Updated March 18, 2023

Introduction to Decision Tree Algorithm
The Decision Tree Algorithm is one of the popular supervised type machine learning algorithms that is used for classifications. This algorithm generates the outcome as the optimized result based upon the tree structure with the conditions or rules. The decision tree algorithm associated with three major components as Decision Nodes, Design Links, and Decision Leaves. It operates with the Splitting, pruning, and tree selection process. It supports both numerical and categorical data to construct the decision tree. Decision tree algorithms are efficient for large data set with less time complexity. This Algorithm is mostly used in customer segmentation and marketing strategy implementation in the business.
What is Decision Tree Algorithm?
Decision Tree Algorithm is a supervised Machine Learning Algorithm where data is continuously divided at each row based on certain rules until the final outcome is generated. Let’s take an example, suppose you open a shopping mall and of course, you would want it to grow in business with time. So for that matter, you would require returning customers plus new customers in your mall. For this, you would prepare different business and marketing strategies such as sending emails to potential customers, create offers and deals, targeting new customers, etc. But how do we know who are the potential customers? In other words, how do we classify the category of the customers? Like some customers will visit once in a week and others would like to visit once or twice in a month, or some will visit in a quarter. So decision trees are one such classification algorithm that will classify the results into groups until no more similarity is left.
In this way, the decision tree goes down in a tree-structured format.
The main components of a decision tree are:
- Decision Nodes, which is where the data is split or, say, it is a place for the attribute.
- Decision Link, which represents a rule.
- Decision Leaves, which are the final outcomes.

Working of a Decision Tree Algorithm
There are many steps that are involved in the working of a decision tree:
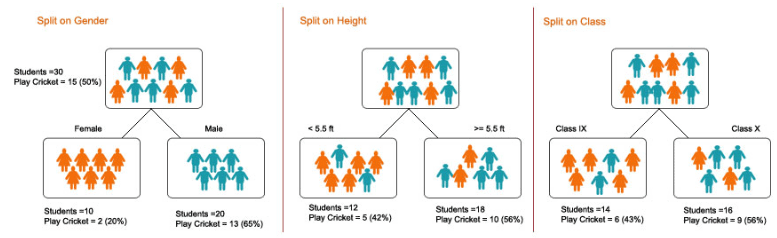
1. Splitting – It is the process of the partitioning of data into subsets. Splitting can be done on various factors as shown below i.e. on a gender basis, height basis, or based on class.
2. Pruning – It is the process of shortening the branches of the decision tree, hence limiting the tree depth.
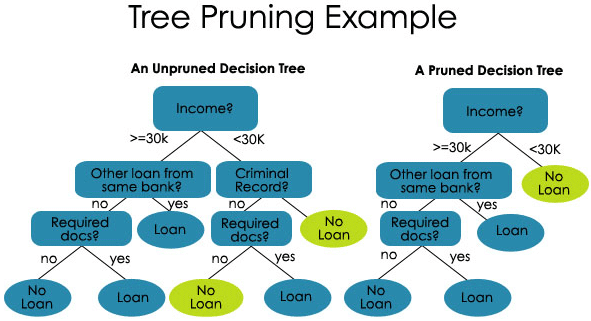
Pruning is also of two types:
- Pre-Pruning – Here, we stop growing the tree when we do not find any statistically significant association between the attributes and class at any particular node.
- Post-Pruning – In order to post prune, we must validate the performance of the test set model and then cut the branches that are a result of overfitting noise from the training set.
3. Tree Selection – The third step is the process of finding the smallest tree that fits the data.
Example and Illustration of Constructing a Decision Tree
Let’s say you want to play cricket on some particular day (For e.g., Saturday). What are the factors that are involved which will decide if the play is going to happen or not?
Clearly, the major factor is the climate; no other factor has that much probability as much climate is having for the play interruption.
