Updated June 28, 2023
Difference Between Spark vs Impala
This is an outline of Spark vs Impala. As we live in a data-driven world and the big data industry is growing rapidly, it has changed how data is usually conceived. The tools and techniques associated with it that are also upgrading themselves. Various tools available in the market have made data engineers’ lives easy by providing fast, interactive analytical tools. However, the question that often comes to mind is which of these tools is better? We have two great warriors in this Big Data war, Spark and Impala. Let’s find out which one is better.
When we start talking about data analytics tools having a fast and interactive mode of data processing, two names that come to mind are Apache Spark and Impala. These are two of the most commonly-used tools in big data analytics. Before starting a face-off difference between Spark and Impala, let us learn about them.
What is Impala?
Impala is an MPP (Massive Parallel Processing) SQL query engine for processing huge volumes of data stored in a computer cluster running Apache Hadoop. It is a freeware software that is written in C++/Java. It provides low latency and better performance than other Hadoop SQL engines. The project was announced in 2012 and was inspired by the open-source equivalent of Google F1; later, Cloudera developed it.
In other words, Impala is the SQL engine giving an RDBMS-like experience that provides the fastest way to access data stored in the Hadoop Cluster.
Features of Impala:
- It can query many file formats such as Parquet, Avro, Text, etc.
- It supports data stored in HDFS, HBase, and Amazon S3.
- It supports multiple compression codecs: Snappy, Gzip, etc.
- It allows using UDFs and UDAFs.
- It allows concurrent queries by multi-user.
- It caches frequently accessed data in memory.
- It computes statistics (with COMPUTE STATS).
- It provides window functions for more advanced SQL analytic capabilities (since version 2.0).
- It allows external joins and aggregation enabling operations to spill to disk if their internal state exceeds the memory size.
- It enables some OLAP functions (ROLLUP, GROUPING SET)
What is Spark?
Spark was introduced in March 2014. It officially replaces Shark, developed to use Hive queries in the Spark framework but has limited integration with Spark programs. It was initially developed at the Amp Lab of the University of California in Berkley and was later donated to Apache Software Foundation, which now maintains it. “Spark conveniently thin the boundaries between RDDs and relational tables.” Spark is a fast and general engine for big data processing, with built-in support for other Spark libraries like Spark Streaming, Graph X, and Mila.
Features of Spark:
- It supports multiple file formats such as Parquet, Avro, JSON, etc.
- It supports multiple file formats such as Parquet, Avro, Text, JSON, and ORC.
- It supports data stored in HDFS and Amazon S3.
- It supports classical Hadoop codecs such as gzip, snappy and Lzo.
- It provides security through authentication via a “shared secret.”
- Keeping event logs.
- It supports UDFs.
- It supports concurrent queries and manages the allocation of memory to the jobs.
