Updated April 7, 2023

Introduction to Caffe Deep Learning
Caffe, a popular and open-source deep learning framework was developed by Berkley AI Research. It is highly expressible, modular and fast. It has rich open-source documentation available on Github. It is used widely in academic research projects, in startup’s proof of concepts, Computer Vision, Natural Language Processing, etc.
Caffe Deep Learning Framework
It stands for Convolutional Architecture for Fast Feature Embedding and is written in BSD-licensed C++ library with Python and MATLAB bindings. It is used for training and deploying general-purpose convolution neural networks efficiently on commodity architectures. The architecture of the above framework is broadly divided into the following:
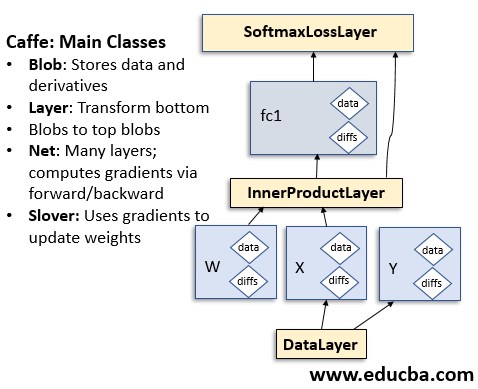
1. Data Storage
It uses N-dimensional array data in a C-contiguous fashion called blobs to store and communicate data. The blob can be thought of as an abstraction layer between the CPU and GPU. The data from the CPU is loaded into the blob which is then passed to the GPU for computation. Under the hood, the blob uses a SyncedMem class to synchronize the values between the CPU and GPU. The blob is then moved to the subsequent layer without taking the lower implementation details into account with a high level of performance being maintained. For efficient memory usage, a lazy demand allocation technique is used to allocate memory on demand for the host and device. For large scale data, LevelDB databases are used. Deep Learning models are stored to the secondary storage as Google Protocol Buffers which provide efficient serialization, human-readable text format, etc.
2. Layers
The blobs are passed as input to it and correspondingly output is generated. It follows a many-to-many relationship. It has the following key responsibilities as part of model operations:
- Setup: It initializes the layer and the underlying connections for the first time during the model initialization.
- Forward Pass: Inputs are passed and correspondingly outputs are generated.
- Backward Pass: Computing gradients with respect to the output, model hyperparameters and the inputs which are then passed to the subsequent layers by using a technique called back-propagation.
It provides different layer setups like Convolution, Pooling, nonlinear activations like rectified, linear units (ReLU) with widely used optimization losses like Log Loss, R-squared, SoftMax, etc. The layers can be extended to a new custom user layer implementation using the compositional construction of networks.
3. Networks and Underlying Run Model
It uses a data structure called a directed acyclic graph for storing operations performed by the underlying layers thus ensuring correctness of the forward and the backward passes. A typical Caffe model network starts with a data layer loading data from a disk and ends with a loss layer based on the application requirements. It can be run on a CPU/GPU and the switch between them is seamless and model-independent.
4. Training a Network
A typical Caffe model is trained by a fast and standard stochastic gradient descent algorithm. Data can be processed into mini-batches which pass in the network sequentially. The important parameters related to the training like learning rate decay schedules, momentum, and checkpoints for stopping and resuming is well implemented with thorough documentation. It also supports fine-tuning, a technique wherein an existing model can be used to support new architecture or data. The previous model weights are updated for the new application and new weights are assigned wherever needed. This technique is widely used in many real-world deep learning applications.
Benefits of Caffe Deep Learning Framework
It provides a complete set of packages for train, test, fine-tunes and deployment of model. It provides many examples of the above tasks. Previously, it was used for vision tasks but now it has been adopted for other deep learning applications like speech recognition, neural networks, robotics by its users. It can be run in cloud-based platforms with seamless platform switching.
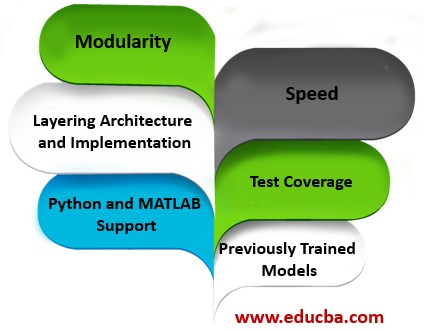
- Modularity: Extension to new data, layers, and loss optimization functions are possible. It has reference examples that have layers and loss functions implemented.
- Speed: It can be used to process 60M images per day using NVIDIA CUDA K40 GPU. It is one of the fastest convnet implementations available in the market.
- Layering Architecture and Implementation: The definitions of the model are written using the Protocol Buffer Language in the form of configuration files. Network architecture uses the directed acyclic graph approach. When the model is instantiated, it reserves exact memory as per the model requirement. Switching from a CPU based environment to a GPU environment requires a single function call.
- Test Coverage: Every module in it is tested and its open-source project does not allow any module commit without the corresponding tests thus allowing rapid improvements and codebase refactoring. Thus, this increases the maintainability of it, relatively free of bugs/defects.
- Python and MATLAB Support in Layering: Provides an interface and ease of usage with the existing research framework used by the scientific institutions. Both languages can be used for network construction and input classification. Python in Layering also allows the usage of the solver module for developing new training techniques and easy usage.
- Previously Trained Models Used as Reference: It provides reference models for research and scientific projects like the landmark ImageNet trained models etc. Thus, it provides a common software component that can be extended for quick progress in developing model architectures for real-world applications.
It is different from the other contemporary CNN frameworks in the following:
- The implementation is mostly C++ based so it is easily integrable into the existing C++ systems and industry common interfaces. Also, the CPU mode removes the barrier for the need of a specialized hardware platform for model deployment and experiments once the model is trained.
- The Reference models are provided off-the-shelve for quick experimentation with state of art results. Thus, it reduces the relearning costs.
Conclusion
Caffe Deep Learning Framework is continuously evolving as it is open-source and well documented. It’s Github repository has been forked by many developers. Thus, there are many significant changes been contributed back to it. Recently Caffe 2 has been developed which is integrated with the PyTorch deep learning GitHub repository.
Recommended Articles
This is a guide to the Caffe Deep Learning. Here we discuss the Introduction and Caffe Deep Learning framework along with the benefits of Caffe Deep Learning. You may also have a look at the following articles to learn more –
