Updated March 27, 2023

Introduction to Hive Cluster By
CLUSTER BY is a clause or command 4used in Hive queries to carry out DISTRIBUTE BY and SORT BY operations. This command ensures total ordering or sorting across all output data files. DISTRIBUTE BY clause functions to 3.
Map how the output is divided among reducers in a MapReduce job. DISTRIBUTE BY has a similar job as a GROUP BY clause as it manages how the reducer will receive data or rows for processing. However, the SORT BY command helps in achieving sorting within each reducer output.
Working of Hive Cluster By
- CLUSTER BY x: ensures that each of the N reducers gets non-overlapping sets, then sorts at the reducers by those ranges. It gives you universal ordering and is the same as doing (SORT BY x and DISTRIBUTE BY x). You end up with non-overlapping ranges on N or more sorted files.
- Cluster By is generally used for the Map-Reduce Scripts. It is also widely used to sort or partition results from queries as in SELECT statements on tables.
- CLUSTER BY’s number of partitions will dictate how many files will be generated, which will be distributed in-memory based on the hash of the column combination values listed in CLUSTER BY. Writing these files to the disk will result in a redistribution based on the hash of the combination of values of the columns listed in CLUSTERED BY.
When to use Hive Cluster By?
- When data is skewed: If most of the rows are placed on a small number of partitions, the DataFrame is skewed, while most partitions remain empty. A circumstance like that really should be avoided. Why? For what? This makes the plan practically not simultaneous-most of the time you are waiting to complete a single mission. Even worse, you can run out of memory on some executors in some cases, or cause an unnecessary spill of data to a disk. All of this can happen if your data isn’t distributed evenly. Choose something that you know will distribute the data uniformly for the expression to partition by. You can repartition the data using CLUSTER BY to deal with the skew.
- Sorting in Multiple joins: If you join two DataFrames, Hive will use the join expressions to repartition them both. It means that if you enter the same DataFrame multiple times (each time using the same expressions), Hive must repartition it DataFrame every time. In Hive, CLUSTER BY will help re-partition both by the join expressions and sort them inside the partitions.
Examples of Hive Cluster By
Let us consider an example better to understand the working of “CLUSTER BY” clause.
Example #1
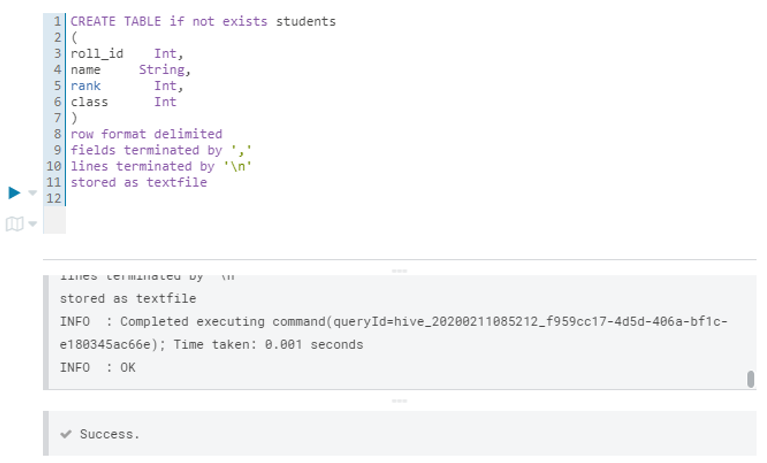
Let us create a Hive table and then load some data in it using CREATE and LOAD commands. This is a table with student details like name, roll number, class, and student rank.
Code:
CREATE TABLE if not exists students
(
roll_id Int,
name String,
rank Int,
class Int
)
row format delimited
fields terminated by ‘,’
lines terminated by ‘\n’
stored as textfile
Output:
After creating the tables’ schema, let us load some rows of data into the table as well.