- It supports caching data in memory using a Schema RDD columnar format.
- It supports nested structures.
Head-to-Head Comparison Between Spark vs Impala
Below are the top 7 comparisons between Spark vs Impala:
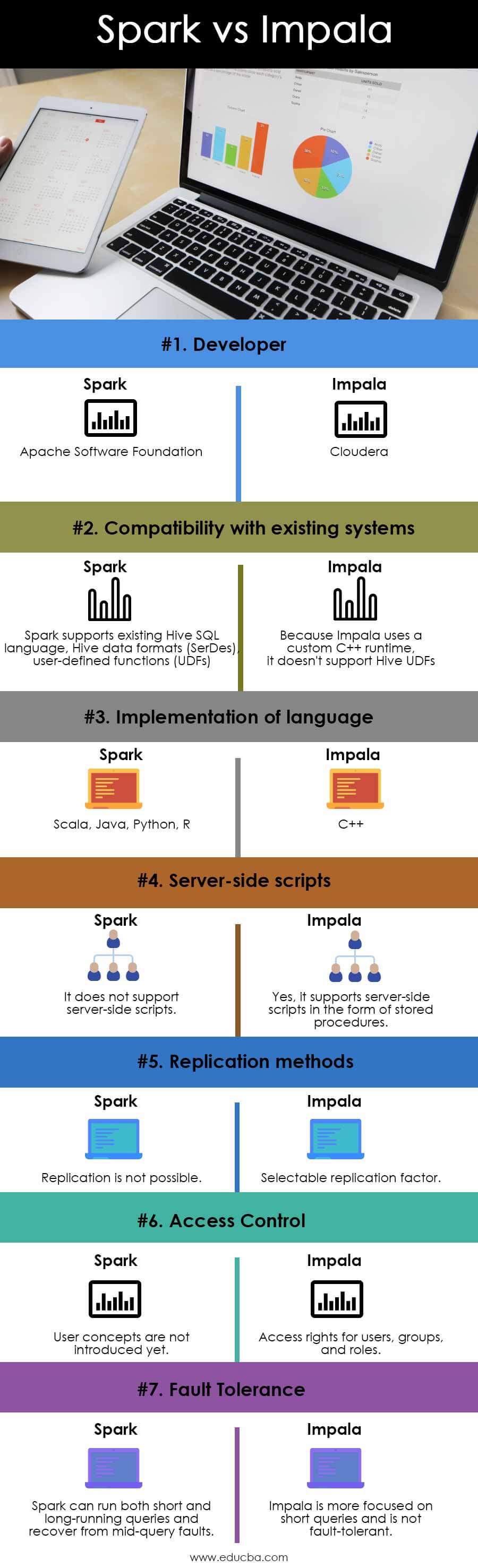
Key Differences Between Spark vs Impala
Below are the points that describe the key differences between Spark vs Impala.
- Use Case: I have taken sample data of 30 GB size. This data is in the Hive database. We will perform analytics (aggregation and distinct operations) on this data and compare how Spark performs concerning Impala.
- Cluster configuration: I have used the same cluster for Spark and Impala. It’s a 20-node cluster with 252 GB of RAM; each node has 48 cores.
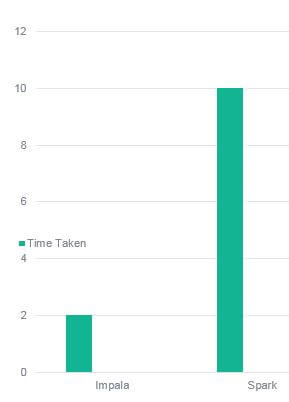
- Spark: I have written a spark application using Hive context to fetch the data from Hive, and then used SQL on top of it to calculate the result and store it in HDFS. Spark gives a much-improved performance with cached data. Hence I have cached the intermediate data set and reused it. The best-case performance for the Spark query was 5 Mins.
- Impala: Simple Impala script consisted of two queries (One for aggregation and one for distinct) and was executed. The best-case performance for Impala Query was 2 Mins.
Impala executes queries much faster than Spark. When given just enough memory to spark to execute, it was 5x times slower than Impala Query’s.
Comparison Table of Spark vs Impala
Below is the comparison table between Spark vs Impala:
|
Basis of Comparison |
Spark |
Impala |
| Developer | Apache Software Foundation | Cloudera |
| Compatibility with Existing Systems | Spark supports existing Hive SQL language, Hive data formats (SerDes), and user-defined functions (UDFs). | Because Impala uses a custom C++ runtime, it doesn’t support Hive UDFs. |
| Implementation of Language | Scala, Java, Python, R | C++ |
| Server-side Scripts | It does not support server-side scripts. | Yes, it supports server-side scripts in the form of stored procedures. |
| Replication Methods | Replication is not possible. | Selectable replication factor. |
| Access Control | User concepts are not introduced yet. | Access rights for users, groups, and roles. |
| Fault Tolerance | Spark can run both short and long-running queries and recover from mid-query faults. | Impala is more focused on short queries and is not fault-tolerant. |
Conclusion
The above results prove that Impala is faster than Spark but is just used for ad-hoc querying options for Analytics. Impala doesn’t support complex functionalities like Spark. Impala is not fault-tolerant; if the query fails in the middle of execution, Impala cannot rerun that part and give out the result. Spark is preferred in batched ETL applications where reliability is more important than the query’s latency.
On the other hand, if the application is not that complex or critical, Impala can run multiple queries batched together for ETL as a replacement for Hive. I hope this article about Spark vs Impala helps you choose between these two warriors in the Big Data game.
Recommended Articles
We hope that this EDUCBA information on “Spark vs Impala” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
