
Data engineering is a term where everyone is aware of it and is quite popular in the field of Big Data. Data engineering refers to Data Infrastructure or Data Architecture. Raw data generated from different sources such as social media, mobile phones, www(internet) needs to be transformed, cleansed, profiled and aggregated for Business needs. This raw data is also termed as Dark Data. The practice of designing, architecting and implementing the data process system helps convert the data into a piece of appropriate information or a set of data; such information or set of data is termed as Data Engineering.
If you are looking for a job that is related to Data Engineer, you need to prepare for the 2026 Data Engineer interview questions. Though every Data Engineer Interview Questions are different and the scope of a job is also different, we can help you out with the top Data Engineer Interview Questions with answers, which will help you take the leap and succeed in your Data Engineer Interview.
Below is the list of top 2026 Data Engineer Interview Questions and Answers:
Part 1 – Basic Data Engineer Interview Questions
Q1. What is Data Engineering?
Answer:
Data engineering is the process of designing, building, and maintaining systems that collect, store, process, and transform raw data into useful information.
Data engineers handle large volumes of structured, semi-structured, and unstructured data generated from sources like:
- Social media
- Websites
- Mobile applications
- IoT devices
- Business systems
Their primary goal is to create reliable data pipelines and infrastructure that support analytics, reporting, and machine learning.
Q2. Explain the Daily Work of a Data Engineer?
Answer:
A data engineer is responsible for managing and processing data across the organization. Daily tasks usually include:
- Managing data pipelines
- Building ETL/ELT workflows
- Maintaining databases and data warehouses
- Data cleansing and transformation
- Data validation and quality checks
- Writing SQL queries
- Monitoring pipeline performance
- Working with cloud platforms and big data tools
Data engineers also collaborate with:
- Data analysts
- Data scientists
- Business teams
- Software engineers
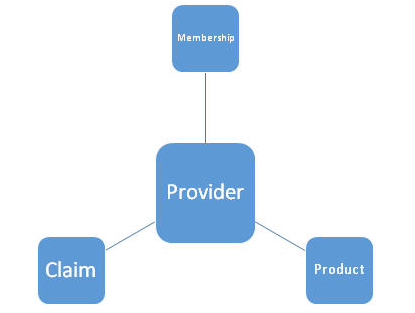
Q3. Do you have experience with Data Modelling?
Answer:
One can say that he/she has worked on a project for a finance/health insurance client where they have used ETL tools like Informatica/Talend/Pentaho etc. to transform and process the data fetched from a MySQL/RDS/SQL Database and sends out these information to vendors that can help to increase their revenues. One can show below the high-level architecture of the data model. It consists of a primary key, entity, attributes, relationship, constraints, etc.
A typical project may involve:
- Extracting data from databases like MySQL, PostgreSQL, or SQL Server
- Transforming data using ETL tools such as Informatica, Talend, or Pentaho
- Creating entities, attributes, relationships, and constraints
- Designing schemas for reporting and analytics
Data models help improve:
- Query performance
- Data consistency
- Scalability
- Business reporting
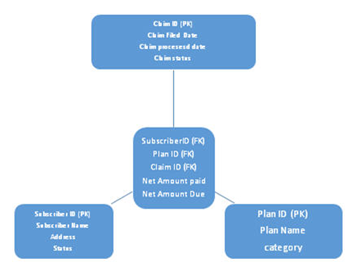
Q4. What are the different types of design schemas in Data Modelling? Explain with an example?
Answer:
There are two types of schemas in data modeling:
1. Star Schema
This schema is divided into two one is a fact table, and the other is a dimension table where all the dimension tables are connected to a fact table. The foreign key in fact table refers to the primary keys present in dimension tables. See below architecture of star schema:
Example:
Sales fact table connected with:
- Customer dimension
- Product dimension
- Time dimension
- Location dimension
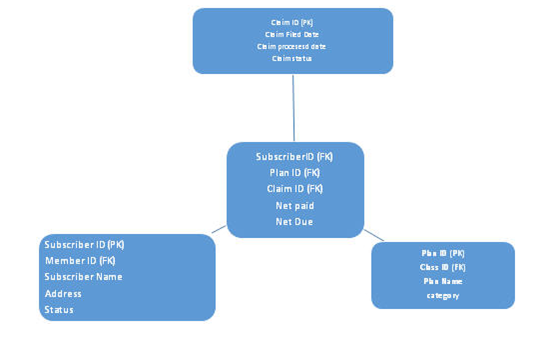
2. Snowflake Schema
In this schema, the normalization level is increased; here, the fact table will remain the same as of star schema; here, dimension tables are normalized. Many layers of dimension tables look like a snowflake, thus the name snowflake schema. See below architecture:-
Q5. Which ETL tool you are using, and how this is best compare to others?
