Updated June 28, 2023

Introduction to SparkContext
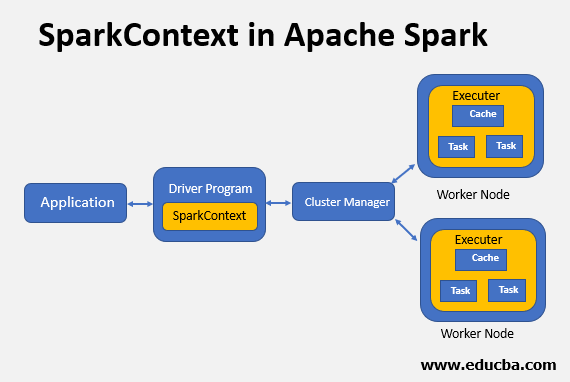
Generating the Spark context is the primary and necessary step in any SparkContext for the Spark driver. On the worker, the nodes and the operations inside the executors are run by the driver program. The gateway point of Spark in Apache functionality is the Spark context. The driver program initializes and generates the SparkContext as soon as we run any Spark application by passing it through the Spark context. The driver application of Spark has parameters, and it contains the main function where the SparkContext gets initiated.
Syntax for Apache SparkContext:
from pyspark import SparkContext
sc = SparkContext("local", "First App")How Apache SparkContext is Created?
Initially, SparkConf should be made if one has to create SparkContext. The parameter for the configuration of Sparkconf is our Spark driver application will pass to SparkContext. The parameters from these define the properties of driver applications in Spark.
And the other few are utilized in allocating the cluster resources, which are the memory size, and the number the cores on the worker nodes used by executors run by Spark. To put it simply, the Spark context helps in guiding the accession of the Spark cluster.
Parameters:
| Profiler_cls | Used to do the profiling, which is called a custom profiler, and the default is pyspark. profiler.BasicProfiler. |
| JSC | An instance of the Java Spark context. |
| Gateway | Install a new JVM or otherwise use the present or existing JVM. |
| Serializer | Serialiser of RDD. |
| batchSize | The number of Python objects showcased as a single object in Java. To disable batching, set 1. To automatically choose the batch size based on object sizes, set 0. or to use an unlimited batch size, set -1. |
| Environment | Worker nodes environment variables. |
| pyFiles | PythonPath has an add-on of .zip or .py files to send to the cluster. |
| SparkHome | Directory for Spark installation. |
| appName | The job name of particulars. |
| Master | It connects the cluster URL. |
| Conf | To set all the Spark properties, an object of L, that is, Sparkconf, spark configuration is used. |
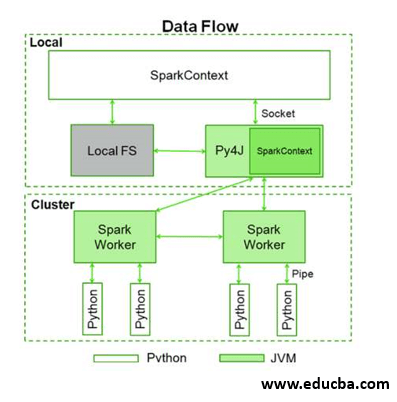
Below represents the data flow of the Spark context:
The Spark context takes Py4J to use and launches a Java virtual machine, further creating a Java Spark context. PySpark has the context in Spark available as sc which is the default. That is the reason why creating a new Spark context will not work.
Code:
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)Example:
Code:
package com.dataflair.spark
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Word_Count {
def main(args: Array[String]) {
//Configuration for spark context is set and created
val conf = new SparkConf()
.setAppName("WordCount")
// An object for Spark context is created
val sc = new SparkContext(conf)
//Check whether sufficient params are supplied
if (args.length < 2) {
println("Usage: ScalaWordCount <input> <output>")
System.exit(1)
}
//Read file and create RDD
val rawData = sc.textFile(args(0))
//Using flatMap operation, convert the lines into words
val words = rawData.flatMap(line => line.split(" "))
//Using map and reduceByKey operation, count the individual words
val wordCount = words.map(word => (word, 1)).reduceByKey(_ + _)
// result is saved
wordCount.saveAsTextFile(args(1))
// spark context is stopped
sc.stop
}}Output:
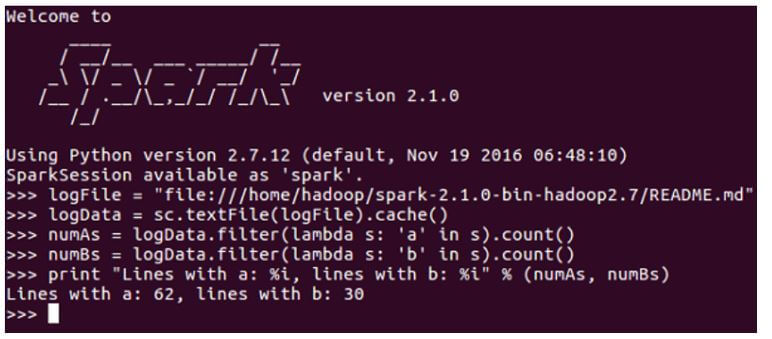
Conclusion
To sum up, Spark helps to simplify the challenging and computationally intensive task of processing high volumes of real-time or archived data, both structured and unstructured, seamlessly integrating relevant complex capabilities such as machine learning and graph algorithms. Spark brings Big Data processing to the masses. It is an entry point to the Spark functionality. Thus, it acts as a backbone.
Recommended Articles
This is a guide to SparkContext. Here we discuss the introduction to SparkContext and how Apache SparkContext is created with respective examples. You may also have a look at the following articles to learn more –
