Updated February 15, 2023
Introduction to XPath ID
XPath ID is a unique key that cannot be used for more than one element in the relative path and position of elements. So it is used when it involves multiple parts in a similar Xpath. It is used to get the data in the XML file and to traverse attributes or elements in the XML file. The Xpath id is used differently to fetch the relevant data from the XML document. A few elements involved with Xpath id are path expressions, structure definitions, and standard functions.
Xpath id is one of the essential elements in the XSLT function, and it has the data to work on XSLT files as the world web consortium recommends. The standard functions of Xpath are numerical values, string values, date comparison, time comparison, QName manipulation, node evaluation, boolean expression, and sequence manipulation. Hence it has a well-defined library that holds all types of data. For example, the expression in a powerful path is used to display the available node in the XML files and explains every single value like text, attributes, comments, document nodes, namespace, processing information, and all related elements.

How to Use Xpath ID?
When working with Xpath id, the following data should be considered. XSLT standard should be followed in Xpath as it is an essential component in the web space. In turn, the XSLT doesn’t support without Xpath as it is the basis of Xpointer and Xquery. The expression in Xpath explains the structured pattern to choose the set of nodes. These structured patterns follow the XSLT standard to execute transformation in Xpointer to serve the purpose. It specifies different types of nodes which can be used for output execution in the expression of Xpath. The specification of Xpath ID involves seven kinds of nodes, which is the output execution. The important seven values are an element, node, text, attribute, processing instruction, comment, and namespace. Below are the helpful expression and paths to choosing the list of nodes in the XML document.

The node used should hold the descriptive name. from the root node, the selection will be started, and it travels to the current node to match the selected values.
Then it finds the current node and chooses the parent of the current node, after which the attribute is selected.
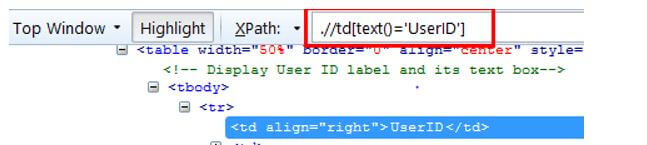
For example, if the user wants to choose a course, then the list of nodes available in the name of the course is selected. Then it chooses all the element and children belongs to the course.
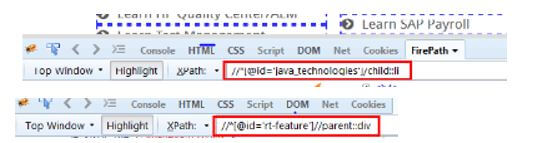
Hence, if any attributes or nodes are given, the related information like parent, present node, and child nodes are selected.
Code:
<xml version = "2.0"?>
<xml course type = "text/xsl" href = "course.xsl"?>
<class>
<course number = "393">
<course name 1> AWS </course name 1>
<course name 2> Azure </course name 2>
<course name 3> Google cloud </course name 3>
<fees> 1000 </fees>
</timing>
<Batch = "slot">
<Batch 1> AWS </Batch 1>
<Batch 2> azure </Batch 2>
<Batch 3> Google cloud </Batch 3>
</timing>
<Morning> AWS </Morning>
<AN> Azure </AN>
<Evening> Google cloud </Evening>
</timing>
</batch>Example of XPath ID
To execute any operation, choose the type of element or click on it to view or locate the element. It is easy to find the element with a name or id, and it is the safest method. Also, it is easy to search the file with a name or id, and it works faster than before. So the locator helps directly with a unique name applied in the application and doesn’t involve any locator.
The application, which works on JavaScript frameworks like React, Angular, and Vue, doesn’t support any proper element in DOM. So it is mandatory to work in test scripts with reliable locators which don’t break the values unless any changes are made, and in any case, it depends on Xpath or CSS. A few methods have browser plugins to produce CSS selectors or Xpath. But they are not adaptive in real-time applications.
Below is an example of XPath id and its name, which works well on combinations.
<input type =”values” font-label=”Email address or contact number” text =”Times new roman” index=”0.5″ place holder=”” name of the person =”email” id=”mail address”
The Xpath id can be used in multiple ways. It can be used with a name or id. The id used is //input [@ id = address’] and also can be used as // * [@ id = ‘mail’]. The name should be used in // input [@ name = ‘mail’] and can be used as //* [@name = ‘mail address’]
By using xpath, a combination of dual locators can also be identified. With the help of xpath values, //* [@id = ‘mail’ or @name = ‘mail’ ], and it is used. Using the index, the path defined should be like //* [@name = ‘mail’] [1], and the value attribute defined should be //input [@name = ‘mail’] [@value = ‘phone’ or ‘mail’].
In the Xpath, the child is defined as “/,” and the example is said as // exc/ a
At times, it is not the direct child and can be located in the other element. In such cases, the forward slash is used to locate the subnode of the XPath, and it is like // exc // a.
Conclusion
The Xpath id is used widely on the web to locate the relevant information of the XML file. Hence the examples, usage, and definition of Xpath id are seen in this article which is simple and effective to use accordingly to the requirements.
Recommended Articles
This is a guide to XPath ID. Here we discuss the introduction, how to use the Xpath ID? and examples for a better understanding. You may also have a look at the following articles to learn more –
