Updated May 11, 2023

Introduction To Hive Architecture
Hive architecture helps in determining the hive Query language and the interaction between the programmer and the Query language using the command line since it is built on top of the Hadoop ecosystem it has frequent interaction with the Hadoop and is, therefore, copes up with both the domain SQL database system and Map-reduce, Its major components are Hive Clients(like JDBC, Thrift API, ODBC Applications, etc.), Hive servers and Hive storage a.k.a meta storage.
Hive Architecture with its components
Hive plays a major role in data analysis and business intelligence integration, and it supports file formats like text file, rc file. Hive uses a distributed system to process and execute queries, and the storage is eventually done on the disk and finally processed using a map-reduce framework. It resolves the optimization problem found under map-reduce and hive perform batch jobs which are clearly explained in the workflow. Here a meta store stores schema information. A framework called Apache Tez is designed for real-time queries performance.
The major components of the Hive are given below:
- Hive clients
- Hive Services
- Hive storage (Meta storage)
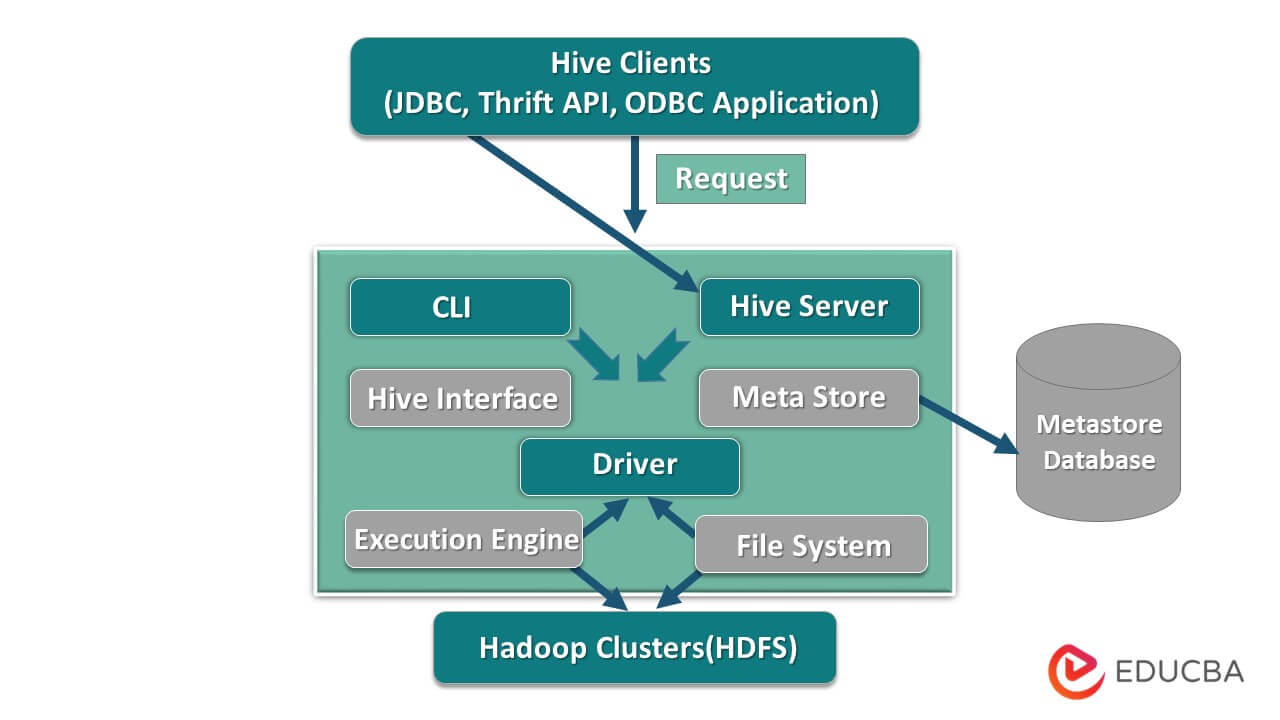
The above diagram shows the architecture of the Hive and its component elements.
Hive Clients
They include Thrift application to execute easy hive commands which are available for python, ruby, C++, and drivers. These client application benefits for executing queries on the hive. Hive has three types of client categorization: thrift clients, JDBC, and ODBC clients.
Hive Services
To process all the queries hive has various services. All the functions are easily defined by the user in the hive. Let’s see all those services in brief:
- Command-line interface (User Interface): It enables interaction between the user and the hive, a default shell. It provides a GUI for executing hive command line and hive insight. We can also use web interfaces (HWI) to submit the queries and interactions with a web browser.
- Hive Driver: It receives queries from different sources and clients like thrift server and does store and fetching on ODBC and JDBC driver which are automatically connected to the hive. This component does semantic analysis on seeing the tables from the metastore, which parses a query. The driver takes the help of compiler and performs functions like a parser, Planner, Execution of MapReduce jobs and optimizer.
- Compiler: Parsing and semantic process of the query is done by the compiler. It converts the query into an abstract syntax tree and again back into DAG for compatibility. The optimizer, in turn, splits the available tasks. The job of the executor is to run the tasks and monitoring the pipeline schedule of the tasks.
