Introduction to InfluxDB
InfluxDB emerges as a powerful solution within time-series databases, boasting robust capabilities finely tuned to meet the needs of modern, data-intensive applications. It is a specialized database system that efficiently manages large timestamped data streams central to time-series data analysis. By enabling the storage, retrieval, and analysis of these time-stamped data points, InfluxDB supports a variety of critical use cases. These range from monitoring sensor data in IoT networks to tracking application performance metrics. Developers meticulously craft their architecture and functionalities to address the unique demands of time-series data, ensuring optimal performance, scalability, and adaptability. This article explores the fundamental concepts, features, benefits, and practical applications of InfluxDB, illuminating its pivotal role in today’s data-driven landscape.
Table of Contents
Time Series Databases
Time-series databases (TSDBs) are a specialized database category finely tuned for managing time-stamped or time-series data. This data type typically consists of data points sequenced in chronological order, often with a consistent time interval between each consecutive data point. The versatility of this data structure is evident in its extensive application across diverse domains, including IoT (Internet of Things), financial markets, system monitoring, and more.
Importance of Time-Series Data
- Temporal Correlation: Time-series data often exhibits temporal correlation, meaning that the value of a data point at one time may be dependent on or related to the values at previous times. For example, stock prices, sensor readings, and server performance metrics typically show temporal patterns.
- Analysis and Prediction: Analyzing time-series data enables businesses to derive valuable insights, detect anomalies, predict future trends, and make data-driven decisions. For instance, analyzing website traffic data helps optimize server resources, while analyzing financial time series aids in predicting market trends.
- Real-Time Monitoring: Many applications require real-time monitoring and alerting based on incoming time-series data. For example, monitoring the health of industrial machinery, tracking vehicle telemetry in logistics, or monitoring network traffic for cybersecurity purposes.
- Data Retention and Compression: Designers craft time-series databases to efficiently manage and retrieve substantial amounts of time-series data. They often employ specialized data storage and compression techniques optimized for time series data, enabling long-term historical data retention without sacrificing performance.
What is InfluxDB?
InfluxDB is a resilient open-source time-series database tailored for effectively managing extensive collections of time-stamped data. Developers meticulously craft it to offer high availability, scalability, and top-notch performance, catering to various applications from system monitoring to IoT analytics.
Key Features
- Purpose: InfluxDB is optimized explicitly for storing, querying, and visualizing time-series data. It excels in managing data indexed by timestamps, such as sensor data, application metrics, and financial market data.
- Architecture: InfluxDB builds on a distributed architecture that enables horizontal scalability, ensuring it can handle large amounts of data across multiple nodes. It comprises various components, including a storage engine, query processor, and HTTP API for data ingestion and retrieval.
- Data Model: InfluxDB organizes data into measurements, tag sets, and fields. A measurement represents a specific metric or data stream, while tags provide metadata for filtering and grouping data. Fields encompass the actual data values linked with each data point.
- Query Language: InfluxDB offers its query language, InfluxQL, designed to query and manipulate time-series data efficiently. It supports various operations such as aggregation, filtering, and downsampling.
- Integration: InfluxDB provides seamless integration with other technologies and tools commonly used in the data ecosystem. It offers connectors for popular data visualization tools, monitoring platforms, and programming languages.
Core Concept
- Organizations: InfluxDB uses organizations to group users and resources within a shared environment effectively. This organizational structure facilitates collaboration and enhances access control mechanisms, ensuring users can work within designated scopes according to their roles and responsibilities.
- Buckets: InfluxDB stores data in containers known as buckets. Buckets serve as repositories for organizing and managing time-series data. They enable users to define retention policies, which dictate the duration for retaining data within the system and access control settings. This bucket ensures that authorized users securely manage and access data.
- Measurements: Measurements serve as the primary organizational unit within InfluxDB. They represent distinct categories of time-series data and help structure the data stored within the database. Each measurement corresponds to a specific data type and contains individual data points, making it easier to organize, query, and analyze related data sets.
- Fields and Tags: Two key components characterize data points within InfluxDB: fields and tags. Fields store the actual data values associated with each data point, representing the primary information being measured or recorded. On the other hand, Tags provide supplementary metadata that users can employ for filtering and categorizing data. Tags offer flexibility in organizing and classifying data, allowing users to add context and granularity to their time-series datasets.
Benefits of Using InfluxDB
- Scalability and Performance:
- InfluxDB excels in scalability, effortlessly managing extensive time-series data volumes. Its architecture supports horizontal scaling, allowing users to expand their database infrastructure as data grows.
- InfluxDB maintains high performance even with large datasets and high ingestion rates with an optimized storage engine and advanced query processing capabilities. It ensures that applications relying on InfluxDB remain responsive and efficient, even under heavy workloads.
