Updated March 23, 2023
Introduction to Data Science Lifecycle
Data Science Lifecycle revolves around using machine learning and other analytical methods to produce insights and predictions from data to achieve a business objective. The entire process involves several steps like data cleaning, preparation, modelling, model evaluation, etc. It is a long process and may take several months to complete. So, it is essential to have a general structure to follow for every problem at hand. The globally acknowledged structure in solving any analytical problem is the Cross-Industry Standard Process for Data Mining or CRISP-DM framework.
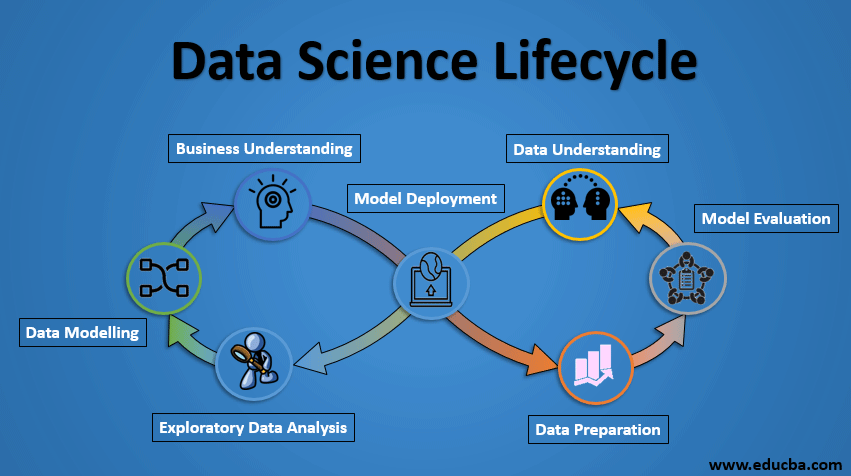
The lifecycle of Data Science
Below is the Lifecycle of the Data Science project.
1. Business Understanding
The entire cycle revolves around the business goal. What will you solve if you do not have a precise problem? It is essential to understand the business objective clearly because that will be your final goal of the analysis. Only we can set the specific goal of analysis in sync with the business objective after proper understanding. You need to know if the client wants to reduce credit loss, or if they want to predict the price of a commodity, etc.
2. Data Understanding
After business understanding, the next step is data understanding. This involves the collection of all the available data. It would help if you worked closely with the business team to know what data is present and what data could be used for this business problem, and other information. This step involves describing the data, their structure, their relevance, their data type. Explore the data using graphical plots. Basically, extracting any information that you can get about the data by just exploring the data.
3. Data Preparation
Next comes the data preparation stage. This includes selecting the relevant data, integrating the data by merging the data sets, cleaning them, treating the missing values by either removing them or imputing them, treating erroneous data by removing them, and checking outliers using box plots and handle them. Constructing new data, derive new features from existing ones. Format the data into the desired structure, remove unwanted columns and features. Data preparation is the most time consuming yet arguably the most important step in the entire life cycle. Your model will be as good as your data.
4. Exploratory Data Analysis
This step involves getting some idea about the solution and factors affecting it before building the actual model. The distribution of data within different feature variables is explored graphically using bar-graphs; relations between different features are captured through graphical representations like scatter plots and heat maps. Many other data visualization techniques are extensively used to explore every feature individually and combine them with other features.
5. Data Modeling
Data modelling is the heart of data analysis. A model takes the prepared data as input and provides the desired output. This step includes choosing the appropriate type of model, whether the problem is a classification problem, or a regression problem or a clustering problem. After choosing the model family, amongst the various algorithm amongst that family, we need to choose the algorithms to implement and implement them carefully. We need to tune the hyperparameters of each model to achieve the desired performance. We also need to make sure there is a correct balance between performance and generalizability. We do not want the model to learn the data and perform poorly on new data.
6. Model Evaluation
Here the model is evaluated for checking if it is ready to be deployed. The model is tested on unseen data, evaluated on a carefully thought out set of evaluation metrics. We also need to make sure that the model conforms to reality. If we do not obtain a satisfactory result in the evaluation, we must re-iterate the entire modelling process until the desired level of metrics is achieved. Any data science solution, a machine learning model, just like a human, should evolve, should be able to improve itself with new data, adapt to a new evaluation metric. We can build multiple models for a certain phenomenon, but a lot of them may be imperfect. Model evaluation helps us choose and build a perfect model.
7. Model Deployment
The model, after a rigorous evaluation, is finally deployed in the desired format and channel. This is the final step in the data science life cycle. Each step in the data science life cycle explained above should be worked upon carefully. If any step is executed improperly, it will affect the next step, and the entire effort goes to waste. For example, if data is not collected properly, you’ll lose information, and you will not be building a perfect model. If data is not cleaned properly, the model will not work. If the model is not evaluated properly, it will fail in the real world. From business understanding to model deployment, each step should be given proper attention, time and effort.
Recommended Articles
This is a guide to Data Science Lifecycle. Here we discuss an overview of the Data Science Lifecycle and the steps that make up a data science lifecycle. You can also go through our related articles to learn more –