Answer:
One can say that he/she has used Informatica as the ETL tool because of many points; first and foremost, as per Gartner Magic Quadrant for Data Integration Tools, Informatica is positioned as a leader for the 10TH consecutive year. It is easy to use and learn and has features to connect with various source data and data types, re-usable components, and features that make it the most favorite for ETL developers. It also has its own scheduler, which is another advantage, where other ETL tools have to use an external scheduler to schedule the jobs.
Part 2 – Advanced Data Engineer Interview Questions
Q6. Which technologies/Programming language one should have/Learn to be a Data Engineer?
Answer:
Mathematics (linear algebra and probability)
Statistics (summary statistics)
Machine learning techniques
R and SAS languages
SQL databases, HiveQL
Python (mostly used)
Apart from these, one should have problem-solving, analytical and architectural knowledge of the database.
Q7. What are some common problems faced by data engineers?
Answer:
Some common challenges include:
- Real-time integration/ Continuous Integration
- Storing a huge amount of data is one issue; the information from that data is another issue.
- Which tools can be used, which will give the best performance, storage, efficiency, and results.
- Does the storage scale? Suppose how to know that for processing the entire set of data how long it will take?
- Considering the processors and RAM configuration
- How to deal with failures, is fault tolerance there or not?
Q8. How Is Data architect different from Data Engineer?
Answer:
Data Architect is the person for managing the data, especially when one is dealing with different numbers of a variety of data sources. One should have in-depth knowledge of how a database works, how data relates to business problems, and how the changes will disturb the organization’s data use. The data architect will then manipulate/transform the data architecture according to them.
A data architect’s main responsibility is working on Data warehousing, development of data architecture or enterprise data hub/warehouse.
A data engineer helps with installing data warehouse solutions, data modelling, development, and database architecture testing.
Q9. Describe a time when you found a new use case for an existing database that positively impacted the business?
Answer:
While in the era of Big Data, having SQL will lack the below features:
a. RDBMS are schema-oriented DB, so it is better for structured data, not for semi-structured or unstructured data.
b. Not able to process unpredictable and unstructured data.
c. It’s not horizontally scalable, i.e. parallel execution and storing not possible in SQL.
d. It suffers from performance issue once the number of users increases.
e. It is mainly used for Online transactional processing.
To overcome these drawbacks, we can use NoSQL DB, i.e. Not only SQL.
So, in the project, one can use different types of NoSQL DB like Cassandra, MongoDB, Graph DB, HBase, etc.
Q10. Do you have experience working in a cloud computing environment? What benefits do you see working in one?
Answer:
One can say yes, Cloud Computing Environment is ready to move the environment for production, development, and testing without thinking of integrating many instances/Linux/window servers together. There are various cloud computing services in the market like AWS (Amazon web services), Azure(Microsoft), GCP (Google Cloud Platform). Cloud computing service provides below features like flexibility, i.e. environment will scale up as per requirement, Disaster recovery by taking backups and snapshots, Work from anywhere with VPNs, Secure environment, and environment-friendly as it works on commodity hardware, i.e. general-purpose computers which are low in cost.
Q13. What Is Apache Spark and Why Is It Popular?
Answer:
Apache Spark is a fast, open-source data processing framework for big data analytics, machine learning, and streaming. It is popular for speed, scalability, real-time processing, and easy integration with distributed systems.
It is popular because:
- It processes data faster than Hadoop MapReduce
- Supports real-time analytics
- Handles batch and streaming data
- Supports machine learning and SQL workloads
Spark components include:
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
Q12. What Is a Data Pipeline?
Answer:
A data pipeline is a process that collects, transforms, and moves data from multiple sources to storage or analytics systems, enabling businesses to process, analyze, and use data efficiently for decision-making.
A typical data pipeline includes:
- Data ingestion
- Data transformation
- Data validation
- Storage
- Reporting or analytics
Data pipelines can be:
- Batch processing pipelines
- Real-time streaming pipelines
Popular tools used for pipelines include:
- Apache Spark
- Apache Kafka
- Apache Airflow
- AWS Glue
