Updated March 20, 2023
Introductions to Data Science Algorithms
A high-level description of the essential algorithms used in Data Science. As you already know, data science is a field of study where decisions are made based on the insights we get from the data instead of classic rule-based deterministic approaches. Typically we can divide a machine learning task into three parts.
- Obtaining the data and mapping the business problem,
- Applying machine learning techniques and observing the performance metric
- Testing and deploying the model
In this whole life cycle, we use various data science algorithms to solve the task at hand. This article will divide the most commonly used algorithms based on their learning types and will have a high-level discussion on those.
Types of Data Science Algorithms
We can simply divide machine learning or data science algorithms into the following types based on the learning methodologies.
- Supervised Algorithms
- Unsupervised Algorithms
1. Supervised Algorithms
As the name suggests, supervised algorithms are a class of machine learning algorithms where the model is trained with the labelled data. For example, based on the historical data, you want to predict a customer will default on a loan or not. After preprocess and feature engineering of the labelled data, supervised algorithms are trained over the structured data and tested over a new data point or, in this case, to predict a loan defaulter. Let’s dive into the most popular supervised machine learning algorithms.
K Nearest Neighbors
K nearest neighbours (KNN) is one of the simplest yet powerful machines learning algorithms. It is a supervised algorithm where the classification is done based on k nearest data points. The idea behind KNN is that similar points are clustered together; by measuring the nearest data points’ properties, we can classify a test data point. For example, we solve a standard classification problem where we want to predict a data point belongs to class A or class B. Let k=3; now we will test 3 nearest datapoint of the test data point; if two of them belongs to class A, we will declare the test data point as class A otherwise class B. The right value of K is found through cross-validation. It has a linear time complexity hence can not be used for low latency applications.
Linear Regression
Linear regression is a supervised data science algorithm.
Output:
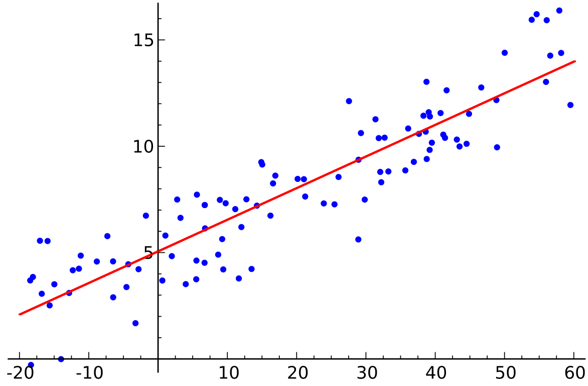
Variable is continuous. The idea is to find a hyperplane where the maximum number of points lies in the hyperplane. For example, predicting rain is a standard regression problem where linear regression can be used. Linear regression assumes that the relation between the independent and dependent variables is linear, and there is very little or no multicollinearity.
Logistic Regression
Though the name says regression, logistic regression is a supervised classification algorithm.
Output:
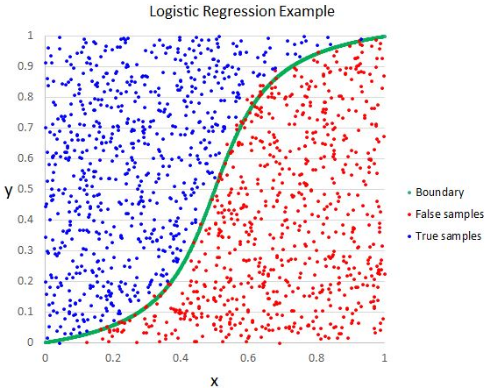
The geometric intuition is that we can separate different Class labels using a linear decision boundary. The output variable of logistic regression is categorical. Please note that we can not use mean squared error as a cost function for logistic regression as it is nonconvex for logistic regression.
Support Vector Machine
In logistic regression, our main motto was to find a separating linear surface.
Output:
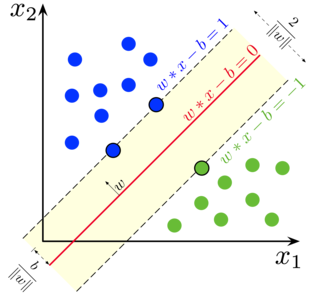
We can consider the Support vector machine as an extension of this idea to find a hyperplane that maximizes the margin. But what is a margin?. For a vector W (the decision surface we need to come up with), we draw two parallel lines on both sides. The distance between these two lines is called the margin. SVM assumes the data is linearly separable. Though we can use SVM for nonlinear data also using the Kernel trick.
Decision Tree
Decision Tree is a nested If-Else based classifier that uses a tree-like graph structure to make the decision. Decision Trees are trendy and one of the most used supervised machine learning algorithms in the whole area of data science. It provides better stability and accuracy in most cases than other supervised algorithms and robust to outliers. The decision tree’s output variable is usually categorical, but it also can be used to solve regression problems.
Ensembles
Ensembles are a popular category of data science algorithms where multiple models are used to improve performance. If you are familiar with Kaggle (a platform by google for practising and competing in data science challenges), you will find the most winner solutions using some ensembles.
We can roughly divide ensembles into the following categories.
- Bagging
- Boosting
- Stacking
- Cascading
Random Forest, Gradient Boosting Decision Trees are examples of some popular ensemble algorithms.
2. Unsupervised Algorithms
Unsupervised algorithms are used for the tasks where the data is unlabelled. The most popular use case of unsupervised algorithms is clustering. Clustering is the task of grouping together similar data points without manual intervention. Let’s discuss some of the popular unsupervised machine learning algorithms here
K Means
K Means is a randomized unsupervised algorithm used for clustering.K Means follows the below steps
1.Initialize K points randomly(c1,c2..ck)
2. For each point (Xi) in the data set
Select nearest Ci {i=1,2,3..k}
Add Xi to Ci
3. Recompute the centroid using proper metrics (i.e. intracluster distance)
4, Repeat step (2)(3) until converges
K Means++
The initialization step in K means is purely random, and based on the initialization, the clustering changes drastically. K means++ solves this problem by initializing k in a probabilistic way instead of pure randomization. K means++ is more stable than classic K means.
K Medoids
K medoids is also a clustering algorithm based on K means. The main difference between the two is the centroids of K means does not necessarily exist in the data set, which is not the case for K medoids. K medoids offer better interpretability of clusters. K means minimizes the total squared error, while K medoids minimize the dissimilarity between points.
Conclusion
In this article, we discussed the most popular machine learning algorithms used in data science. After all these, a question may come to your mind that ‘Which algorithm is the best?’ Clearly, there is no winner here. It solely depends on the task at hand and business requirements. As a best practice, it always starts with the simplest algorithm and increases the complexity gradually.
Recommended Articles
This has been a guide to Data Science Algorithms. Here we have discussed an overview of data science algorithms with two data science algorithms in detail. You can also go through our given articles to learn more –
