
Introduction to Data Mining Methods
Data mining is looking for patterns in huge data stores. This process brings useful ways, and thus we can make conclusions about the data. This also generates new information about the data which we possess already. The methods include tracking patterns, classification, association, outlier detection, clustering, regression, and prediction. It is easy to recognize patterns, as there can be a sudden change in the data given. We have collected and categorized the data based on different sections to be analyzed with the categories. Clustering groups the data based on the similarities of the data.
What is Data Mining?
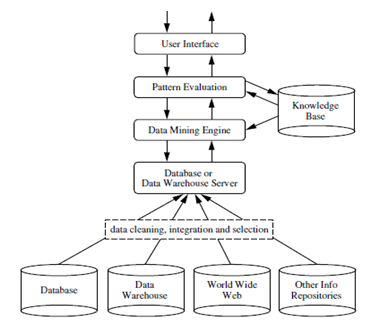
It is a process of extracting useful information or knowledge from a tremendous amount of data (or big data). The gap between data and intake has been reduced by using various data mining tools. It can also be referred to as Knowledge discovery from data or KDD.
Sources:- www.ques10.com
It can be performed on various databases and information repositories like Relational databases, Data Warehouses, Transactional databases, data streams, and many more.
Different Data Mining Methods
There are many methods used for Data Mining, but the crucial step is to select the appropriate form from them according to the business or the problem statement. These methods help in predicting the future and then making decisions accordingly. These also help in analyzing market trends and increasing company revenue.
Some Methods are:
- Association
- Classification
- Clustering Analysis
- Prediction
- Sequential Patterns or Pattern Tracking
- Decision Trees
- Outlier Analysis or Anomaly Analysis
- Neural Network
Let us understand every data mining method one by one.
1. Association
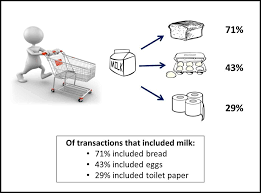
It is used to find a correlation between two or more items by identifying the hidden pattern in the data set and hence also called relation analysis. This method is used in market basket analysis to predict the behavior of the customer.
Suppose, the marketing manager of a supermarket wants to determine which products are frequently purchased together.
As an example,
Buys (x,”beer”) -> buys(x, “chips”) [support = 1%, confidence = 50%]
- Here x represents a customer buying beer and chips together.
- Confidence shows certainty that if a customer buys a beer, there is a 50% chance that he/she will also accept the chips.
- Support means that 1% of all the transactions under analysis showed that beer and chips were bought together.
Many similar examples like bread and butter or computer and software can be considered.
There are two types of Association Rules:
- Single dimensional association rule: These rules contain a single attribute that is repeated.
- Multidimensional association rule: These rules contain multiple attributes that are repeated.
Source Link: https://www.google.com/search
2. Classification
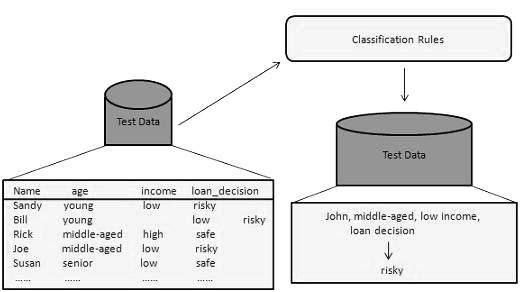
This data mining method is used to distinguish the items in the data sets into classes or groups. It helps to predict the behaviour of entities within the group accurately. It is a two-step process:
- Learning step (training phase): In this, a classification algorithm builds the classifier by analyzing a training set.
- Classification step: Test data are used to estimate the accuracy or precision of the classification rules.
For example, a banking company uses to identify loan applicants at low, medium or high credit risks. Similarly, a medical researcher analyzes cancer data to predict which medicine to prescribe to the patient.
Source Link:– www.tutorialspoint.com
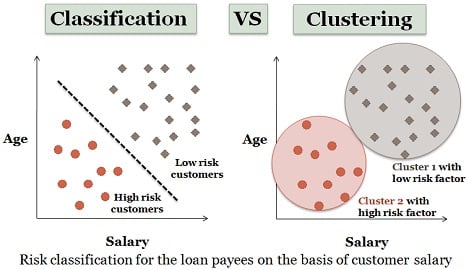
3. Clustering Analysis
Clustering is almost similar to classification, but in this cluster are made depending on the similarities of data items. Different groups have dissimilar or unrelated objects. It is also called data segmentation as it partitions huge data sets into groups according to the similarities.
