Updated March 4, 2023
Introduction to Hadoop Stack
The Hadoop stack is nothing but a set of software or software libraries. The Hadoop stack is the framework is providing the functionality to process a huge amount of data or dataset in a distributed manner. As per the requirement or use case, we need to choose the different Hadoop stack. For the batch process, we will use the HDP stack. For the live data processing, we will use the HDF stack. As we said, HDP and HDF both are different as well as the services is also different. In the HDP stack, we will get the HDFS, Yarn, Oozie, MapReduce, Spark, Atlas, Ranger, Zeppelin, Hive, HBase, etc. In the HDF stack, we will get the Kafka, NiFi, schema registry, and all.
Syntax:
As such, there is no specific syntax available for the Hadoop Stack. As per the requirement or need, we can use the necessary components of the HDP or HDF environment and use the appropriate syntax of it. As per the requirement, we need to use the proper syntax of the individual component. Before using the syntax, first please make sure the working method. Because every component is different in the Hadoop stack.
How Hadoop Stack Works?
As we have discussed, Hadoop is a technology or framework to process a huge amount of data in a distributed manner. While process the huge amount of data from the traditional databases will not suffice the need and most of the time it will take a huge amount of time. In some cases, it will through an error like out of memory, etc. To avoid this condition, we are having the Hadoop stack or Hadoop technology. It will load a huge amount of data in terms of TB or more and process it in a distributed model. It is processing on the terms of the mapper and reducer mode. Generally, the mapper is deal with the process mechanism and the reducer is deal with the input and output operation.
Note: To build the Hadoop cluster, we need a wide infrastructure in terms of resources (RAM and CPU), storage, etc. If we are having fewer resources then we can deploy the fewer services on the cluster i.e. as per the requirement, we can deploy the services.
Below is the screenshot of Hadoop Stack and version information.
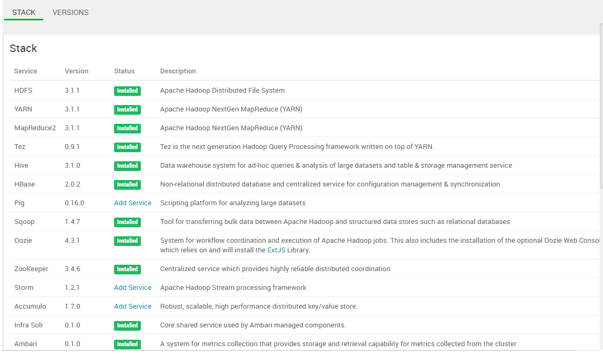
Below is the list of services which is a part of the Hadoop Stack
1. HDFS
As we have discussed, the Hadoop Stack is distributed on the number of data nodes. The HDFS file system is designed for high scalability, reliability, fault-tolerant. In the Hadoop Stack, we are having the replication concept. By default, the data or the file will be distributed on different 3 nodes. In some cases, if we will face any issues on any data node but still we will get the data because we are having the 3 copies of the data.
Screenshot:
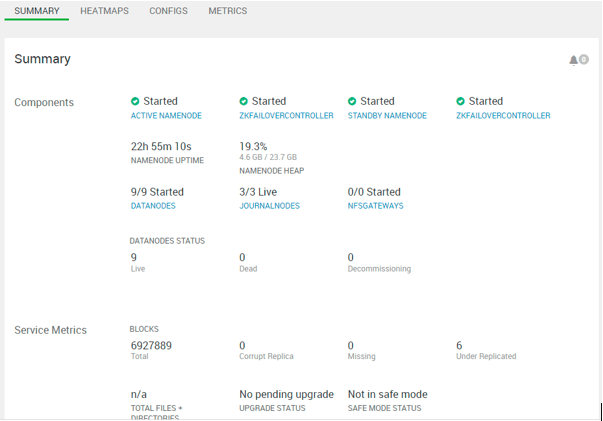
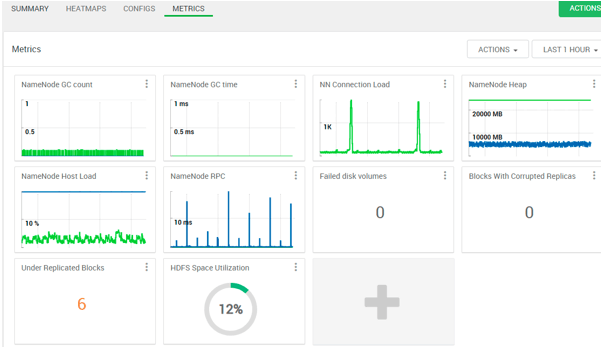
Explanation:
As per the above screenshot, we have seen the HDFS service summary. In the matrix, we are getting the statistics of different components that are available in the HDFS service.
