Updated June 30, 2023

Introduction to Indexes in Hive
Indexes are a pointer or reference to a table record, as in relational databases. Indexing is a relatively new feature in Hive. In the Hive, the index table is different than the main table. Indexes facilitate making query execution or search operation faster. However, storing indexes requires disk space, and creating an index involves cost. So, the use of indexes may not always be of any benefit. The “EXPLAIN” query must be checked to evaluate the benefit through a query execution plan. Indexing in Hive makes large dataset analysis relatively quicker by better query performance on operations.
Why do we need Indexes?
With the petabytes of data that need to be analyzed, querying Hive tables with millions of records and hundreds of columns becomes time-consuming. Indexing a table helps in performing any operation faster. First, the index of the column is checked, and then the operation is performed on that column only. Without an index, queries involving filtering with the “WHERE” clause would load an entire table and then process all the rows. Indexing in the Hive is present only for ORC file format, as it has a built-in index with it.
There are two types of indexing in the Hive:
- Bitmap Indexing: This is used with columns having a few distinct values. It is known to store both the indexed column’s value and the list of rows as a bitmap. From Hive V0.8.0 onwards, the bitmap index handler is built-in in Hive.
- Compact Indexing: This type of indexing is known to store the column value and storage block.
Configuration Properties
There is some configuration property that enables better execution of indexing.
- hive.optimize.index.filter: The default value for this property is false. Setting this property to TRUE will allow the automatic use of indexes.
- hive.index.compact.query.max.entries: The default value for this property is 10000000. This property sets the maximum number of index entries that use compact indexing during query execution.
- hive.optimize.index.filter.compact.minsize: The default value for this property is 5368709120.
This property sets the minimum bytes of input on which compact indexing can be automatically triggered.
Different Operations to Perform on Hive
Various Operations to Perform on HIVE indexes are:
1. Create an Index
The general syntax for creating an index for a column of a table
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS index_type
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name=property_value, ...)]
[IN TABLE index_table_name]
[ [ ROW FORMAT ...] STORED AS ...
| STORED BY ... ]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)]
[COMMENT "index comment"]
Here,
- index_name will be the name of the table’s index name.
- Base_table_name and the columns in bracket is the table for which the index will be created.
- Index_type will specify the type of indexing to use. If we want to use the built-in compact index handler, the below clause will replace index_type
org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler
If we want to create a bitmap index, then index_type will be “bitmap.” It specifies the java class for implementing indexing.
We must note that we can create any number and type of indexes for one table. But if the same column has multiple indexes created, then the index created first will be considered.
- WITH DEFERRED REBUILD: This statement must be present while creating an index because while altering the index later, we will be using this clause.
Consider an example of table mark_sheet with 3 columns: roll_id, class, days_attended.
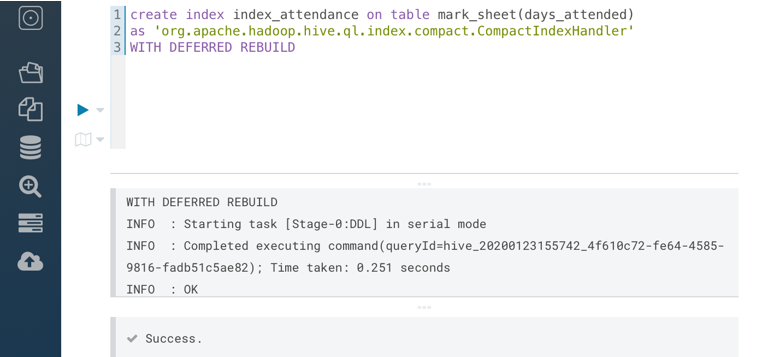
We are creating an index on the column days_attended using compact indexing with the below query:
create index index_attendance on table mark_sheet(days_attended)
As ‘org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler’
WITH DEFERRED REBUILD
Output in the HUE editor is:
2. Show an Index
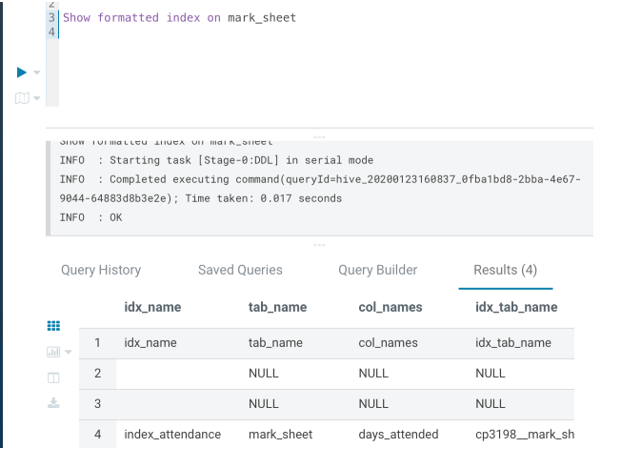
Use the following command to view the details of an index you created on a base table. This command will display information such as the index table name, the base table name, the name of the column on which you created the index, and the type of index handler you have used (compact or Bitmap).
