What is ETL?
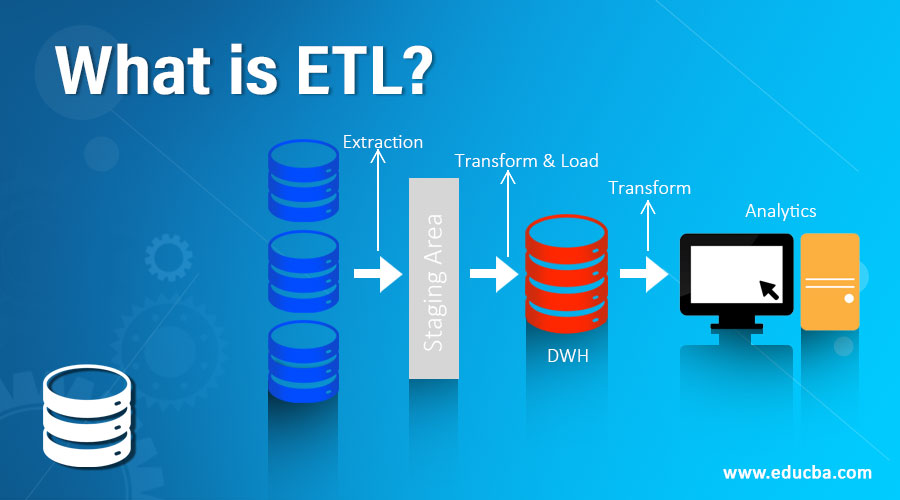
ETL stands for Extract, Transform, and Load. It is a programming tool consisting of several functions that extract the data from specified Relational Database source systems and then transform the acquired data into the desired form by applying various methods. It then loads or writes the resulting data on the target database.
Thus, ETL is a type of Data assimilation process for gathering data from multiple data sources and converting it into one common format to build a Data Warehouse or Database or any Data Storage system, using the three steps as the name suggests, that is, Extract, Transform & Load, where Extract means to collect the data from all the data sources as required, Transform means to convert the data from multiple sources with multiple formats into a single common format that can be used for analysis and reporting purposes. Load means storing all the transformed data in the Database or Data Warehouse system.
ETL Definition
The process in data warehousing extracts data from the database or source systems, transforms it, and places the data into the data warehouse. It combines three database functions, i.e. Extract, Transform, and Load.
- Extract: This is the process of reading data from single or multiple databases where the source can be homogeneous or heterogeneous. All data acquired from different sources are converted into the same data warehouse format and passed to perform the transformation.
- Transform: This is the process of transforming the extracted data into the form required as an output or in the form suitable to place in another database.
- Load: This is the process of writing the desired output into the target database.
Understanding ETL
There are many ETL tools available in the market. But it isn’t easy to choose the appropriate one for your project.
Some ETL tools are described below:
1. Hevo: Hevo an efficient Cloud Data Integration Platform that brings data from different sources, such as Cloud storage, SaaS, and Databases, to the data warehouse in real time. It can handle extensive data and supports both ETL and ELT.
2. QuerySurge: It is a testing solution used to automate the testing of Big Data and Data Warehouses. It improves the data quality and accelerates data delivery cycles. It supports testing on platforms such as Amazon, Cloudera, IBM, and many more.
3. Oracle: Oracle data warehouse is a collection of data, and this database is used to store and retrieve data or information. It helps multiple users to access the same data efficiently. It supports virtualization and allows connecting to remote databases also.
4. Panoply: It is a data warehouse that automates data collection, transformation, and storage. It can connect to any tool like Looker, Chartio, etc.
5. MarkLogic: It is a data warehousing solution that uses various features to make data integration easier and faster. It specifies complex security rules for elements in the documents. It helps to import and export the configuration information. It also allows data replication for disaster recovery.
6. Amazon RedShift: It is a data warehouse tool. It is cost-effective, easy, and simple to use. There is no installation cost, and it enhances the reliability of the data warehouse cluster. In addition, its data centers are fully equipped with climate control.
7. Teradata Corporation: It is the only Massively Parallel Processing commercially available data warehousing tool. It can manage a large amount of data easily and efficiently. It is also as simple and cost-effective as Amazon Redshift. It completely works on parallel architecture.
Working with ETL
When data increases, the time to process it also increases. Sometimes your system gets stuck on one process only, and then you think to improve the performance of ETL.
Here are some tips to enhance your ETL performance:
1. Correct Bottlenecks: Check the number of resources used by the heaviest process and then patiently rewrite the code wherever the bottleneck is to enhance efficiency.
2. Divide Large Tables: You must partition your large tables into physically smaller tables. This will improve the accessing time because the indices tree would be shallow in this case, and quick Metadata operations can be used on data records.
3. Relevant Data only: Data must be collected in bulk, but all data collected must not be helpful. So relevant data must be separated from irrelevant or extraneous data to increase the processing time and enhance the ETL performance.
4. Parallel Processing: You should run a parallel process instead of serial whenever possible to optimize processing and increase efficiency.
5. Loading Data Incrementally: Try to load data incrementally, i.e., loading the changes only and not the full database again. It may seem complicated, but not impossible. It increases efficiency.
6. Caching Data: Accessing cache data is faster and more efficient than accessing data from hard drives, so data must be cached. Cache memory is smaller, so only a small amount of data will be stored.
7. Use Set Logic: Convert the row-based cursor loop into set-based SQL statements in your ETL code. It will increase the processing speed and would enhance efficiency.
Advantages of ETL
Given below are the advantages mentioned:
- Easy to use
- Based on GUI (Graphical User Interface) and offer visual flow
- Better for complex rules and transformations
- Inbuilt error handling functionality
- Advanced Cleansing functions
- Save cost
- Generates higher revenue
- Enhances performance
- Load different targets at the same time
- Performs data transformation as per the need
Required ETL Skills
Given below are the required skills:
- SQL
- Problem-solving capability
- Scripting languages such as Python
- Creativity
- Organizing skills
- Know how to parameterize jobs
- Basic knowledge of ETL tools and software
Why do we Need ETL?
- Helps in making decisions by analyzing data
- It can handle complex problems which traditional databases cannot handle
- It provides a common data repository
- Loads data from different sources into the target database
- The data warehouse automatically updates according to the changes in the data source
- Verify data transformation, calculations, and aggregation rules
- Compares source and target systems data
- Improves productivity
ETL Scope
ETL has a bright future as data is expanding exponentially; hence, job opportunities for ETL professionals are also increasing regularly. A person can have a great career as an ETL developer. Top MNCs like Volkswagen, IBM, Deloitte, and many more are working on ETL projects and therefore require ETL professionals on a large scale.
How will this Technology help you in Career Growth?
The average salary of an ETL developer is about $127,135 a year in the United States. Currently, the salary of an ETL developer ranges from $97,000 to $134,500.
Conclusion
If you want to work with data, you may choose ETL developer or other profiles related to ETL as your profession. Its demand is increasing due to the increase in data. So people interested in databases and data warehousing techniques must learn ETL.
Recommended Articles
This has been a guide to What is ETL? Here we discussed ETL’s basic concepts, needs, scope, required skills, and advantages. You can also go through our other suggested articles to learn more –
