Updated August 10, 2023

Introduction to Map Join in Hive
Map join is a feature used in Hive queries to increase its efficiency in terms of speed. Join is a condition used to combine the data from 2 tables. So, when we perform a normal join, the job is sent to a Map-Reduce task which splits the main task into 2 stages – “Map stage” and “Reduce stage”. The Map stage interprets the input data and returns output to the reduce stage in the form of key-value pairs. This next goes through the shuffle stage where they are sorted and combined. The reducer takes this sorted value and completes the join job.
A table can be loaded into the memory completely within a mapper without using the Map/Reducer process. It reads the data from the smaller table and stores it in an in-memory hash table and then serializes it to a hash memory file, thus substantially reducing the time. It is also known as Map Side Join in Hive. Basically, it involves performing joins between 2 tables by using only the Map phase and skipping the Reduce phase. A time decrease in your queries’ computation can be observed if they regularly use a small table joins.
The syntax for Map Join in Hive.
If we want to perform a join query using map-join then we have to specify a keyword “/*+ MAPJOIN(b) */” in the statement as below:
SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
For this example, we need to create 2 tables with names tablename1 and tablename2 having 2 columns: emp_id and emp_name. One should be a larger file, and one should be a smaller one.
Before running the query, we have to set the below property to true:
hive.auto.convert.join=true
The join query for map join is written as above, and the result we get is:
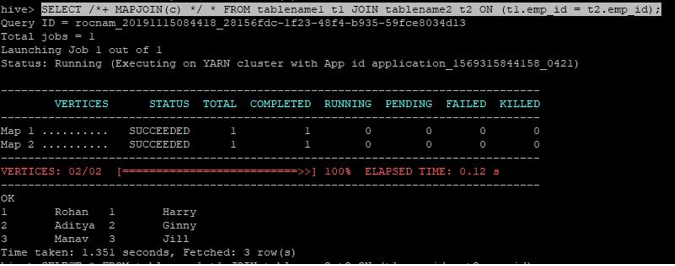
The query got completed in 1.351 seconds.
Examples of Map Join in Hive
Here are the following examples mention below
1. Map join example
For this example, let us create 2 tables named table1 and table2 with 100 and 200 records. You can refer the below command and screenshots for executing the same:
CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ',' tblproperties("skip.header.line.count"="1");
CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ',' tblproperties("skip.header.line.count"="1");

Now we load the records into both the tables using below commands:
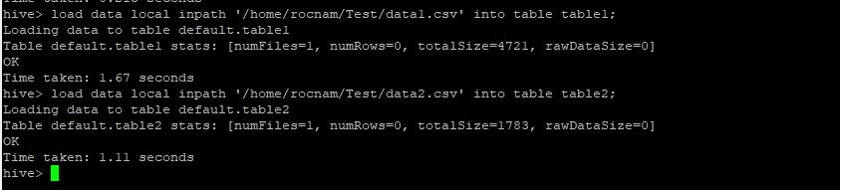
load data local inpath 'https://cdn.educba.com/relativePath/data1.csv' into table table1;
load data local inpath 'https://cdn.educba.com/relativePath/data2.csv' into table table2;
Let us perform a normal map-join query on their ID’s as shown below and verify the time taken for the same:
SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id,table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
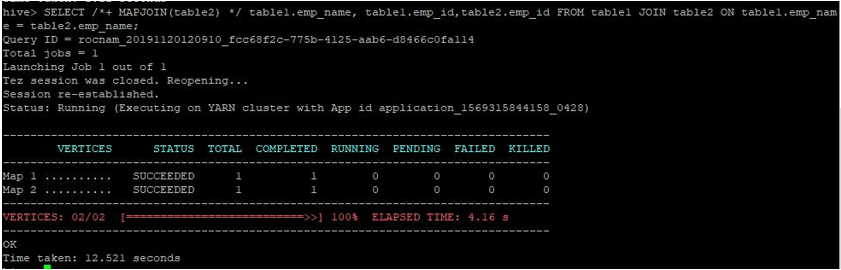
As we can see, a normal map-join query took 12.521 seconds.
2. Bucket-Map Join Example
Let us now use Bucket-map join to run the same. There are a few constraints which need to be followed for bucketing:
- The buckets can be joined with each other only if the total buckets of any one table are multiple of the other table’s number of buckets.
- Must have bucketed tables to perform bucketing. Hence let us create the same.
