Updated March 20, 2023

Overview of Install Hadoop
Install Hadoop involves installing and configuring the related software and utilities associated with the Hadoop framework. Hadoop is an open-source framework which Licensed from Apache software foundation for big data processing. First, Java needs to be installed on the system. Hadoop is installed on a Linux Operating system like CentOS for its computation. After setting up the Java in the environment, the Hadoop package software that is downloaded through The Apache website needs to be installed. The related Name Node configurations the configuration XML is known as core-site.xml, and for data nodes, the hdfs-site.xml needs to be configured alongside yarn-site.xml for resource management.
Hadoop Framework
The Apache Hadoop framework consists of the following key modules:
- Apache Hadoop Common
- Apache Hadoop Distributed File System (HDFS)
- Apache Hadoop MapReduce
- Apache Hadoop YARN (Yet Another Resource Manager)
1. Apache Hadoop Common
Apache Hadoop Common module consists of shared libraries that are consumed across all other modules, including key management, generic I/O packages, libraries for metric collection, and utilities for the registry, security, and streaming.
2. HDFS
The HDFS is based on the Google file system and is structured to run on low-cost hardware. In addition, HDFS is tolerant of faults and is designed for applications having large datasets.
3. MapReduce
MapReduce is an inherent parallel programming model for data processing, and Hadoop can run MapReduce programs written in various languages such as Java. MapReduce works by splitting the processing into the map phase and reduces the phase.
4. Apache Hadoop YARN
Apache Hadoop YARN is a core component, resource management, and job scheduling technology in the Hadoop distributed processing framework.
This article will discuss the installation and configuration of Hadoop on a single node cluster and test the configuration by running the MapReduce program called wordcount to count the number of words in the file. After that, we will further look at a few important Hadoop File System commands.
Steps to Install Hadoop
The following is a summary of the tasks involved in the configuration of Apache Hadoop:
Task 1: The first task in the Hadoop installation included setting up a virtual machine template that was configured with Cent OS7. Packages such as Java SDK 1.8 and Runtime Systems required to run Hadoop were downloaded, and the Java environment variable for Hadoop was configured by editing bash_rc.
Task 2: Hadoop Release 2.7.4 package was downloaded from the apache website and was extracted in the opt folder. Which was then renamed as Hadoop for easy access.
Task 3: Once the Hadoop packages were extracted, the next step included configuring the environment variable for the Hadoop user, followed by configuring Hadoop node XML files. In this step, NameNode was configured within core-site.xml, and DataNode was configured within hdfs-site.xml. Finally, the resource manager and node manager were configured within yarn-site.xml.
Task 4: The firewall was disabled in order to start YARN and DFS. JPS command was used to verify if relevant daemons are running in the background. The port number to access Hadoop was configured to http://localhost:50070/.
Task 5: The next few steps were used to verify and test Hadoop. For this, we have created a temporary test file in the input directory for the WordCount program. Then, the map-reduce program Hadoop-MapReduce-examples2.7.4.jar was used to count the number of words in the file. Finally, results were evaluated on the localhost, and logs of the submitted application were analyzed. All MapReduce applications submitted can be viewed at the online interface, the default port number being 8088.
Task 6: We will introduce some basic Hadoop File System commands and check their usages in the final task. We will see how a directory can be created within the Hadoop file system to list the content of a directory, its size in bytes. We will further see how to delete a specific directory and file.
Results in Hadoop Installation
The following shows the results of each of the above tasks:
Result of Task 1:
A new virtual machine with a cenOS7 image has been configured to run Apache Hadoop. Figure 1 shows how CenOS 7 image was configured in the Virtual machine. Figure 1.2 shows the JAVA environment variable configuration within .bash_rc.
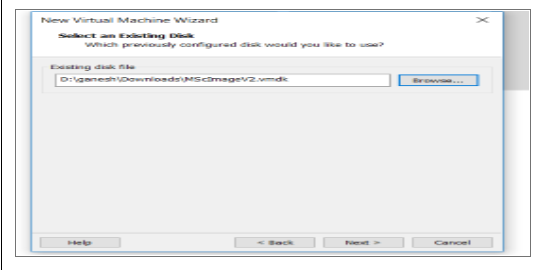
Virtual machine configuration

Java environment variable configuration
Result of Task 2:
Figure shows the task carried out to extract the Hadoop package into the opt folder.

