
Difference Between Data Science and Machine Learning
Data science is an evolutionary extension of statistics capable of dealing with massive amounts with the help of computer science technologies. Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed. Data science covers a wide range of data technologies, including SQL, Python, R, Hadoop, Spark, etc. Machine learning is seen as a process, it can be defined as the process by which a computer can work more accurately as it collects and learns from the data it is given.
Science vs Machine Learning (Infographics)
Below is the top 5 comparison between Data Science and Machine Learning:
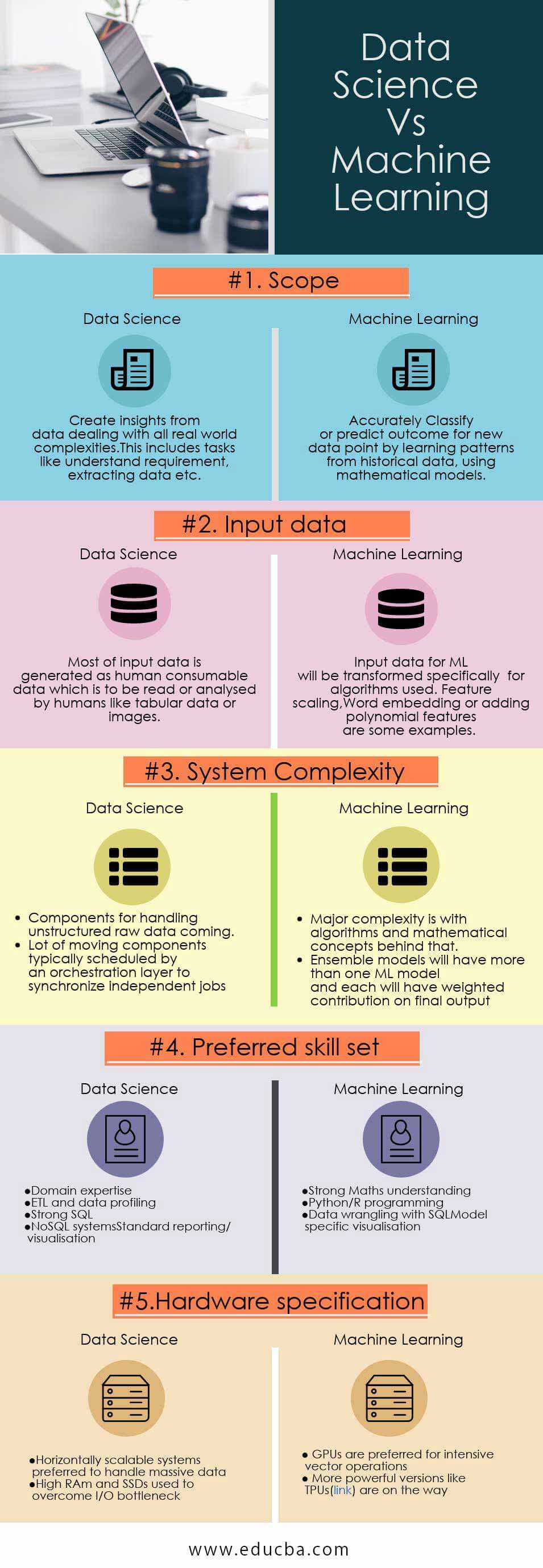
Key Difference Between Data Science and Machine Learning
Below is the difference between Data Science and Machine Learning are as follows:
- Components – As mentioned earlier, Data Science systems cover the entire data lifecycle and typically have components to cover the following :
- Collection and profiling of data – ETL (Extract Transform Load) pipelines and profiling jobs
- Distributed computing – Horizontally scalable data distribution and processing
- Automating intelligence – Automated ML models for online responses(prediction, recommendations) and fraud detection.
- Data Visualization – Visually explore data to get a better intuition of data. The integral part of ML modeling.
- Dashboards and BI – Predefined dashboards with slice-and-dice capability for higher-level stakeholders.
- Data engineering – Making sure hot and cold data is always accessible. Covers data backup, security, and disaster recovery.
- Deployment in production mode – Migrate the system into production with industry-standard practices.