- Execution Engine: All the queries are processed by an execution engine. A DAG stage plans are executed by the engine and help in managing the dependencies between the available stages and execute them on a correct component.
- Metastore: It acts as a central repository to store all the structured information of metadata also it’s an important aspect part for the hive as it has information like tables and partitioning details and the storage of HDFS files. In other words, we shall say metastore acts as a namespace for tables. Metastore is considered to be a separate database that is shared by other components too. Metastore has two pieces called service and backlog storage.
The hive data model is structured into Partitions, buckets, tables. All these can be filtered, have partition keys and to evaluate the query. Hive query works on the Hadoop framework, not on the traditional database. Hive server is an interface between a remote client queries to the hive. The execution engine is completely embedded in a hive server. You could find hive application in machine learning, business intelligence in the detection process.
Work Flow of Hive
Hive works in two types of modes: interactive mode and non-interactive mode. Former mode allows all the hive commands to go directly to the hive shell while the later type executes code in console mode. Data are divided into partitions which further splits into buckets. Execution plans are based on aggregation and data skew. An added advantage of using hive is it easily processes large scale of information and has more user interfaces.
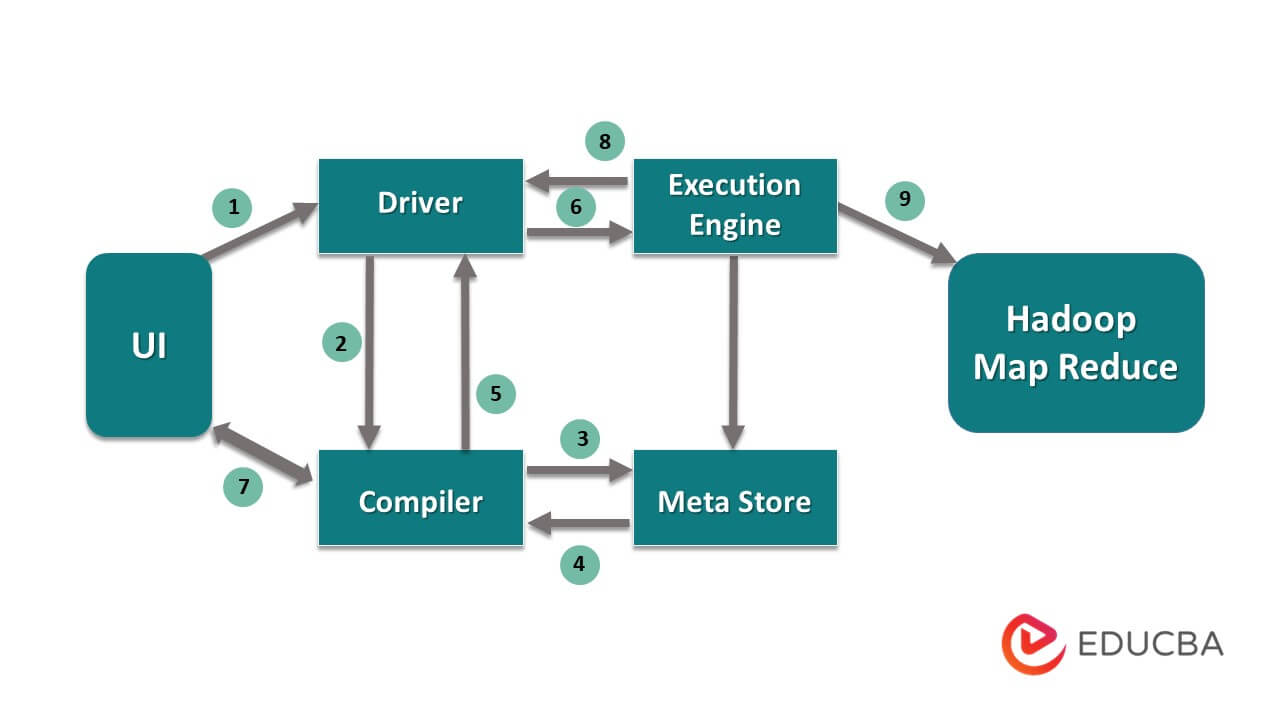
From the above diagram, we can have a glimpse of data flow in the hive with the Hadoop system.
The steps include:
- execute the Query from UI
- get a plan from the driver tasks DAG stages
- get metadata request from the meta store
- send metadata from the compiler
- sending the plan back to the driver
- Execute plan in the execution engine
- fetching results for the appropriate user query
- sending results bi-directionally
- execution engine processing in HDFS with the map-reduce and fetch results from the data nodes created by the job tracker. it acts as a connector between Hive and Hadoop.
The job of the execution engine is to communicate with nodes to get the information stored in the table. Here SQL operations like create, drop, alter are performed to access the table.
Conclusion
We have gone through Hive Architecture and their working flow, hive basically performs petabyte amount of data, and hence it’s a data warehouse package on the Hadoop platform. As hive is a good choice for handling high data volume, it helps in data preparation with the guide of SQL interface to solve the MapReduce issues. Apache hive is an ETL tool to process structured data. Knowing the working of hive architecture helps corporate people to understand the principle working of the hive and has a good start with hive programming.
Recommended Articles:
This has been a guide to Hive Architecture. Here we discuss the hive architecture, different components, and workflow of the hive. you may also look at the following articles to learn more-
