Updated March 27, 2023
Introduction to External Table in Hive
An external table is a table that describes the schema or metadata of external files. Fundamentally, there are two types of tables in HIVE – Managed or Internal tables and external tables. The primary purpose of defining an external table is to access and execute queries on data stored outside the Hive. These data files may be stored in other tools like Pig, Azure storage Volumes (ASV) or any remote HDFS location. Hive assumes that it has no ownership of the data for external tables, and thus, it does not require to manage the data as in managed or internal tables. Also, for external tables, data is not deleted on dropping the table.
Working and Creating External tables in Hive
By default, in Hive table directory is created under the database directory. The exception is the default database. The location user/hive/warehouse does not have a directory so that the default database tables will have its directory directly created under this location. It is recommended to create external tables if we don’t want to use the default location.
An external table is generally used when data is located outside the Hive.
Let us create an external table using the keyword “EXTERNAL” with the below command.
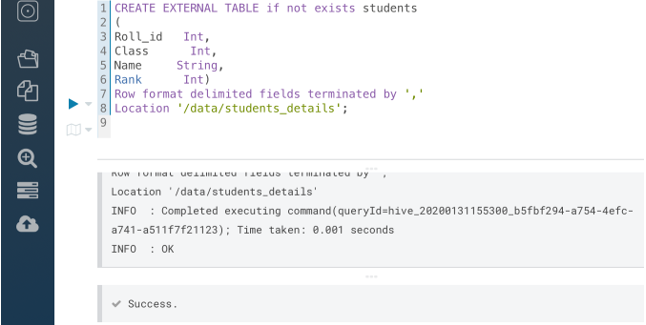
CREATE EXTERNAL TABLE if not exists students
(
Roll_id Int,
Class Int,
Name String,
Rank Int)
Row format delimited fields terminated by ‘,’
Location ‘/data/students_details’;
Output:
An external table can also be created by copying the schema and data of an existing table, with below command:
CREATE EXTERNAL TABLE if not exists students_v2 LIKE students
Location ‘/data/students_details’;
If we omit the EXTERNAL keyword, then the new table created will be external if the base table is external. Similarly, if the base table is managed with the external keyword, the new table created will be external.
To identify the type of table created, the DESCRIBE FORMATTED clause can be used. At the end of the detailed table description output table type will either be “Managed table” or “External table”.
Partitioned tables help in dividing the data into logical sub-segments or partitions, making query performance more efficient. A partitioned table can be created as seen below.
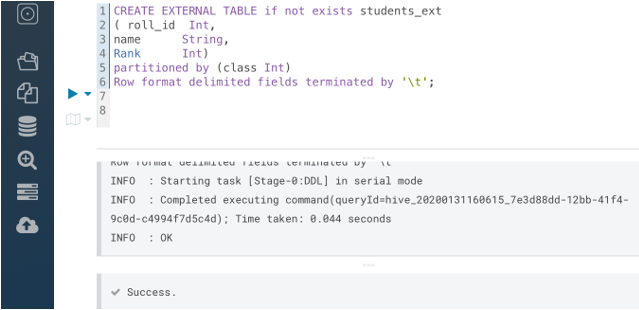
CREATE EXTERNAL TABLE if not exists students
( roll_id Int,
name String,
Rank Int)
partitioned by (class Int)
Row format delimited fields terminated by ‘\t’
Output:
There May Be Instances when Partition or Structure of An External Table Is Changed, Then by Using This Command the Metadata Information Can Be Refreshed:
MSCK REPAIR TABLE external_table_name
1. Partitioned external table
While creating a non-partitioned external table, the LOCATION clause is required. But for a partitioned external table, it is not required. ALTER TABLE statement is required to add partitions along with the LOCATION clause.
ALTER TABLE students ADD PARTITION (class =10)
Location ‘here://master_server/data/log_messages/2012/01/02’;
From Hive v0.8.0 onwards, multiple partitions can be added in the same query. Also, the location for a partition can be changed by below query, without moving or deleting the data from the old location.
ALTER TABLE students_v2 partition( class = 10)
Set location ‘s2n://buckets/students_v2/10’;
To drop a partition, below query is used:
ALTER TABLE students DROP IF EXISTS PARTITION (class = 12);
This command will delete the data and metadata of the partition for managed or internal tables. However, for external tables, data is not deleted.
2. Operations on the external table
The operations like SELECT, JOINS, ORDER BY, GROUP BY, CLUSTER BY, and others are implemented on external tables. External tables can be easily joined with other tables to carry out complex data manipulations. Concepts of Partitioning, bucketing and indexing are also implemented on external tables in the same way as for managed or internal tables. All the configuration properties in Hive are applicable to external tables also. For example, by setting skip.header.line. Count = 1, we can skip the header row from the data file.
All File formats like ORC, AVRO, TEXTFILE, SEQUENCE FILE, or PARQUET are supported for Hive’s internal and external tables. On creating a table, positional mapping is used to insert data into the column, and that order is maintained.
Datatypes in external tables: In external tables, the collection data types are also supported along with primitive data types (like integer, string, character). It is necessary to specify the delimiters of the elements of collection data types (like an array, struct, and map).
When to use External Tables in Hive?
Generally, internal tables are created in Hive. But for certain scenarios, an external table can be helpful. These are:
- When data is placed outside the Hive or HDFS location, creating an external table helps as the other tools that may be using the table, places no lock on these files.
- An external table can be created when data is not present in any existing table (i.e., using the SELECT clause).
- The external table must be created if we don’t want Hive to own the data or have other data controls.
- The external table also prevents any accidental loss of data, as on dropping an external table, the base data is not deleted. This acts as a security feature in the Hive. This is the reason why TRUNCATE will also not work for external tables.
Features
There are certain features in Hive which are available only for either managed or external tables. These are:
- Commands like ARCHIVE/UNARCHIVE/TRUNCATE/CONCATENATE/MERGE works only for internal tables.
- The ACID works only for managed or internal tables.
- DROP clause will delete only metadata for external tables. However, it deletes underlying data also for internal tables.
- Query results caching is possible only for managed tables.
- RELY constraint is allowed on external tables only.
- Some features of materialized views work only for managed tables.
Conclusion
In this tutorial, we saw when and how to use external tables in Hive. The highlights of this tutorial are to create a background on the tables other than managed and analyzing data outside the Hive.
Recommended Articles
This is a guide to External Table in Hive. Here we discuss introducing External Tables in the Hive and the Features, and Queries. You can also go through our other related articles to learn more –