We have collected the data from the last 10 days, which is presented below:
| Day | Weather | Temperature | Humidity | Wind | Play? |
| 1 | Cloudy | Hot | High | Weak | Yes |
| 2 | Sunny | Hot | High | Weak | No |
| 3 | Sunny | Mild | Normal | Strong | Yes |
| 4 | Rainy | Mild | High | Strong | No |
| 5 | Cloudy | Mild | High | Strong | Yes |
| 6 | Rainy | Cool | Normal | Strong | No |
| 7 | Rainy | Mild | High | Weak | Yes |
| 8 | Sunny | Hot | High | Strong | No |
| 9 | Cloudy | Hot | Normal | Weak | Yes |
| 10 | Rainy | Mild | High | Strong | No |
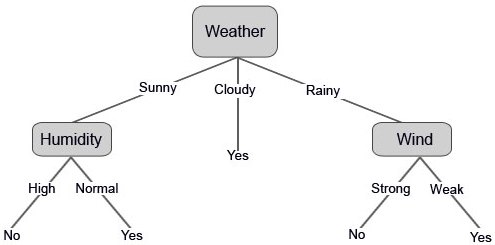
Let us now construct our decision tree based on the data that we have got. So we have divided the decision tree into two levels, the first one is based on the attribute “Weather”, and the second row is based on “Humidity” and “Wind”.
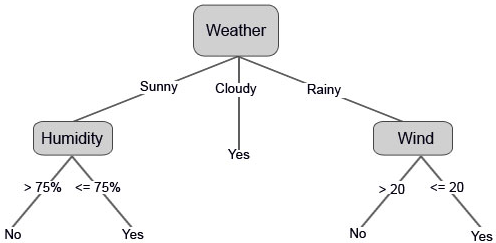
The below images illustrate a learned decision tree.
We can also set some threshold values if the features are continuous.
What is Entropy in Decision Tree Algorithm?
In simple words, entropy is the measure of how disordered your data is. While you might have heard this term in your Mathematics or Physics classes, it’s the same here. The reason Entropy is used in the decision tree is because the ultimate goal in the decision tree is to group similar data groups into similar classes, i.e. to tidy the data.
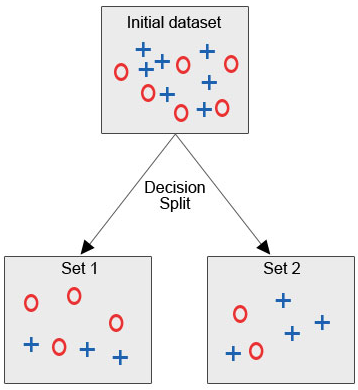
Let us see the below image, where we have the initial dataset, and we are required to apply a decision tree algorithm in order to group together the similar data points in one category.
After the decision split, as we can clearly see, most of the red circles fall under one class while most of the blue crosses fall under another class. Hence a decision was to classify the attributes that could be based on various factors.
Now, let us try to do some math over here:
Let us say that we have got “N” sets of the item, and these items fall into two categories, and now in order to group the data based on labels, we introduce the ratio:
![]()
The entropy of our set is given by the following equation:
![]()
Let us check out the graph for the given equation:
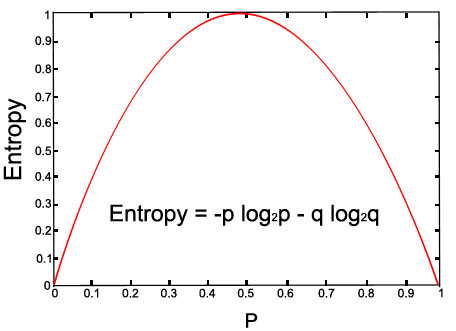
Above Image (with p=0.5 and q=0.5)
Advantages and Disadvantages
Given below are the advantages and disadvantages mentioned:
Advantages:
- A decision tree is simple to understand, and once it is understood, we can construct it.
- We can implement a decision tree on numerical as well as categorical data.
- Decision Tree is proven to be a robust model with promising outcomes.
- They are also time-efficient with large data.
- It requires less effort for the training of the data.
Disadvantages:
- Instability: Only if the information is precise and accurate, the decision tree will deliver promising results. Even if there is a slight change in the input data, it can cause large changes in the tree.
- Complexity: If the dataset is huge with many columns and rows, it is a very complex task to design a decision tree with many branches.
- Costs: Sometimes, cost also remains a main factor because when one is required to construct a complex decision tree, it requires advanced knowledge in quantitative and statistical analysis.
Conclusion
In this article, we saw about the decision tree algorithm and how to construct one. We also saw the big role that is being played by Entropy in the decision tree algorithm, and finally, we saw the advantages and disadvantages of the decision tree.
Recommended Articles
This has been a guide to Decision Tree Algorithm. Here we discussed the role played by entropy, working, advantages, and disadvantages. You can also go through our other suggested articles to learn more –
