
Introduction to Hadoop Components
Hadoop Components are used to increase the data’s seek rate from the storage, as the data is increasing day by day. Despite storing the information in the warehouse, the seeking is not fast enough, making it unfeasible. To overcome this problem, Hadoop Components such as Hadoop Distributed file system aka HDFS (store data in the form of blocks in the memory), Map Reduce and Yarn, are used to allow the data to be read and process parallelly.
Major Components of Hadoop
The major components are described below:
1. Hadoop Distributed File System (HDFS)
HDFS is the storage layer for Big Data; it is a cluster of many machines; the stored data can be used to process Hadoop. Once the data is pushed to HDFS, we can process it anytime till the time we process the data will be residing in HDFS till we delete the files manually. HDFS stores the data as a block, the minimum size of the block is 128MB in Hadoop 2.x, and for 1.x, it was 64MB. HDFS replicates the blocks for the data available if data is stored in one machine, and if the device fails, data is not lost but to avoid these, data is replicated across different devices. The replication factor by default is 3. We can change HDFS-site.xml or use the command Hadoop fs -strep -w 3 /dir by replicating the blocks on different machines for high availability.
HDFS is a master-slave architecture; it is NameNode as master and Data Node as a slave. NameNode is the machine where all the metadata is stored of all the blocks stored in the DataNode.
2. YARN
YARN was introduced in Hadoop 2.x; before that, Hadoop had a JobTracker for resource management. Job Tracker was the master, and it had a Task Tracker as the slave. Job Tracker was the one who used to take care of scheduling the jobs and allocating resources. Task Tracker was used to take care of the Map and Reduce tasks, and the status was updated periodically to Job Tracker. With is a type of resource manager, it had a scalability limit, and concurrent execution of the studies has also had a limitation. These issues were addressed in YARN, and it took care of resource allocation and scheduling of jobs on a cluster. Executing a Map-Reduce job needs resources in a group; to get the resources allocated for the job, YARN helps. YARN determines which job is done and which machine it is done. It has all the information of available cores and memory in the cluster; it tracks memory consumption. It interacts with the NameNode about the data where it resides to decide on the resource allocation.
3. MapReduce
The Hadoop ecosystem is a cost-effective, scalable, and flexible way of working with such large datasets. Hadoop is a framework that uses a particular programming model, called MapReduce, for breaking up computation tasks into blocks that can be distributed around a cluster of commodity machines using the Hadoop Distributed Filesystem (HDFS).
MapReduce is two different tasks Map and Reduce, Map precedes the Reducer Phase. As the name suggests, the Map phase maps the data into key-value pairs; as we all know, Hadoop utilizes fundamental values for processing. The reducer phase is the phase where we have the actual logic to be implemented. Apart from these two phases, it executes the shuffle and sort phase as well.
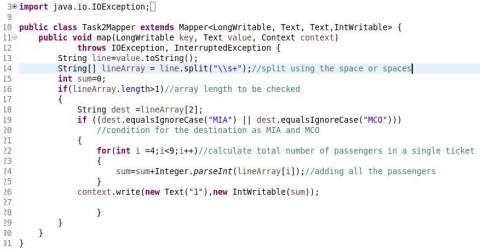
Mapper: Mapper is the class where the input file is converted into keys and values pairs for further processing. While reading the data, it is read in fundamental values only where the key is the bit offset, and the value is the entire record.
E.g. we have a file Diary.txt in that we have two lines written, i.e. two records.
This is a wonderful day we should enjoy here, the offsets for ‘t’ is 0 and for ‘w’ it is 33 (white spaces are also considered as a character) so, the mapper will read the data as key-value pair, as (key, value), (0, this is a wonderful day), (33, we should enjoy)
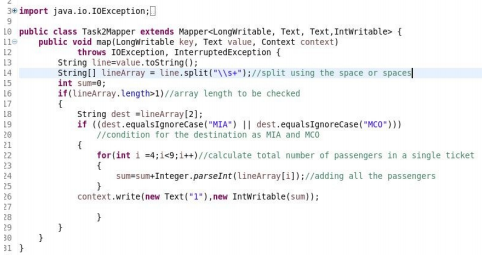
Reducer: Reducer is the class that accepts keys and values from the mappers’ phase’s output. Keys and values generated from the mapper are taken as input in the reducer for further processing. Reducer receives data from multiple mappers. Reducer aggregates those intermediate data to a reduced number of keys and values, which is the final output; we will see this in the example.
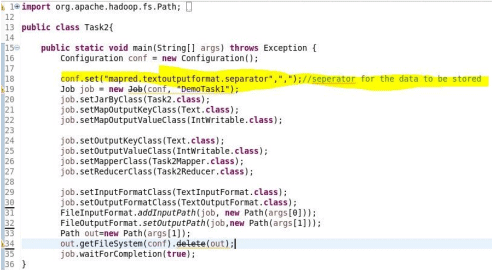
Driver: Apart from the mapper and reducer class, we need one more Driver class. This code is necessary for MapReduce as it is the bridge between the framework and the logic implemented. It specifies the configuration, input data path, output storage path, and most importantly, which mapper and reducer classes need to be also implemented; many other arrangements be set in this class. e.g. in the driver class, we can specify the separator for the output file as shown in the driver class of the example below.
Example
Consider we have a dataset of travel agencies, now we need to calculate from the data that how many people choose to travel to a particular destination. To achieve this, we will need to take the goal as key, and for the count, we will take the value as 1. So, in the mapper phase, we will be mapping the destination to value 1. Now in the shuffle and sort phase after the mapper, it will map all the values to a particular key. E.g. if we have a destination as MAA, we have mapped 1 also we have 2 occurrences after the shuffling and sorting, we will get MAA,(1,1) where (1,1) is the value. Now, in the reducer phase, we already have a logic implemented in the reducer phase to add the values to get the total count of the ticket booked for the destination. This is the flow of MapReduce.
Below is the screenshot of the implemented program for the above example.
1. Driver Class
2. Mapper Class
3. Reducer Class
Executing the Hadoop
For Execution of Hadoop, we first need to build the jar, and then we can achieve using the below command Hadoop jar eample.jar /input.txt /output.txt
Conclusion
Here we have discussed the core components of the Hadoop like HDFS, Map Reduce, and YARN. It is a distributed cluster computing framework that helps store and process the data and do the required analysis of the captured data. Hadoop is flexible, reliable in terms of data as data is replicated and scalable, i.e. we can add more machines to the cluster for storing and processing data.
Recommended Articles
This has been a guide to Hadoop Components. Here we discussed the core components of Hadoop with examples. You can also go through our other suggested articles to learn more –