2. Yarn
In Hadoop stack, yarn service is a very important service in terms of resource allocation. When any job will submit on the Hadoop environment. The yarn is responsible to allocate the resources to execute the job. The node manager is having the complete responsibility to execute the job.
Screenshot:
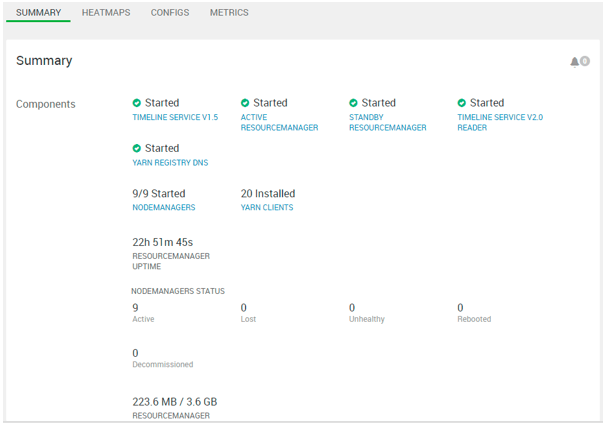
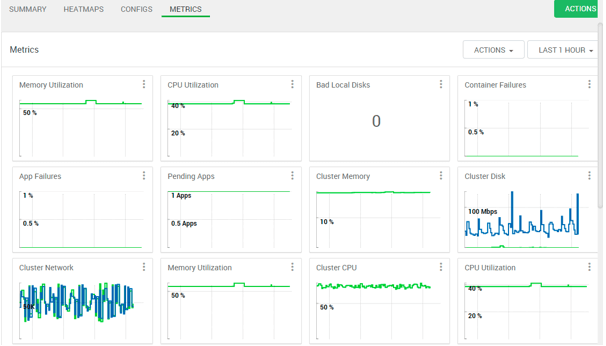
Explanation:
We have seen the yarn service summary. In yarn matrix, we are getting the diagrammatic representation of different component that is available in the yarn service.
3. Oozie
In the Hadoop ecosystem, the oozie is responsible to schedule a job. We can schedule any type of job like the hive, HBase, spark, etc. As per the requirement, we can schedule the job at a specific time interval.
Screenshot:
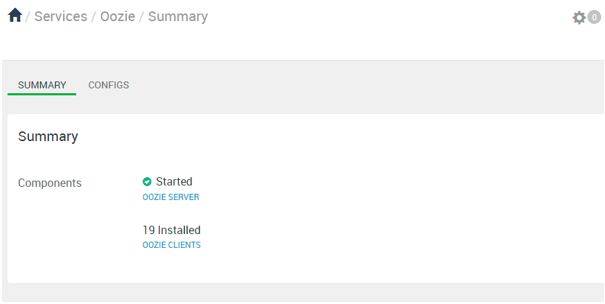
Explanation
As per the above screenshot, we have seen the oozie service summary.
4. Hive
With the help of the hive service, we are able to run the SQL statement on top of HDFS data.
Screenshot:
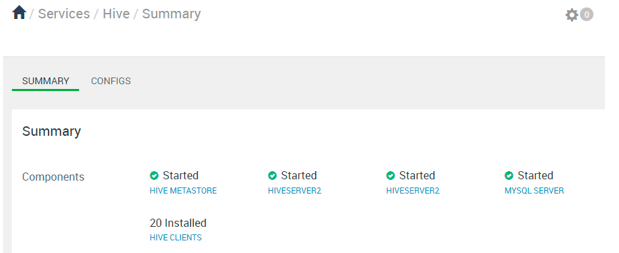
Explanation
As per the above screenshot, we have seen the hive service summary with different components of the hive. As per the above screenshot, we are having the hiveserver 2 in high availability. If any of the hiveserver2 will not able to process the client request or may down then the other hiveserver2 will act as a leader and serve the client request.
5. HBase
The HBase service is used to store the data in the columnar method. The data will be store in distributed mode. In HBase, the actual data store information is available in the HBase region server. HFile will store the actual HBase data on top of the HDFS store level.
