Updated March 6, 2023

Introduction to HDFS File System
In the Hadoop stack, we are having the HDFS service to manage the complete storage part of the Hadoop. It is a distributed file system. It is capable to handle a huge amount of data. One major advantage of the HDFS file system, it will run on commodity hardware. It means, there is no requirement for any specific hardware. In the single Hadoop cluster environment, we can add thousands of data nodes to store the data in the HDFS file system. In Hadoop, the most of services are dependent on the HDFS file system to store the data.
Syntax :
As such, there is no specific syntax available for the HDFS file system. Generally, we are using the number of services on it. As per the requirement or need, we can use the necessary components and use the appropriate syntax of it.
How HDFS File System Works?
The Hadoop file system is a distributed file system. The file system is scalable and portable. It is written in Java language for the Hadoop framework. In Hadoop, there are two major things, first is HDFS and second is MapReduce. The HDFS or HDFS file system is used to store the data. The MapReduce part is used for data processing.
In the HDFS, below are the services that make it more scalable, portable, robust, etc.
- Name Node
- Data Node
- Secondary Name Node
- Job Tracker
- Task Tracker
1. Name Node
In the HDFS file system, the namenode is master Daemons or Services or Nodes. All the master services will communicate with each other. In the HDFS file system, it will consist of the single instance of the Name Node that is active. It is known as the namenode. The namenode will able to track the files, blocks, manage the file system. It will also manage the HDFS file system metadata.
The metadata is having the detail information of a file or block-level information on HDFS level. In specific, the namenode is having the details information of the count of blocks, locations of the files or data on the data node. It will also take care of the HDFS file replication part. The HDFS namenode has direct contact with the HDFS client.
2. Data Node
The datanode is master Daemons or Services or Nodes. The datanode is responsible to store the actual file on the HDFS level. It will store the data in terms of blocks. When the client request for the data then the actual data will share by the datanode only. (Here, namenode will only share the information of the data or file block information). The datanode is a slave daemon. By default, every datanode will send the heartbeat information to the namenode in every 3 seconds. It will help for the namenode to identify the datanode is in a live state.
The same process will be going on. If in case, the datanode will not able to send the heartbeat to the namenode (till 2 mins) then the namenode will consider the datanode will dead. If the data node will dead then we are not able to fetch the data on the dead datanode. To avoid this condition, we are having a replication factor. In the HDFS, we are having the replication factor 3. It means that on the HDFS file system, we are having the 3 copy of file or data on the different datanode. If one or two datanodes will fail then there is no issue, we will serve the request from the last copy of the data. It will all manage by the namenode.
3. Secondary Name Node
In the Hadoop file system, the secondary namenode is master Daemons or Services or Nodes. The secondary namenode is also known as the checkpoint node. It is responsible to take care of the metadata checkpoints of the HDFS file system. It will take the metadata information from the active namenode and do the checkpoint. If any issues may happen on the namenode and the namenode may down then the secondary namenode will come in to picture and serving the role of the namenode to the Hadoop ecosystem.
The editlog is a key point to sync up with the live namenode and the secondary namenode. The editlog is responsible to make the secondary namenode will become the active namenode. The editlog will give the detail information to the secondary namenode what was the last update of the namenode from the same information the secondary namenode will start their work and become active (as namenode).
4. Job Tracker
The job tracker is Slave Service. From the client, the MapReduce execution request will receive the job tracker. The job tracker will communicate with the active namenode. The namenode will share the information in terms of the data location. The same data location information will be used for job processing. The active namenode will respond to the block metadata information for the requestor required process of HDFS data.
5. Task Tracker
The task tracker is one of the slave Service. The job tracker will share the job-related information to the task tracker. Most of the time, the task tracker will take the task-related information from the job tracker. It will also responsible to get the overview of the entire task those are running on the HDFS level.
HDFS File System Overview
In the Hadoop environment, we are having the system to store the data in distributed mode. It is scalable and portable also.
Syntax:
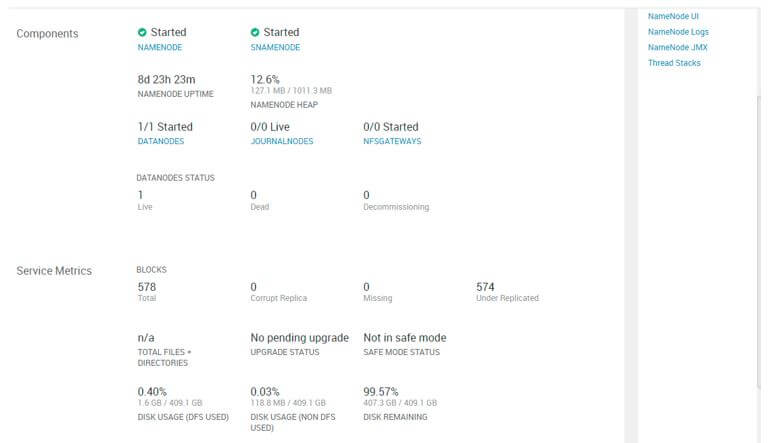
In the HDFS summery, we can get the HDFS file system information.
Explanation:
- As per the below command, we will get a detailed overview of the HDFS file system.
Output:
Conclusion
We have seen the uncut concept of “HDFS File System” with the proper example, explanation and output. This system is used to store a huge amount of data. It is scalable up to thousands of nodes. By default, we are having replication factor 3.
Recommended Articles
This is a guide to HDFS File System. Here we discuss the introduction, how HDFS file system works? and file system overview. You may also have a look at the following articles to learn more –