Following are the commands used to create bucketed tables table1 and table2:
CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ',';
CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ',' ;

We shall insert the same records from table1 into these bucketed tables as well:
insert into table1_buk select * from table1;
insert into table2_buk select * from table2;
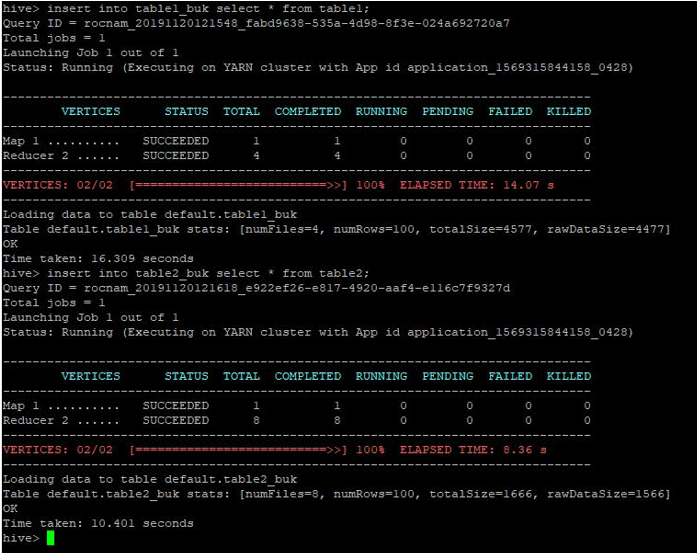
Now that we have our 2 bucketed tables, let us perform a bucket-map join on these. The first table has 4 buckets whereas the second table has 8 buckets created on the same column.
For the bucket-map join query to work, we should set the below property to true in the hive:
set hive.optimize.bucketmapjoin = true
SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name,table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
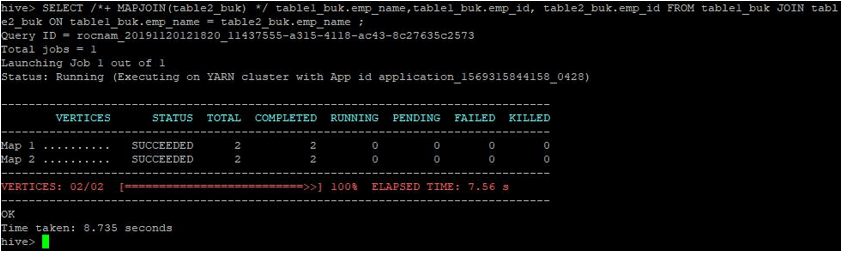
As we can see, the query got completed in 8.735 seconds which is faster than a normal map join.
3. Sort Merge Bucket Map Join Example (SMB)
SMB can be performed on bucketed tables having the same number of buckets and if the tables need to be sorted and bucketed on join columns. Mapper level joins these buckets correspondingly.
Same as in Bucket-map join, there are 4 buckets for table1 and 8 buckets for table2. For this example, we shall create another table with 4 buckets.
To run SMB query, we need to set the following hive properties as shown below:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
To perform SMB join, there needs to be data sorted as per the join columns. Hence, we overwrite the data in table1 bucketed as below:
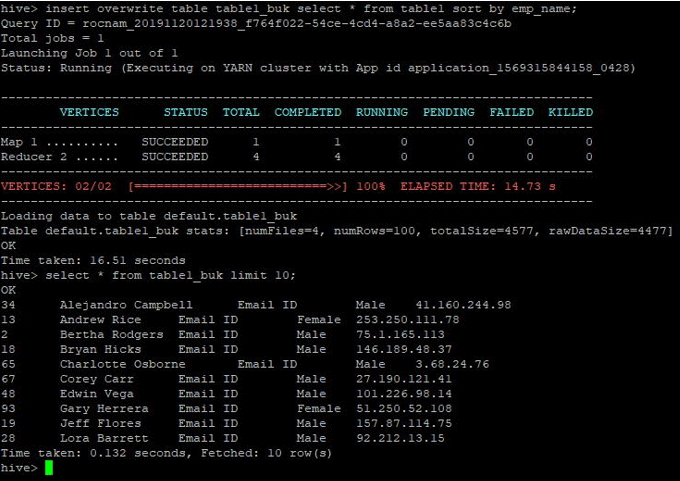
insert overwrite table table1_buk select * from table1 sort by emp_name;
The data is sorted now which can be seen in the below screenshot:
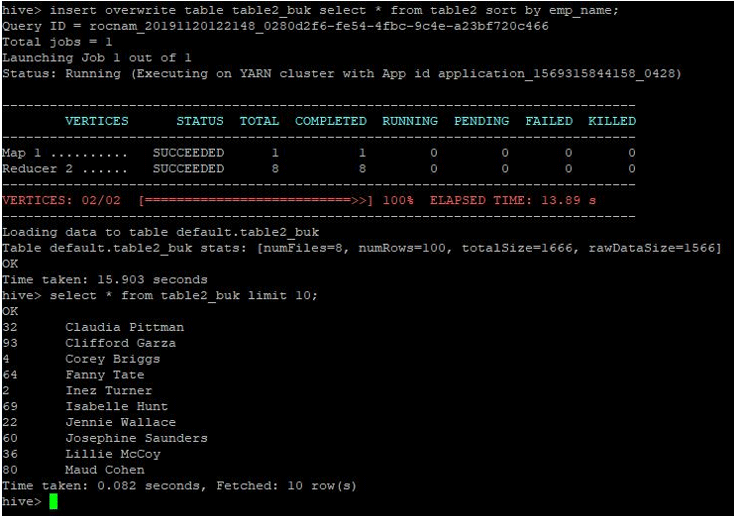
We shall also overwrite data in bucketed table2 as below:
insert overwrite table table2_buk select * from table2 sort by emp_name;
Let us perform the join for above 2 tables as follows:
SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name,table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