- Automated decisions – This includes running business logic on top of data, or a complex mathematical model trained using any ML algorithm.
Machine Learning modeling starts with the data that exists, and typical components are as follows :
- Understand the problem – Make sure an efficient way to solve the problem is ML. Note that not all problems are solvable using ML.
- Explore Data – To get an intuition of features to be used in the ML model. This might need more than one iteration. Data visualization plays a critical role here.
- Prepare data – This is an important stage with a high impact on the accuracy of the ML model. Does it deal with data issues like what to do with missing data for a feature? Replace with a dummy value like zero, or the mean of other values or drop the feature from the model. Scaling features, which make sure the values of all features are in the same range, is critical for many ML models. A lot of other techniques, like polynomial feature generation, is also used here to derive new features.
- Select a model and train – The model is selected based on a type of problem ( Prediction or classification, etc. ) and type of feature set ( some algorithms work with a small number of instances with a large number of features and some others in other cases).
- Performance Measure – In Data Science, performance measures are not standardized, it will change case by case. Typically it will be an indication of Data Timeliness, Data Quality, Querying Capability, Concurrency limits in data access, Interactive visualization capability, etc.
In ML models, performance measures are crystal clear. Each algorithm will have a measure to indicate how well or bad the model describes the training data given. For example, RME(Root Mean Square Error) is used in Linear Regression as an indication of an error in the model.
Development methodology – Data Science projects are aligned more like engineering projects with clearly defined milestones. But ML projects are more research-like, which starts with a hypothesis and trying to get it proved with the data available.
Visualization – Visualisation in general Data Science represents data directly using any popular graphs like bars, pie, etc. But in ML, visualizations are also used to represent a mathematical model of training data. For example, visualizing the confusion matrix of a multiclass classification helps to quickly identify false positives and negatives.
Languages – SQL and SQL-like syntax languages (HiveQL, Spark SQL, etc.) are the most used language in the Data Science world. Popular data processing scriptings languages like Perl, awk, and sed are also in use. Framework-specific well-supported languages are another widely (Java for Hadoop, Scala for Spark, etc.) used category.
Python and R are the most used language in the Machine Learning world. Nowadays, Python is gaining more momentum as new deep learning researchers are mostly converted to python.SQL also plays an important role in the data exploration phase of ML.
Data Science and Machine Learning Comparison Table
Below is the comparison table between Data Science and Machine Learning.
Basis of Comparison Data Science Machine Learning
Scope Create insights from data dealing with all real-world complexities. This includes tasks like understanding the requirement, extracting data, etc. Accurately Classify or predict the outcome for new data points by learning patterns from historical data, using mathematical models.
Input Data Most of the input data is generated as human consumable data, which is to be read or analyzed by humans like tabular data or images. Input data for ML will be transformed specifically for the algorithms used. Feature scaling, Word embedding, or adding polynomial features are some examples
System Complexity
● Components for handling unstructured raw data coming.
● Lot of moving components are typically scheduled by an orchestration layer to synchronize independent jobs.
● Major complexity is with algorithms and mathematical concepts behind that.
● Ensemble models will have more than one ML model, and each will have a weighted contribution on the final output.
Preferred skill set
● Domain expertise
● ETL and data profiling
● Strong SQL
● NoSQL systems
● Standard reporting/ visualization
● Strong Maths understanding
● Python/R programming
● Data wrangling with SQL
● Model-specific visualization
Hardware Specification
● Horizontally scalable systems preferred to handle massive data
● High RAm and SSDs used to overcome I/O bottleneck
● GPUs are preferred for intensive vector operations
● More powerful versions like TPUs(link) are on the way
Conclusion
In both Data Science and Machine Learning, we are trying to extract information and insights from data. Machine learning tries to make algorithms learn on their own. Currently, advanced ML models are applied to Data Science to automatically detect and profile data. Google’s Cloud Dataprep is the best example of this.
Recommended Articles
This has been a guide to Data Science vs. Machine Learning. Here we have discussed Data Science and Machine Learning Meaning, head-to-head comparison, and key differences, along with infographics, and comparison tables. You may also look at the following articles to learn more –