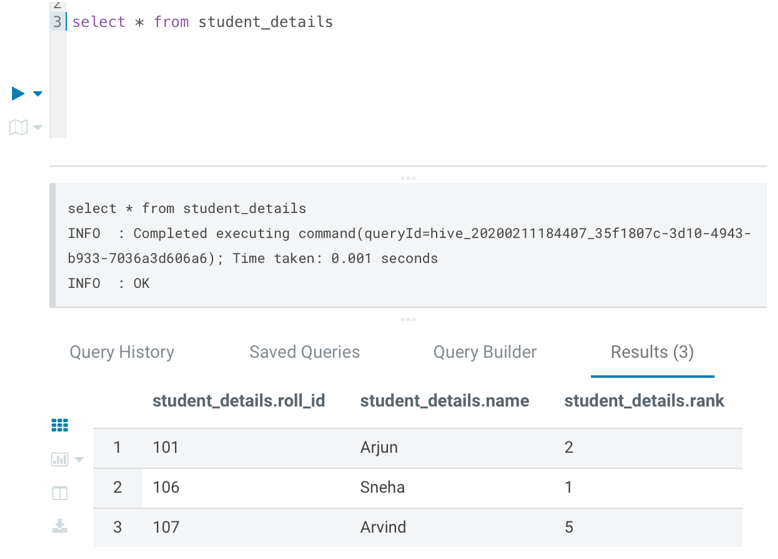
select * from students_details;
The output after loading data into the table students is:
Output:
Example #2
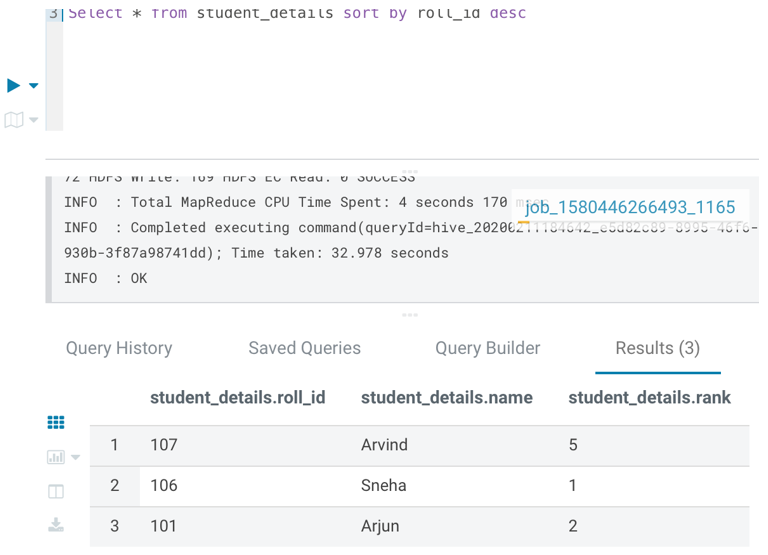
Let us perform some data manipulation on this table. We can perform SORT BY clause on students’ tables to sort the roll ids of students in descending order.
Code:
Select * from student_details sort by roll_id desc;
Output:
Example #3
Also, we can sort the table to obtain the highest-ranked student first, using the below query:
Code:
Select * from student_details sort by rank desc limit 1;
By default, sorting happens in ascending order if nothing is explicitly specified. For column types with the numerical data type, sorting happens in numeric order. However, if the column type is a string, the lexicographical order of sorting is applied.
SORT BY is different from ORDER BY as it performs local ordering or ordering data within each reducer while ORDER BY ensures complete ordering across the whole data set. ORDER BY may lead to a very long execution run time. So, hive property hive.mapred.mode is set to strict about limiting such long execution times. This property is set to non-strict by default.
In Hive 2.1.0 onwards, for the “order by” clause, NULL values are kept first for ASC sorting technique and last for DESC sorting technique.
For Hive 3.0.0 onwards, the limits for tables or queries are deleted by the optimizer in a “sort by” clause. Using this hive configuration property, hive.remove.orderby.in.subquery as false, we can stop this by the optimizer.
Example #4
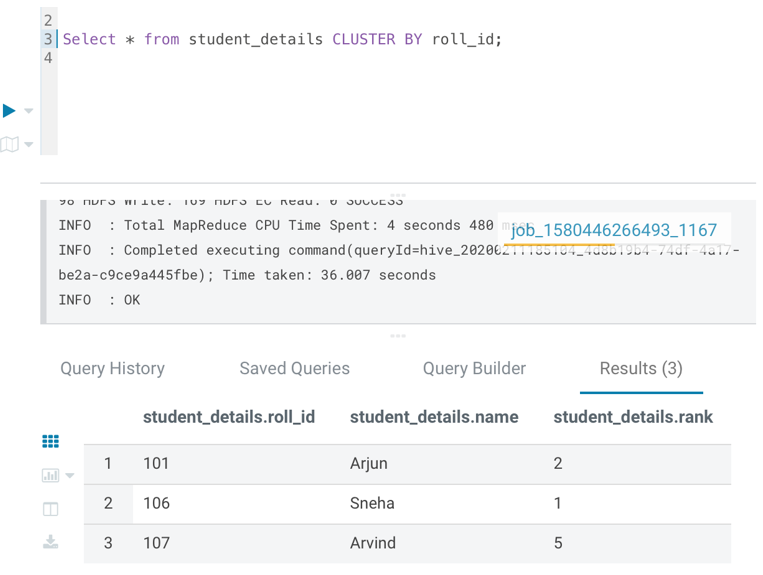
Also, we can perform DISTRIBUTE BY operation on table students in Hive. This clause has a definite function to perform. It is specifically used to distribute the rows among reducers basis the column mentioned after “DISTRIBUTE BY”. This does not perform the sorting of the output in each reducer.
Code:
Select * from student_details CLUSTER BY roll_id;
The output as per HUE Editor is :
Conclusion
These are SQL like command or clause, which facilitates ETL such as extraction, transformation, and loading or summarising data in the Hadoop ecosystem. We can also say that CLUSTER BY is an alternative to DISTRIBUTE BY and SORT BY combined. These data manipulation language (DML) queries work with tables, databases or views easily. CLUSTER BY can lead to complete ordering of data for tables. Instead of specifying Cluster By, the user may specify Distribute By and Sort By, so that the columns of the partitions and the columns of sorting can differ.
Recommended Articles
This is a guide to Hive Cluster By. Here we discuss the working of Hive Cluster By and when to use it along with respective examples. You can also refer to our other related articles to learn more –