Various clustering methods are used:
- Hierarchical Agglomerative methods
- Grid-Based Methods
- Partitioning Methods
- Model-Based Methods
- Density-Based Methods
A similar example of loan applicants can be considered here also. Some differences are depicted in the figure below.
Source Link: https://www.google.com/search
4. Prediction
This method is used to predict the future based on the past and present trends or data set. Prediction is mostly used to combine other mining methods such as classification, pattern matching, trend analysis, and relation.
For example, if the sales manager would like to predict the amount of revenue that each item would generate based on past sales data. It models a continuous-valued function that indicates missing numeric data values.

Source Link:– data-mining.Philippe-Fournier
Regression Analysis is the best choice to perform prediction. It can be used to set a relationship between independent variables and dependent variables.
5. Sequential patterns or Pattern tracking
This method is used to identify patterns that frequently occur over a certain period of time.
For example, a clothing company’s sales manager sees that sales of jackets seem to increase just before the winter season, or sales in bakery increase during Christmas or New Year’s eve.
Let’s look at an example with a graph.
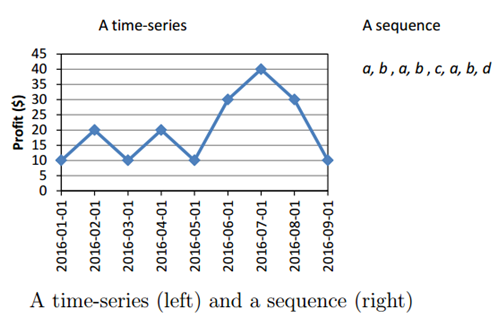
Source Link:- data-mining.Philippe-Fournier-Viger
6. Decision Trees
A decision tree is a tree structure (as its name suggests), where
- Each internal node represents a test on the attribute.
- Branch denotes the result of the test.
- Terminal nodes hold the class label.
- The topmost node is the root node which has a simple question that has two or more answers. Accordingly, the tree grows, and a flow chart like structure is generated.
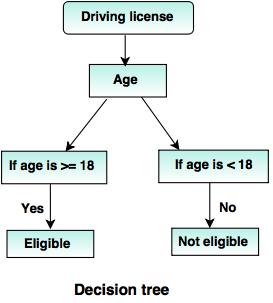
Source bLink:– www.tutorialride.com
In this decision, tree government classifies citizens below age 18 or above age 18. This would help them to decide whether a license must be issued to a particular city or not.
7. Outlier Analysis or Anomaly Analysis:
This method identifies the data items that do not comply with the expected pattern or expected behaviour. These unexpected data items are considered as outliers or noise. They are helpful in many domains like credit card fraud detection, intrusion detection, fault detection etc. This is also called Outlier Mining.
For example, let’s assume the graph below is plotted using some data sets in our database.
So the best fit line is drawn. The points lying nearby the line show expected behaviour while the end far from the line is an Outlier.
This would help to detect the anomalies and take possible actions accordingly.
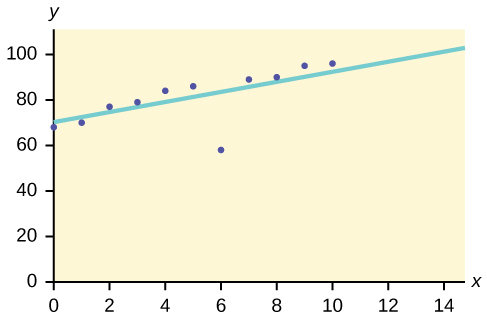
Source Link: https://www.google.com/search
8. Neural Network
This method or model is based on biological neural networks. It is a collection of neurons like processing units with weighted connections between them. They are used to model the relationship between inputs and outputs. It is used for classification, regression analysis, data processing etc. This technique works on three pillars-
- Model
- Learning Algorithm (supervised or unsupervised)
- Activation function
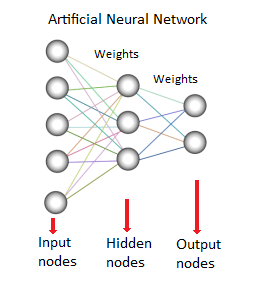
Source Link:- www.saedsayad.com
Recommended Articles
This has been a guide to Data Mining Methods Here, we have discussed What Data Mining and different mining methods are with the example. You may also look at the following articles to learn more –

