which help you fetch your result better, like round, floor, BIGINT, etc.
3. Join
A join clause can help join two tables based on the same column name.
Example:
SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
FROM CUSTOMERS c JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);
Hive supports all kinds of joins: Left outer join, right outer join, and full outer join.
Tips and Tricks
Hive makes data processing easy, straightforward, and extensible, so users pay less attention to optimizing the Hive queries. But paying attention to a few things while writing Hive query will surely bring great success in managing the workload and saving money. Below are a few tips regarding that:
1. Partitions & Buckets
It is a big data tool that can query large datasets. However, writing the query without understanding the domain can bring great partitions in Hive.
If the user is familiar with the dataset, they can group relevant and frequently used columns into the same partition. This will help in running the query faster and inefficient way.
Ultimately the no. of mapper and I/O operations will also be reduced.
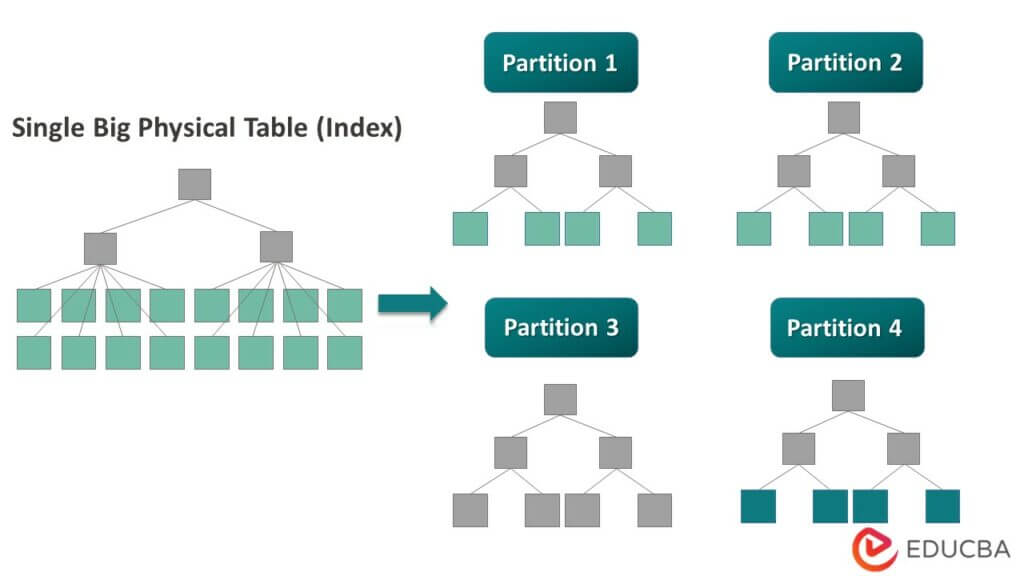
Fig: Partitioning
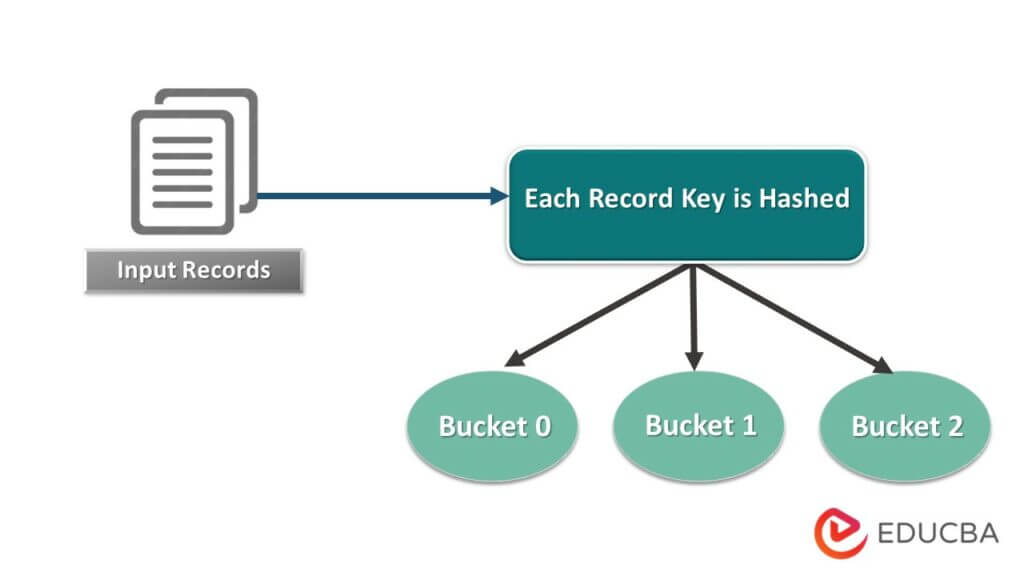
Fig: Bucketing
2. Parallel Execution
It runs the query in multiple stages. In some cases, these stages may depend on other stages, hence can’t get started once the previous step is completed. However, independent tasks can run parallelly to save overall run time. To enable the parallel run in Hive:
set hive.exec.parallel=true;
Hence, this will enhance cluster utilization.
3. Block Sampling
Sampling data from a table will allow the exploration of queries on data.
Despite bucking, we instead want to sample the dataset more randomly. Block sampling comes with various powerful syntax, which helps test the data in different ways.
Sampling can help approximate information from a dataset, such as the average distance between the origin and destination.
Querying 1% of big data will give near to the perfect answer. Exploration gets way easier & effective.
Conclusion
Hive is a higher-level abstraction on top of HDFS, which provides flexible query language. It helps in querying and processing data more efficiently.
You can combine it with other big data elements to fully leverage its functionality.
Recommended Articles
This has been a guide to Hive Commands. Here we have discussed components, features, basic, advanced, and intermediate Hive Commands, and tips and tricks. You may also look at the following article to learn more –
