
Introduction to Text to Speech in Python
The following article provides an outline for Text to Speech in Python. The most preferred method of communication is speech. Even in this technology era apart from the technology elements around us, the major item is speech which allows communication between different sources. So, from a technology aspect, it’s a necessity to convert the speech elements into text. To make this process of conversion from a speech element into a text element the consideration aspect is speech recognition technology. The speech recognition technology allows the ability to recognize speech items. Multiple ways and techniques are available in the market corresponding to the speech recognition systems and moreover, several real-like applications are present corresponding to speech recognition.
Syntax:
Object_name = SpeechRecogonition.Recognizer()The above code is the key syntax position to be assed. It explains the process of object creation through the Recognizer class of speech recognition objects.
How to Convert Text to Speech in Python?
The method of speech recognition in python happens in the below ways. The ways are the steps or the technical algorithm which could be involved for speech recognition conversion. Moreover, these are the step-by-step process of speech recognition. These step by steps helps to set the speech recognition process.
- The process of importing the corresponding libraries is a very key aspect. Here the speech recognition libraries are imported. This speech recognition is imported is useful in setting the corresponding methods associated to the speech recognition process. Some of the famous speech recognition libraries in the market are SpeechRecogoition library from the pyspace library. These libraries set the remaining tone of operations for setting the speech recognition to happen in python code.
- Next is the most important step. This step is responsible for setting the python object for helping to make the recognition process happen. This step is named as object-level initialization process. The class used here is the recognizer class which comes under the speech recognition process. So the process is to initialize the recognizer class to pick up the recolonize process to happen. The speech recognition library used by us here is google speech recognition.
- Let’s look at the various file formats supported by the speech recognition process. So the google library supports various input formats of speech. These formats are mentioned below. Wav format a lossless audio format, AIFF, AIFF-C ,FLAG. These are among the key types supported for this process of speech recognition briefly.
- The audio clip has to be verified to determine the type of word used in the speech to confirm whether the conversion happens exactly as needed.
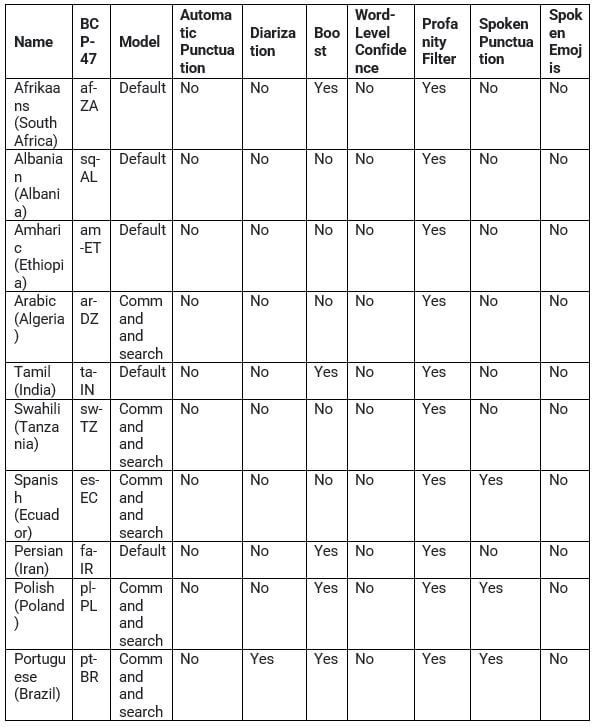
- The default recognition language of speech recognition software is English. With English being the default language used it supports various other languages of speech recognition too. The below-listed table below mentions some of the most famous languages supported by speech recognition software support. The below table mentions only some languages in it but googles search recognition software support several other languages.
Example of Text to Speech in Python
Given below is the example mentioned:
Code:
#import library
import speech_recognition as Speech_item
# The recogonizer class is initialized at the below code.
recogonizer_class = Speech_item.Recognizer()
#the audio file is mentioned here in the below location
with Speech_item.AudioFile('input.wav') as input_source:
retrived_audio = recogonizer_class.listen(input_source)
# The method of recogonize will involve an error item when the expected value in the audio file is not found
# using google speech recognition
Extracted_text_value = recogonizer_class.recognize_google(retrived_audio)
print('Audi converion')
print('Extracted_text_value')
except:
print('Exception occured')Output:

Explanation:
- The first item in the above-given code is the process of declaring the corresponding libraries. This is the most important step. In the case of this problem the speech recognition library of google is been declared. This is the foremost and the critical step. Next, an object is declared for this item using the recognized method. In our above given example, the recognized class is declared by the name recogonizer_class. The next thing to be noted is the audio sample is gathered into a variable. The audio sample is gathered by the means of listening to the method in the recognizer class.
- The listen method is useful in converting the voice item into a python understandable item into a variable. In our example, the values are stored in the retrieved audio variable. So the retrieved audio variable holds the expected value. This variable is then passed to the recognized google class.
- This is the most important section. The recognizer google is again a method of speech recognition class. It can be again retrieved from the class of speech recognition by means of the object item declared. The object item, in this case, is the recognizer object named as recognizer class. As a result of this operation, the out text values get filled up in the extracted text value variable. So this variable holds the output now. The last process now remaining is the process of printing the extracted output. This is done next. This is the last process where the extracted output will be printed onto the console. We can notice the output in the output section screenshot.
Conclusion
The above-given article clearly explains the various ways through which the speech recognition can be performed in the google recognition system. A suitable example is also shared for the same with the output snapshots attached.
Recommended Articles
This is a guide to Text to Speech in Python. Here we discuss the introduction, how to convert text to speech in Python? and an example. You may also have a look at the following articles to learn more –