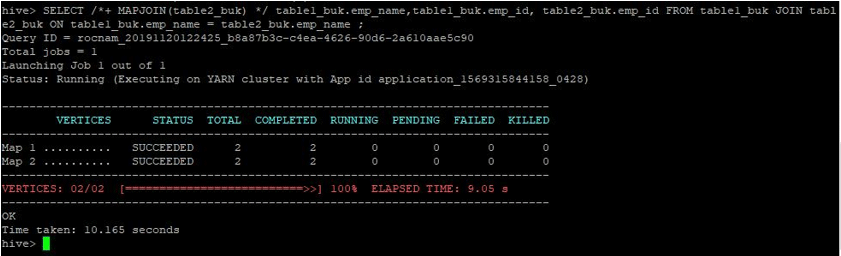
We can see that the query took 10.165 seconds which is again better than a normal map join.
Let us now create another table for table2 with 4 buckets and the same data sorted with emp_name.
CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int,emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ',' ;
insert overwrite table table2_buk1 select * from table2 sort by emp_name;
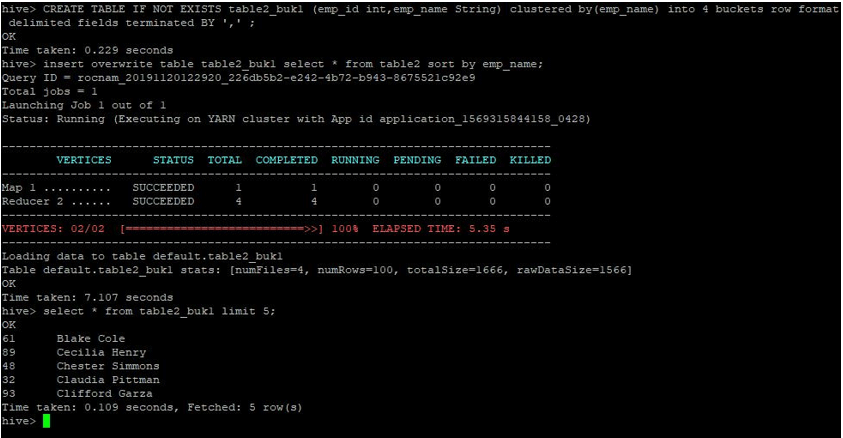
Considering that we now have both tables with 4 buckets, let us again perform a join query.
SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
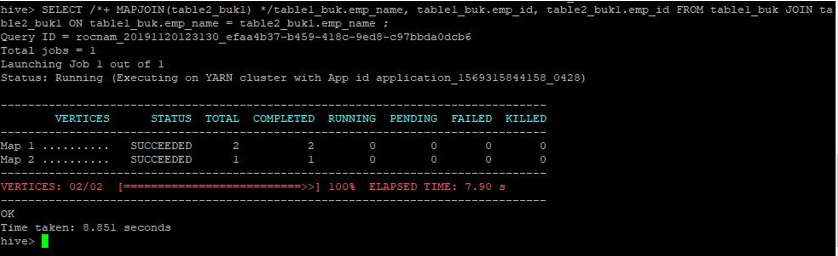
The query has retaken 8.851 seconds faster than the normal map join query.
Advantages
- Map join reduces the time taken for sort and merge processes in the shuffle and reduces stages, thus minimizing the cost.
- It increases the performance efficiency of the task.
Limitations
- The same table/ alias is not allowed to join different columns in the same query.
- Map join query cannot convert Full outer joins into the map side joins.
- Map join can be performed only when one of the tables is small enough so that it can be fit to the memory. Hence it cannot be performed where the table data is huge.
- A left join is possible to be done to a map join only when the right table size is small.
- A right join can be done to a map join only when the left table size is small.
Conclusion
We have tried to include the best possible points of Map Join in Hive. As we have seen above, Map-side join works best when one table has less data so that the job gets completed quickly. The time taken for the queries shown here depends on the dataset’s size; hence the time shown here is only for analysis. Map join can easily be implemented in real-time applications since we have huge data, thus reducing network I/O traffic.
Recommended Articles
This is a guide to Map Join in Hive. Here we discuss the examples of Map Join in Hive along with the Advantages and Limitations. You may also look at the following article to learn more –