Show formatted index on base_table_name
Output
3. Alter an Index
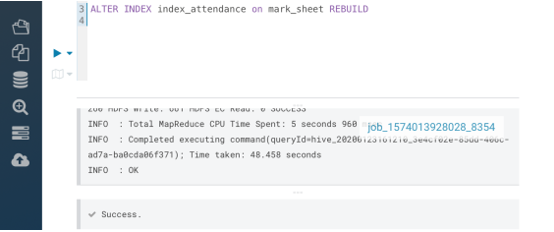
The syntax for altering an index is as seen below.
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD
This command ALTER INDEX….REBUILD is used to rebuild an index already built on a table. Partition details should also be provided if the base table has partitions. You need to rebuild the indexes if you overwrite or append the table.
Output
4. Drop an Index
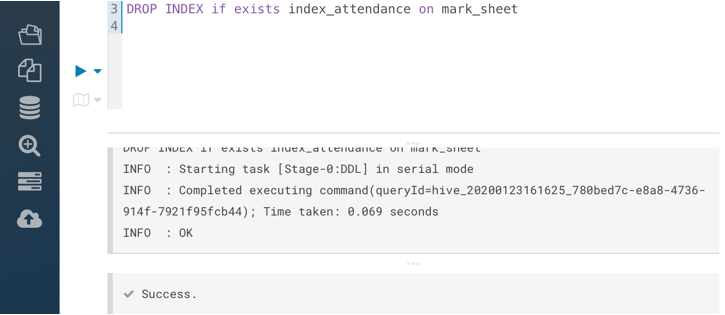
Use the following command to delete both the index and the table storing indexes.
DROP INDEX IF EXISTS index_name ON base_table_name
Automatically, the system will delete the index and the indexed table if someone drops the table on which the index was built. Dropping partitions in a table that has indexes will automatically delete the indexes.
Output
Advantages of Indexes in Hive
- Indexing in Hive provides a good replacement for partitioning when the number of partitions or logical sub-segments will be too many and small in size, to be of any worth.
- Indexes reduce the query execution time.
- Indexing in Hive helps in the case of traversing large data sets and also while building a data model.
- Indexing can be done for external tables or views, except when data is present in S3.
Conclusion
This tutorial taught us when and how to use indexes in the Hive. We also came across its advantage over conventional query building in the Hive. However, it is important to note that indexes should be preferred if a frequent operation is performed on any column. Indexes can also degrade the query performance if used recklessly because of the disk space involved in creating an index table. In RDMS, the primary key acts as an index to a table, but Hive indexes have their inherent advantages.
Recommended Articles
This is a guide to Indexes in Hive. Here we discuss the basic concept, why we need Indexes, different operations performed on the Hive, and advantages. You can also go through our other related articles to learn more–