- Continuous Query Processing:
- InfluxDB facilitates continuous query processing, enabling real-time computation and analysis of time-series data. This feature empowers users to define queries continuously executed against incoming data streams, facilitating live insights and timely alerts.
- Continuous query processing is valuable for real-time monitoring, anomaly detection, or trend analysis applications. It informs users about data changes and enables prompt responses to critical events.
- Built-in Visualization Tools:
- InfluxDB includes built-in visualization tools for creating informative, visually appealing dashboards for monitoring and analyzing time-series data.
- These tools offer intuitive interfaces, simplifying dashboard design and customization. They make it effortless to visualize crucial metrics, trends, and anomalies. Users can craft dynamic charts, graphs, and tables to gain insights and effectively communicate findings.
- Integration with Other Technologies:
- InfluxDB offers extensive integration capabilities, seamlessly integrating with various other technologies and tools in the data ecosystem.
- Whether integrating with data ingestion frameworks, analytics platforms, or visualization tools, InfluxDB provides robust APIs and connectors that streamline interoperability and data exchange.
- This integration flexibility enables users to seamlessly incorporate InfluxDB into existing workflows and toolchains, leveraging its strengths while complementing other technologies to craft comprehensive data solutions.
Getting Started with InfluxDB
To begin using InfluxDB, you must install it on your system first. InfluxDB provides various installation options, including binaries for operating systems, Docker containers, and cloud-based solutions. Select the installation method that aligns with your needs and refer to the instructions outlined in the documentation.
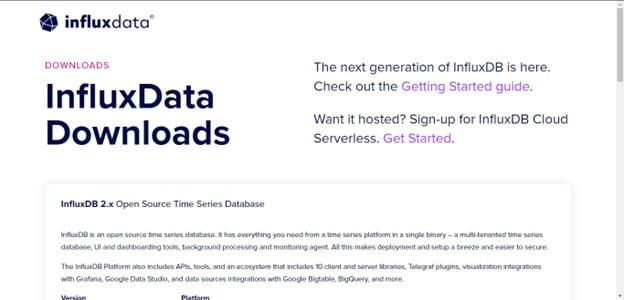
If you choose to install InfluxDB using binaries, visit the official InfluxDB downloads page and select the appropriate package for your operating system (e.g., Linux, macOS, Windows).
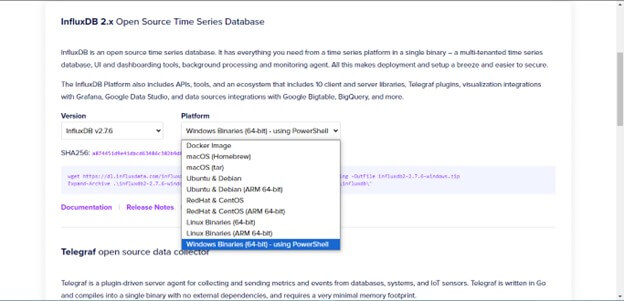
Once you select the operating system, you can see the code below. This code will help you install the InfluxDB on your system.
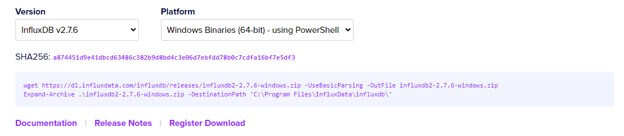
Run PowerShell as administrator and add the following code to install the InfluxDB.

You can check the folder in your destination path after completing the writing.
Now, From the PowerShell, navigate to the folder location.
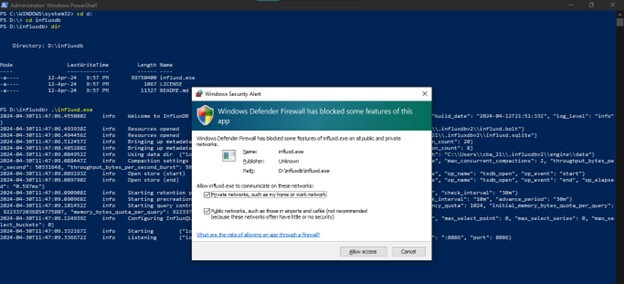
Once you run the commands in PowerShell, you will get the following pop-up: Allow the access, and you will get your port number.
Navigate to the port number on your browser, and the influx page redirects you.
Start setting up your account, and then you are good to go working on InfluxDB.

Use Cases for InfluxDB
- Monitoring Sensor Data (IoT):
InfluxDB proves highly effective for gathering, storing, and analyzing data from IoT gadgets like sensors, actuators, and other interconnected devices. Its capability to handle the massive volume and speed of data generated by IoT deployments makes it an optimal choice for monitoring environmental conditions, equipment status, and various sensor-driven metrics. Organizations leverage InfluxDB for IoT applications across intelligent buildings, agriculture, healthcare, and asset-tracking industries.