Extraction of hadoop 2.7.4 package
Result of Task 3:
Figure shows the configuration for the environment variable for Hadoop user, Figure shows the configuration for XML files required for Hadoop configuration.
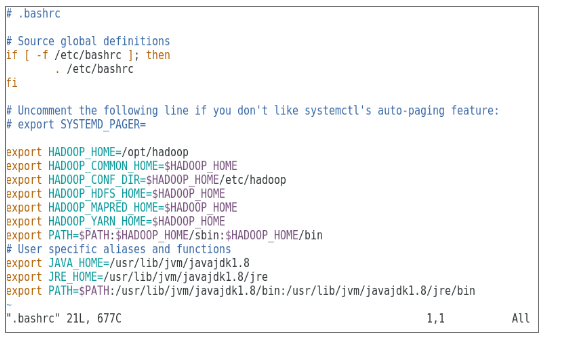
Configuring the environment variable for Hadoop user.
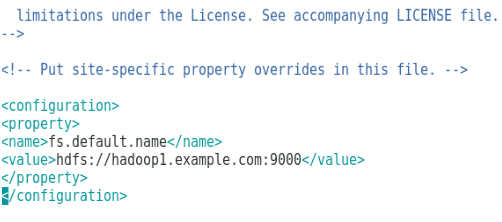
Configuration of core-site.xml.
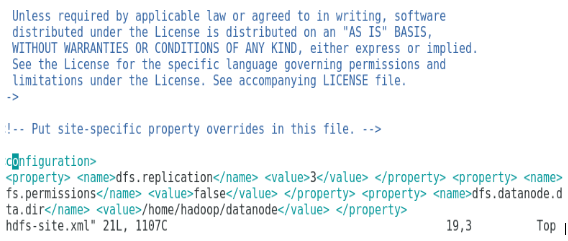
Configuration of hdfs-site.xml.

Configuration of mapred-site.xml file.

Configuration of yarn-site.xml file.
Result of Task 4:
Figure shows the usage of the jps command to check relevant daemons are running in the background and the following figure shows Hadoop’s online user Interface.
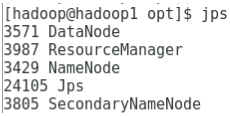
jps command to verify running daemons.
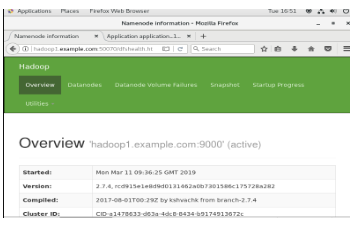
Accessing Hadoop online interface at port http://hadoop1.example.com:50070/
Result of Task 5:
Figure shows the result for the MapReduce program called wordcount, which counts the number of words in the file. The next couple of figures displays the YARN resource manager’s online user interface for the submitted task.
MapReduce program results

Submitted Map-reduce application.
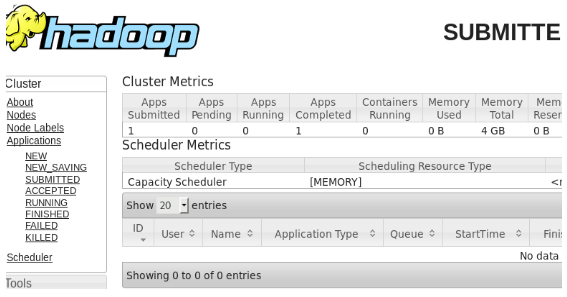
Logs for submitted MapReduce application.

Result of Task 6:
Figure shows how to create a directory within the Hadoop file system and perform a listing of the hdfs directory.
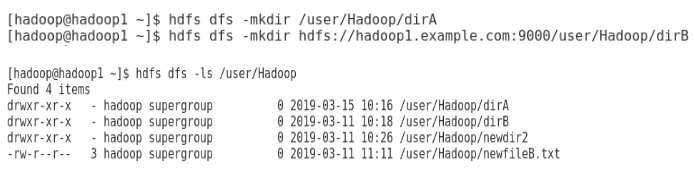
Creating a directory within the Hadoop file system.
shows how to put a file onto the Hadoop distributed file system, and figure 6.2 shows the created file in the dirB directory.

Creating a file in HDFS.
New file created.
The next few figures show how to list the contents of particular directories:
Content of dir A
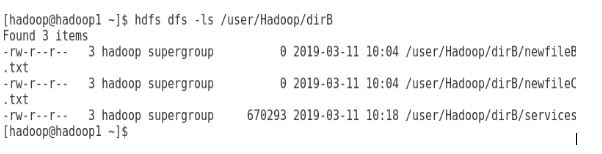
Content of dir B
The next figure shows how file and directory size can be displayed:
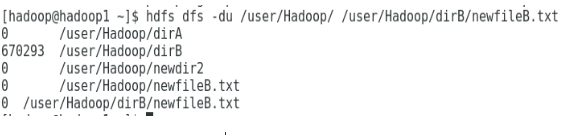
Display a file and directory size.
Deleting a directory or a file can be easily accomplished by the -rm command.

To delete a file.
Conclusion
Big Data has played a very important role in shaping today’s world market. Hadoop framework makes data analyst’s life easy while working on large datasets. The configuration of Apache Hadoop was quite simple, and the online user interface provided the user with multiple options to tune and manage the application. Hadoop has been used massively in organizations for data storage, machine learning analytics and backing up data. Managing a large amount of data has been quite handy because of Hadoop distributed environment and MapReduce. Hadoop development was pretty amazing when compared to relational databases as they lack tuning and performance options. Apache Hadoop is a user-friendly and low-cost solution for managing and storing big data efficiently. HDFS also goes a long way in helping in storing data.
Recommended Articles
This is a guide to Install Hadoop. Here we discuss the introduction to install hadoop, step-by-step installation of hadoop, and hadoop installation results. You can also go through our other suggested articles to learn more –