Screenshot:
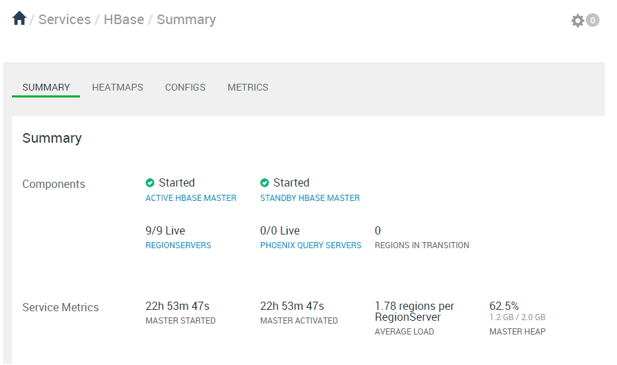
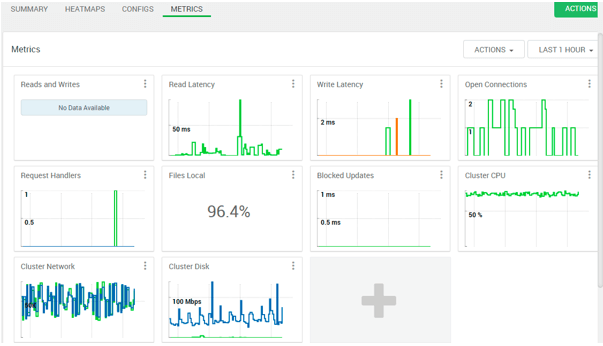
Explanation
As per the above screenshot, we have seen the hive service summary, matrix, and different components of HBase.
6. Ranger
In the Hadoop stack, the ranger is a service that manages all the authorization parts of the Hadoop ecosystem.
Screenshot:
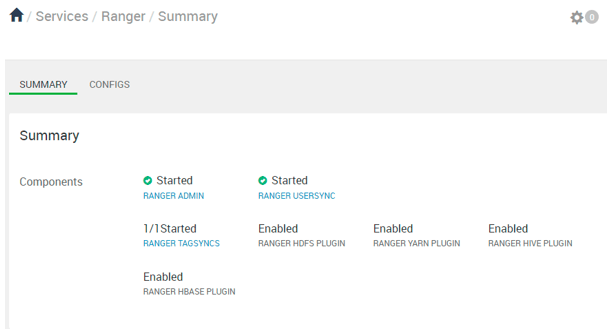
Explanation
As per the above screenshot, we have seen the ranger service summary with different components of the ranger.
7. Spark
The spark is having its own execution engine. It will use the in-memory caching and optimized query. It will help to process the data quickly.
Screenshot:
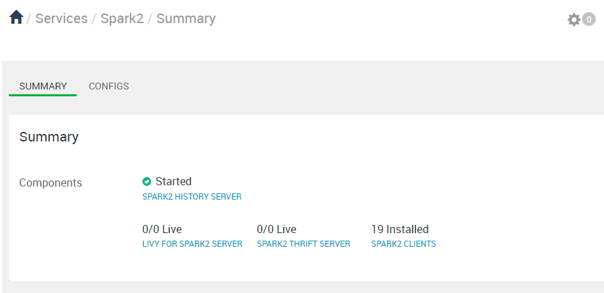
Explanation
As per the above screenshot, we have seen the spark service summary with different components of spark.
8. Zeppelin
The zeppelin is a service; it will work as an interpreter in between the client and the Hadoop ecosystem. We can run the number of different types of queries from the zeppelin like the hive, HBase, spark, etc.
Screenshot:
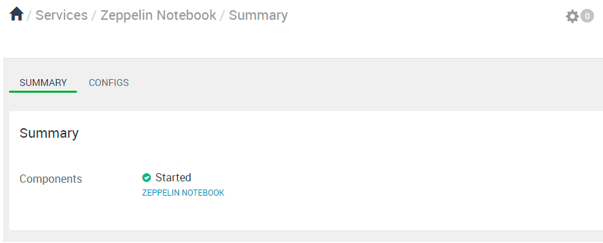
Explanation
As per the above screenshot, we are seen the zeppelin service.
Conclusion
We have seen the uncut concept of “Hadoop Stack” with the proper example, explanation, and screenshot. The Hadoop Stack is a combination of multiple technologies. It is not mandatory to deploy the entire Hadoop stack in the same cluster. As per the requirement, we can choose the service from the stack and deployed it. We can use the different technologies to keep the Hadoop stack or environment secure like Kerberos, SSL, TLS, encryption, etc.
Recommended Articles
This is a guide to Hadoop Stack. Here we discuss the definition, syntax, list of services, and How Hadoop Stack Works? respectively. You may also have a look at the following articles to learn more –