- Application Performance Monitoring (APM):
InfluxDB is a robust solution for real-time application and system performance monitoring. By gathering and analyzing metrics such as response times, error rates, and resource utilization, InfluxDB empowers organizations to understand application health and pinpoint performance bottlenecks. InfluxDB integrates with monitoring tools and frameworks in APM scenarios, offering comprehensive insights into application performance and user experience.
- Financial Time Series Analysis:
InfluxDB extensively analyzes financial time series data across banking, investment, and trading sectors. It enables organizations to store and retrieve sizeable financial data volumes, including stock prices, market indices, and trading volumes, with remarkable throughput and minimal latency. InfluxDB’s support for continuous queries and advanced analytics aids in identifying patterns, trends, and anomalies in financial data, enabling data-driven investment decisions and effective risk management.
- Industrial Automation and Control Systems:
InfluxDB is critical in collecting, storing, and analyzing data from sensors, Programmable Logic Controllers (PCLs), and SCADA systems in industrial automation. It facilitates real-time monitoring of equipment performance, production metrics, and process variables, enabling organizations to optimize manufacturing processes, enhance operational efficiency, and ensure regulatory compliance. InfluxDB seamlessly integrates with industrial IoT (IIoT) platforms and historian systems in industrial settings, providing a centralized data repository for monitoring critical infrastructure and supporting decision-making processes. Repository for monitoring critical infrastructure and supporting decision-making processes.
- Energy Consumption Monitoring:
Various sectors utilize InfluxDB to monitor energy consumption, including residential, commercial, and industrial. It enables organizations to track energy usage patterns, identify inefficiencies, and optimize energy consumption. InfluxDB helps organizations make informed decisions to reduce energy costs, improve sustainability, and adhere to regulatory standards by gathering and analyzing data from smart meters, building management systems, and energy monitoring devices.
- Healthcare Data Management:
InfluxDB is crucial in managing healthcare data, including patient monitoring, medical device data, and electronic health records (EHRs). It furnishes a scalable and dependable platform for storing and analyzing time-series data generated by medical devices, wearables, and healthcare systems. InfluxDB enables healthcare providers to track patient vitals in real-time, monitor disease progression, and improve patient outcomes through data-driven insights and predictive analytics.
- Environmental Monitoring and Climate Research:
InfluxDB supports environmental monitoring and climate research by providing a platform for storing and analyzing environmental data such as temperature, humidity, air quality, and weather patterns. Researchers and environmental agencies leverage InfluxDB to collect data from sensors, satellites, and weather stations, enabling them to study climate change, assess environmental impacts, and develop mitigation strategies. InfluxDB’s scalability and query capabilities empower scientists to analyze large datasets and derive actionable insights to address pressing environmental challenges.
Conclusion
InfluxDB offers a versatile and robust solution for managing time-series data, catering to diverse applications from IoT sensor monitoring to financial analysis and industrial automation. Its scalability, high performance, and flexibility meet the evolving needs of modern applications, providing a reliable foundation for real-time monitoring and analytics. Integration with visualization tools and support for continuous query processing enhance its value. InfluxDB facilitates extracting actionable insights from time-series data as organizations embrace data-driven insights for competitive advantage. InfluxDB is a trusted partner in leveraging time-series data for business success, whether monitoring infrastructure, analyzing financial metrics, or optimizing manufacturing.
Frequently Asked Questions (FAQs)
Q1. Can InfluxDB be used for anomaly detection?
Answer: Users can use InfluxDB for anomaly detection. It scrutinizes time-series data to detect deviations from anticipated patterns or behaviors. Leveraging continuous query processing alongside statistical methods and machine learning algorithms enables the identification of anomalies within the dataset.
Q2. What is the difference between InfluxDB Cloud and InfluxDB Enterprise?
Answer: InfluxDB Cloud is a fully managed cloud-based service provided by InfluxDB that offers scalable and reliable hosting for InfluxDB instances. InfluxDB Enterprise, on the other hand, is an on-premises solution that provides enterprise-grade features and support for deploying and managing InfluxDB clusters in private data centers.
Q3. What is the typical data ingestion rate supported by InfluxDB?
Answer: InfluxDB’s data ingestion capacity relies on factors like hardware setup, data volume, and workload traits. It is engineered to manage substantial throughput and can expand horizontally to adapt to growing data intake requirements.
Q4. How does InfluxDB handle data consistency and durability?
Answer: InfluxDB guarantees data consistency and durability by employing techniques like data replication, write-ahead logging, and consistency checks. Through replicating data across multiple nodes and maintaining write-ahead logs, InfluxDB ensures the persistence and uniformity of data, even if nodes fail or system crashe
